Slice sampling
Slice sampling is a type of Markov chain Monte Carlo algorithm for pseudo-random number sampling, i.e. for drawing random samples from a statistical distribution. The method is based on the observation that to sample a random variable one can sample uniformly from the region under the graph of its density function.[1][2][3]
Motivation
Suppose you want to sample some random variable X with distribution f(x). Suppose that the following is the graph of f(x). The height of f(x) corresponds to the likelihood at that point.
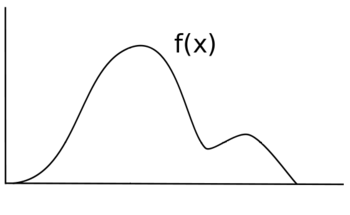
If you were to uniformly sample X, each value would have the same likelihood of being sampled, and your distribution would be of the form f(x)=y for some y value instead of some non-uniform function f(x). Instead of the original black line, your new distribution would look more like the blue line.
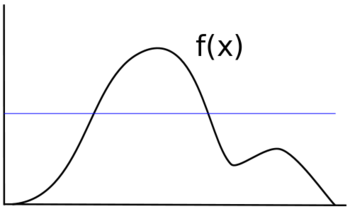
In order to sample X in a manner which will retain the distribution f(x), some sampling technique must be used which takes into account the varied likelihoods for each range of f(x).
Method
Slice sampling, in its simplest form, samples uniformly from underneath the curve f(x) without the need to reject any points, as follows:
- Choose a starting value x0 for which f(x0)>0.
- Sample a y value uniformly between 0 and f(x0).
- Draw a horizontal line across the curve at this y position.
- Sample a point (x,y) from the line segments within the curve.
- Repeat from step 2 using the new x value.
The motivation here is that one way to sample a point uniformly from within an arbitrary curve is first to draw thin uniform-height horizontal slices across the whole curve. Then, we can sample a point within the curve by randomly selecting a slice that falls at or below the curve at the x-position from the previous iteration, then randomly picking an x-position somewhere along the slice. By using the x-position from the previous iteration of the algorithm, in the long run we select slices with probabilities proportional to the lengths of their segments within the curve.
Generally, the trickiest part of this algorithm is finding the bounds of the horizontal slice, which involves inverting the function describing the distribution being sampled from. This is especially problematic for multi-modal distributions, where the slice may consist of multiple discontiguous parts. It is often possible to use a form of rejection sampling to overcome this, where we sample from a larger slice that is known to include the desired slice in question, and then discard points outside of the desired slice.
Note also that this algorithm can be used to sample from the area under any curve, regardless of whether the function integrates to 1. In fact, scaling a function by a constant has no effect on the sampled x-positions. This means that the algorithm can be used to sample from a distribution whose probability density function is only known up to a constant (i.e. whose normalizing constant is unknown), which is common in computational statistics.
Implementation
Slice sampling gets its name from the first step: defining a slice by sampling from an auxiliary variable . This variable is sampled from , where is either the probability density function (pdf) of X or is at least proportional to its pdf. This defines a slice of X where . In other words, we are now looking at a region of X where the probability density is at least . Then the next value of X is sampled uniformly from this slice. A new value of is sampled, then X, and so on. This can be visualized as alternatively sampling the y-position and then the x-position of points under pdf, thus the Xs are from the desired distribution. The values have no particular consequences or interpretations outside of their usefulness for the procedure.

![[0,f(x)]](../I/m/4aab098c7371ce16e69a2e14b79228f7dc47e547.svg)


