Self-organizing list
A self-organizing list is a list that reorders its elements based on some self-organizing heuristic to improve average access time. The aim of a self-organizing list is to improve efficiency of linear search by moving more frequently accessed items towards the head of the list. A self-organizing list achieves near constant time for element access in the best case. A self-organizing list uses a reorganizing algorithm to adapt to various query distributions at runtime.
History
The concept of self-organizing lists has its roots in the idea of activity organization [1] of records in files stored on disks or tapes. One frequently cited discussion of self-organizing files and lists is Knuth .[2] John McCabe has the first algorithmic complexity analyses of the Move-to-Front (MTF) strategy where an item is moved to the front of the list after it is accessed. .[3] He analyzed the average time needed for randomly ordered list to get in optimal order. The optimal ordering of a list is the one in which items are ordered in the list by the probability with which they will be needed, with the most accessed item first. The optimal ordering may not be known in advance, and may also change over time. McCabe introduced the transposition strategy in which an accessed item is exchanged with the item in front of it in the list. He made the conjecture that transposition worked at least as well in the average case as MTF in approaching the optimal ordering of records in the limit. This conjecture was later proved by Rivest.[4] McCabe also noted that with either the transposition or MTF heuristic, the optimal ordering of records would be approached even if the heuristic was only applied every Nth access, and that a value of N might be chosen that would reflect the relative cost of relocating records with the value of approaching the optimal ordering more quickly. Further improvements were made, and algorithms suggested by researchers including: Rivest, Tenenbaum and Nemes, Knuth, and Bentley and McGeoch (e.g. Worst-case analyses for self-organizing sequential search heuristics).
Introduction
The simplest implementation of a self-organizing list is as a linked list and thus while being efficient in random node inserting and memory allocation, suffers from inefficient accesses to random nodes. A self-organizing list reduces the inefficiency by dynamically rearranging the nodes in the list based on access frequency.
Inefficiency of linked list traversals
If a particular node is to be searched for in the list, each node in the list must be sequentially compared till the desired node is reached. In a linked list, retrieving the nth element is an O(n) operation. This is highly inefficient when compared to an array for example, where accessing the nth element is an O(1) operation.
Efficiency of self-organizing lists
A self organizing list rearranges the nodes keeping the most frequently accessed ones at the head of the list. Generally, in a particular query, the chances of accessing a node which has been accessed many times before are higher than the chances of accessing a node which historically has not been so frequently accessed. As a result, keeping the commonly accessed nodes at the head of the list results in reducing the number of comparisons required in an average case to reach the desired node. This leads to better efficiency and generally reduced query times.
Implementation of a self-organizing list
The implementation and methods of a self-organizing list are identical to those for a standard linked list. The linked list and the self-organizing list differ only in terms of the organization of the nodes; the interface remains the same.
Analysis of Running Times for Access/ Search in a List
Average Case
It can be shown that in the average case, the time required to a search on a self-organizing list of size n is

where p(i) is the probability of accessing the ith element in the list, thus also called the access probability. If the access probability of each element is the same (i.e. p(1) = p(2) = p(3) = ... = p(n) = 1/n) then the ordering of the elements is irrelevant and the average time complexity is given by

and T(n) does not depend on the individual access probabilities of the elements in the list in this case.
However, in the case of searches on lists with non uniform record access probabilities (i.e. those lists in which the probability of accessing one element is different from another), the average time complexity can be reduced drastically by proper positioning of the elements contained in the list.
This is done by pairing smaller i with larger access probabilities so as to reduce the overall average time complexity.
This may be demonstrated as follows:
Given List: A(0.1), B(0.1), C(0.3), D(0.1), E(0.4)
Without rearranging, average search time required is:

Now suppose the nodes are rearranged so that those nodes with highest probability of access are placed closest to the front so that the rearranged list is now:
E(0.4), C(0.3), D(0.1), A(0.1), B(0.1)
Here, average search time is:

Thus the average time required for searching in an organized list is (in this case) around 40% less than the time required to search a randomly arranged list.
This is the concept of the self-organized list in that the average speed of data retrieval is increased by rearranging the nodes according to access frequency.
Worst Case
In the worst case, the element to be located is at the very end of the list be it a normal list or a self-organized one and thus n comparisons must be made to reach it. Therefore, the worst case running time of a linear search on the list is O(n) independent of the type of list used. Note that the expression for the average search time in the previous section is a probabilistic one. Keeping the commonly accessed elements at the head of the list simply reduces the probability of the worst case occurring but does not eliminate it completely. Even in a self-organizing list, if a lowest access probability element (obviously located at the end of the list) is to be accessed, the entire list must be traversed completely to retrieve it. This is the worst case search.
Best Case
In the best case, the node to be searched is one which has been commonly accessed and has thus been identified by the list and kept at the head. This will result in a near constant time operation. In big-oh notation, in the best case, accessing an element is an O(1) operation.
Techniques for Rearranging Nodes
While ordering the elements in the list, the access probabilities of the elements are not generally known in advance. This has led to the development of various heuristics to approximate optimal behavior. The basic heuristics used to reorder the elements in the list are:
Move to Front Method (MTF)
This technique moves the element which is accessed to the head of the list. This has the advantage of being easily implemented and requiring no extra memory. This heuristic also adapts quickly to rapid changes in the query distribution. On the other hand, this method may prioritize infrequently accessed nodes-for example, if an uncommon node is accessed even once, it is moved to the head of the list and given maximum priority even if it is not going to be accessed frequently in the future. These 'over rewarded' nodes destroy the optimal ordering of the list and lead to slower access times for commonly accessed elements. Another disadvantage is that this method may become too flexible leading to access patterns that change too rapidly. This means that due to the very short memories of access patterns even an optimal arrangement of the list can be disturbed immediately by accessing an infrequent node in the list.