If both the pdf and its inverse are available, and the distribution is unimodal, then finding the slice and sampling from it are simple. If not, a stepping-out procedure can be used to find a region whose endpoints fall outside the slice. Then, a sample can be drawn from the slice using rejection sampling. Various procedures for this are described in detail by Neal.[2]
Note that, in contrast to many available methods for generating random numbers from non-uniform distributions, random variates generated directly by this approach will exhibit serial statistical dependence. This is because to draw the next sample, we define the slice based on the value of f(x) for the current sample.
Compared to Other Methods
Slice sampling is a Markov chain method and as such serves the same purpose as Gibbs sampling and Metropolis. Unlike Metropolis, there is no need to manually tune the candidate function or candidate standard deviation.
Recall that Metropolis is sensitive to step size. If the step size is too small random walk causes slow decorrelation. If the step size is too large there is great inefficiency due to a high rejection rate.
In contrast to Metropolis, slice sampling automatically adjusts the step size to match the local shape of the density function. Implementation is arguably easier and more efficient than Gibbs sampling or simple Metropolis updates.
Note that, in contrast to many available methods for generating random numbers from non-uniform distributions, random variates generated directly by this approach will exhibit serial statistical dependence. In other words, not all points have the same independent likelihood of selection. This is because to draw the next sample, we define the slice based on the value of f(x) for the current sample. However, the generated are markovian, and are therefore expected to converge to the correct distribution in long run.
Slice Sampling requires that the distribution to be sampled be evaluable. One way to relax this requirement is to substitute an evaluable distribution which is proportional to the true unevaluable distribution.
Univariate Case
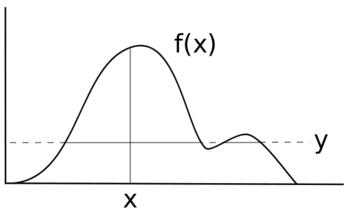
To sample a random variable X with density f(x) we introduce an auxiliary variable Y and iterate as follows:
- Given a sample x we choose y uniformly at random from the interval [0, f(x)];
- given y we choose x uniformly at random from the set .
- The sample of x is obtained by ignoring the y values.

Our auxiliary variable Y represents a horizontal "slice" of the distribution. The rest of each iteration is dedicated to sampling an x value from the slice which is representative of the density of the region being considered.
In practice, sampling from a horizontal slice of a multimodal distribution is difficult. There is a tension between obtaining a large sampling region and thereby making possible large moves in the distribution space, and obtaining a simpler sampling region to increase efficiency. One option for simplifying this process is regional expansion and contraction.
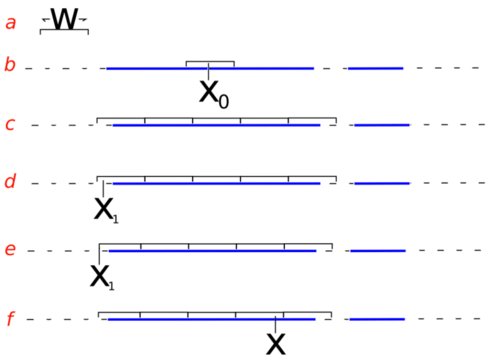
- First, a width parameter w is used to define the area containing the given x value. Each endpoint of this area is tested to see if it lies outside the given slice. If not, the region is extended in the appropriate direction(s) by w until the end both endpoints lie outside the slice.
- A candidate sample is selected uniformly from within this region. If the candidate sample lies inside of the slice, then it is accepted as the new sample. If it lies outside of the slice, the candidate point becomes the new boundary for the region. A new candidate sample is taken uniformly. The process repeats until the candidate sample is within the slice. (See diagram for a visual example).



Slice-within-Gibbs sampling
In a Gibbs sampler, one needs to draw efficiently from all the full-conditional distributions. When sampling from a full-conditional density is not easy, a single iteration of slice sampling or the Metropolis-Hastings algorithm can be used within-Gibbs to sample from the variable in question. If the full-conditional density is log-concave, a more efficient alternative is the application of adaptive rejection sampling (ARS) methods.[4][5][6] When the ARS techniques cannot be applied (since the full-conditional is non-log-concave), the adaptive rejection Metropolis sampling algorithms are often employed.[7][8][9]
Multivariate Methods
Treating each variable independently
Single variable slice sampling can be used in the multivariate case by sampling each variable in turn repeatedly, as in Gibbs sampling. To do so requires that we can compute, for each component a function that is proportional to .


To prevent random walk behavior, overrelaxation methods can be used to update each variable in turn. Overrelaxation chooses a new value on the opposite side of the mode from the current value, as opposed to choosing a new independent value from the distribution as done in Gibbs.
Hyperrectangle slice sampling
This method adapts the univariate algorithm to the multivariate case by substituting a hyperrectangle for the one-dimensional w region used in the original. The hyperrectangle H is initialized to a random position over the slice. H is then shrunken as points from it are rejected.
Reflective slice sampling
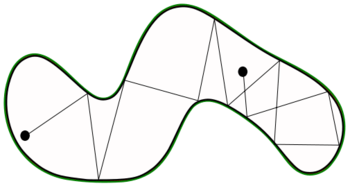
Reflective slice sampling is a technique to suppress random walk behavior in which the successive candidate samples of distribution f(x) are kept within the bounds of the slice by "reflecting" the direction of sampling inward toward the slice once the boundary has been hit.
In this graphical representation of reflective sampling, the shape indicates the bounds of a sampling slice. The dots indicate start and stopping points of a sampling walk. When the samples hit the bounds of the slice, the direction of sampling is "reflected" back into the slice.
Example
Let us consider a single variable example. Suppose our true distribution . So:


- We first draw a uniform random value y from the range of f(x) in order to define our slice(es). Suppose y=0.01.
- Next, we set our width parameter w which we will use to expand our region of consideration. Suppose w=2.
- Next, we need an initial value for x. We draw x from the uniform distribution within the domain of f(x) at our current y. Suppose x=2.
- Because x=2 and w=2, our current region of interest is bounded by (1,3).
- Now, each endpoint of this area is tested to see if it lies outside the given slice. Our right bound lies outside our slice, but the left value does not. We expand the left bound by adding w to it until it extends past the limit of the slice. After this process, the new bounds of our region of interest are (-4,3).
- Next, we take a uniform sample within (-4,3). Suppose this sample yields x=-3.9. Though this sample is within our region of interest, it does not lie within our slice, so we modify the left bound of our region of interest to this point. Now we take a uniform sample from (-3.9,3). This time our sample yields x=1, which is within our slice, and thus is our accepted sample. Had our new x not been within our slice, we would continue the shrinking/resampling process until a valid x within bounds is found.
Another Example
To sample from the normal distribution we first choose an initial x—say 0. After each sample of x we choose y uniformly at random from , which is bounded the pdf of . After each y sample we choose x uniformly at random from where . This is the slice where .

![(0,e^{{-x^{2}/2}}/{\sqrt {2\pi }}]](../I/m/781bcb189d0d28e28cbaa780f87e24924df23b51.svg)
![[-\alpha ,\alpha ]](../I/m/d6aaee8f359da96b8f4b1c02a27cbdadf9adf313.svg)


An implementation in the Macsyma language is:
slice(x):=block([y,alpha],
y:random( exp(-x^2/2.0)/sqrt(2.0*dfloat(%pi))),
alpha:sqrt(-2.0*ln(y*sqrt(2.0*dfloat(%pi)))),
x:signum(random())*random(alpha)
);
See also
References
- ↑ Damlen, P., Wakefield, J., & Walker, S. (1999). Gibbs sampling for Bayesian non‐conjugate and hierarchical models by using auxiliary variables. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 61(2), 331-344.Chicago
- 1 2 Neal, Radford M. (2003). "Slice Sampling". Annals of Statistics. 31 (3): 705–767. MR 1994729. Zbl 1051.65007. doi:10.1214/aos/1056562461.
- ↑ Bishop, Christopher (2006). "11.4: Slice sampling". Pattern Recognition and Machine Learning. Springer. ISBN 0387310738.
- ↑ Gilks, W. R.; Wild, P. (1992-01-01). "Adaptive Rejection Sampling for Gibbs Sampling". Journal of the Royal Statistical Society. Series C (Applied Statistics). 41 (2): 337–348. JSTOR 2347565. doi:10.2307/2347565.
- ↑ Hörmann, Wolfgang (1995-06-01). "A Rejection Technique for Sampling from T-concave Distributions". ACM Trans. Math. Softw. 21 (2): 182–193. ISSN 0098-3500. doi:10.1145/203082.203089.
- ↑ Martino, Luca; Míguez, Joaquín (2010-08-25). "A generalization of the adaptive rejection sampling algorithm". Statistics and Computing. 21 (4): 633–647. ISSN 0960-3174. doi:10.1007/s11222-010-9197-9.
- ↑ Gilks, W. R.; Best, N. G.; Tan, K. K. C. (1995-01-01). "Adaptive Rejection Metropolis Sampling within Gibbs Sampling". Journal of the Royal Statistical Society. Series C (Applied Statistics). 44 (4): 455–472. JSTOR 2986138. doi:10.2307/2986138.
- ↑ Meyer, Renate; Cai, Bo; Perron, François (2008-03-15). "Adaptive rejection Metropolis sampling using Lagrange interpolation polynomials of degree 2". Computational Statistics & Data Analysis. 52 (7): 3408–3423. doi:10.1016/j.csda.2008.01.005.
- ↑ Martino, L.; Read, J.; Luengo, D. (2015-06-01). "Independent Doubly Adaptive Rejection Metropolis Sampling Within Gibbs Sampling". IEEE Transactions on Signal Processing. 63 (12): 3123–3138. ISSN 1053-587X. doi:10.1109/TSP.2015.2420537.