If the 5th node is selected, it is moved to the front
At the t-th item selection:
if item i is selected:
move item i to head of the list
Count Method
In this technique, the number of times each node was searched for is counted i.e. every node keeps a separate counter variable which is incremented every time it is called. The nodes are then rearranged according to decreasing count. Thus, the nodes of highest count i.e. most frequently accessed are kept at the head of the list. The primary advantage of this technique is that it generally is more realistic in representing the actual access pattern. However, there is an added memory requirement, that of maintaining a counter variable for each node in the list. Also, this technique does not adapt quickly to rapid changes in the access patterns. For example: if the count of the head element say A is 100 and for any node after it say B is 40, then even if B becomes the new most commonly accessed element, it must still be accessed at least (100 - 40 = 60) times before it can become the head element and thus make the list ordering optimal.
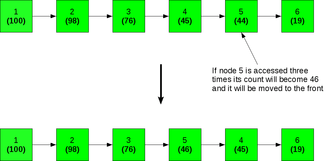
If the 5th node in the list is searched for twice, it will be swapped with the 4th
init: count(i) = 0 for each item i
At t-th item selection:
if item i is searched:
count(i) = count(i) + 1
rearrange items based on count
Transpose Method
This technique involves swapping an accessed node with its predecessor. Therefore, if any node is accessed, it is swapped with the node in front unless it is the head node, thereby increasing its priority. This algorithm is again easy to implement and space efficient and is more likely to keep frequently accessed nodes at the front of the list. However, the transpose method is more cautious. i.e. it will take many accesses to move the element to the head of the list. This method also does not allow for rapid response to changes in the query distributions on the nodes in the list.
If the 5th node in the list is selected, it will be swapped with the 4th
At the t-th item selection:
if item i is selected:
if i is not the head of list:
swap item i with item (i - 1)
Other Methods
Research has been focused on fusing the above algorithms to achieve better efficiency.[5] Bitner's Algorithm uses MTF initially and then uses transpose method for finer rearrangements. Some algorithms are randomized and try to prevent the over-rewarding of infrequently accessed nodes that may occur in the MTF algorithm. Other techniques involve reorganizing the nodes based on the above algorithms after every n accesses on the list as a whole or after n accesses in a row on a particular node and so on. Some algorithms rearrange the nodes which are accessed based on their proximity to the head node, for example: Swap-With-Parent or Move-To-Parent algorithms. Another class of algorithms are used when the search pattern exhibits a property called locality of reference whereby in a given interval of time, only a smaller subset of the list is probabilistically most likely to be accessed. This is also referred to as dependent access where the probability of the access of a particular element depends on the probability of access of its neighboring elements. Such models are common in real world applications such as database or file systems and memory management and caching. A common framework for algorithms dealing with such dependent environments is to rearrange the list not only based on the record accessed but also on the records near it. This effectively involves reorganizing a sublist of the list to which the record belongs.
Applications of self-organizing lists
Language translators like compilers and interpreters use self-organizing lists to maintain symbol tables during compilation or interpretation of program source code. Currently research is underway to incorporate the self-organizing list data structure in embedded systems to reduce bus transition activity which leads to power dissipation in those circuits. These lists are also used in artificial intelligence and neural networks as well as self-adjusting programs. The algorithms used in self-organizing lists are also used as caching algorithms as in the case of LFU algorithm.
References
- ↑ Becker, J.; Hayes, R.M. (1963), Information Storage and Retrieval: Tools, Elements, Theories, New York: Wiley
- ↑ Knuth, Donald (1998), Sorting and Searching, The Art of Computer Programming, Volume 3 (Second ed.), Addison-Wesley, p. 402, ISBN 0-201-89685-0
- ↑ McCabe, John (1965), "On Serial Files with Relocatable Records", Operations Research, INFORMS, 13 (4): 609–618, doi:10.1287/opre.13.4.609
- ↑ Rivest, Ronald (1976), "On self-organizing sequential search heuristics", Communications of the ACM, 19 (2): 63–67, doi:10.1145/359997.360000
- ↑ http://www.springerlink.com/content/978-3-540-34597-8/#section=508698&page=1&locus=3 Lists on Lists: A Framework for Self Organizing-Lists in Environments with Locality of Reference
- Vlajic, N (2003), Self-Organizing Lists (pdf)
- Self Organization (pdf), 2004
- NIST DADS entry
- A Drozdek, Data Structures and Algorithms in Java Third edition
- Amer, Abdelrehman; B. John Oommen (2006), Lists on Lists: A Framework for Self-organizing Lists in Environments with Locality of Reference (pdf)