Positive and negative predictive values
The positive and negative predictive values (PPV and NPV respectively) are the proportions of positive and negative results in statistics and diagnostic tests that are true positive and true negative results, respectively.[1] The PPV and NPV describe the performance of a diagnostic test or other statistical measure. A high result can be interpreted as indicating the accuracy of such a statistic. The PPV and NPV are not intrinsic to the test; they depend also on the prevalence.[2] The PPV can be derived using Bayes' theorem.
Although sometimes used synonymously, a positive predictive value generally refers to what is established by control groups, while a post-test probability refers to a probability for an individual. Still, if the individual's pre-test probability of the target condition is the same as the prevalence in the control group used to establish the positive predictive value, the two are numerically equal.
In information retrieval, the PPV statistic is often called the precision.
Definition
Positive predictive value
The positive predictive value (PPV) is defined as

where a "true positive" is the event that the test makes a positive prediction, and the subject has a positive result under the gold standard, and a "false positive" is the event that the test makes a positive prediction, and the subject has a negative result under the gold standard.
The PPV can also be computed from sensitivity, specificity, and prevalence:

The complement of the PPV is the false discovery rate (FDR):

Negative predictive value
The negative predictive value is defined as:

where a "true negative" is the event that the test makes a negative prediction, and the subject has a negative result under the gold standard, and a "false negative" is the event that the test makes a negative prediction, and the subject has a positive result under the gold standard.
The NPV can also be computed from sensitivity, specificity, and prevalence:

The complement of the NPV is the false omission rate (FOR):

Relationship
Although sometimes used synonymously, a negative predictive value generally refers to what is established by control groups, while a negative post-test probability rather refers to a probability for an individual. Still, if the individual's pre-test probability of the target condition is the same as the prevalence in the control group used to establish the negative predictive value, then the two are numerically equal.
The following diagram illustrates how the positive predictive value, negative predictive value, sensitivity, and specificity are related.
| True condition | Accuracy (ACC) = Σ True positive + Σ True negative/Σ Total population | |||||
| Total population | Condition positive | Condition negative | Prevalence = Σ Condition positive/Σ Total population | |||
| Predicted condition |
Predicted condition positive |
True positive | False positive (Type I error) |
Positive predictive value (PPV), Precision = Σ True positive/Σ Predicted condition positive | False discovery rate (FDR) = Σ False positive/Σ Predicted condition positive | |
| Predicted condition negative |
False negative (Type II error) |
True negative | False omission rate (FOR) = Σ False negative/Σ Predicted condition negative | Negative predictive value (NPV) = Σ True negative/Σ Predicted condition negative | ||
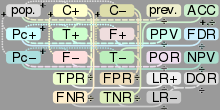
 |
True positive rate (TPR), Recall, Sensitivity, probability of detection = Σ True positive/Σ Condition positive | False positive rate (FPR), Fall-out, probability of false alarm = Σ False positive/Σ Condition negative | Positive likelihood ratio (LR+) = TPR/FPR | Diagnostic odds ratio (DOR) = LR+/LR− | F1 score = 2/1/recall+1/precision | |
| False negative rate (FNR), Miss rate = Σ False negative/Σ Condition positive | True negative rate (TNR), Specificity (SPC) = Σ True negative/Σ Condition negative | Negative likelihood ratio (LR−) = FNR/TNR | ||||
Note that the positive and negative predictive values can only be estimated using data from a cross-sectional study or other population-based study in which valid prevalence estimates may be obtained. In contrast, the sensitivity and specificity can be estimated from case-control studies.
Worked example
Suppose the fecal occult blood (FOB) screen test is used in 2030 people to look for bowel cancer:
| Patients with bowel cancer (as confirmed on endoscopy) | ||||
| Condition positive | Condition negative | |||
| Fecal occult blood screen test outcome |
Test outcome positive |
True positive (TP) = 20 |
False positive (FP) = 180 |
Positive predictive value = TP / (TP + FP) = 20 / (20 + 180) = 10% |
| Test outcome negative |
False negative (FN) = 10 |
True negative (TN) = 1820 |
Negative predictive value = TN / (FN + TN) = 1820 / (10 + 1820) ≈ 99.5% | |
| Sensitivity = TP / (TP + FN) = 20 / (20 + 10) ≈ 67% |
Specificity = TN / (FP + TN) = 1820 / (180 + 1820) = 91% | |||
The small positive predictive value (PPV = 10%) indicates that many of the positive results from this testing procedure are false positives. Thus it will be necessary to follow up any positive result with a more reliable test to obtain a more accurate assessment as to whether cancer is present. Nevertheless, such a test may be useful if it is inexpensive and convenient. The strength of the FOB screen test is instead in its negative predictive value – which, if negative for an individual, gives us a high confidence that its negative result is true.
Problems with positive predictive value and negative predictive value
Other individual factors
Note that the PPV is not intrinsic to the test—it depends also on the prevalence.[2] Due to the large effect of prevalence upon predictive values, a standardized approach has been proposed, where the PPV is normalized to a prevalence of 50%.[3] PPV is directly proportional to the prevalence of the disease or condition. In the above example, if the group of people tested had included a higher proportion of people with bowel cancer, then the PPV would probably come out higher and the NPV lower. If everybody in the group had bowel cancer, the PPV would be 100% and the NPV 0%.
To overcome this problem, NPV and PPV should only be used if the ratio of the number of patients in the disease group and the number of patients in the healthy control group used to establish the NPV and PPV is equivalent to the prevalence of the diseases in the studied population, or, in case two disease groups are compared, if the ratio of the number of patients in disease group 1 and the number of patients in disease group 2 is equivalent to the ratio of the prevalences of the two diseases studied. Otherwise, positive and negative likelihood ratios are more accurate than NPV and PPV, because likelihood ratios do not depend on prevalence.
When an individual being tested has a different pre-test probability of having a condition than the control groups used to establish the PPV and NPV, the PPV and NPV are generally distinguished from the positive and negative post-test probabilities, with the PPV and NPV referring to the ones established by the control groups, and the post-test probabilities referring to the ones for the tested individual (as estimated, for example, by likelihood ratios). Preferably, in such cases, a large group of equivalent individuals should be studied, in order to establish separate positive and negative predictive values for use of the test in such individuals.
Different target conditions
PPV is used to indicate the probability that in case of a positive test, that the patient really has the specified disease. However, there may be more than one cause for a disease and any single potential cause may not always result in the overt disease seen in a patient. There is potential to mix up related target conditions of PPV and NPV, such as interpreting the PPV or NPV of a test as having a disease, when that PPV or NPV value actually refers only to a predisposition of having that disease.
An example is the microbiological throat swab used in patients with a sore throat. Usually publications stating PPV of a throat swab are reporting on the probability that this bacterium is present in the throat, rather than that the patient is ill from the bacteria found. If presence of this bacterium always resulted in a sore throat, then the PPV would be very useful. However the bacteria may colonise individuals in a harmless way and never result in infection or disease. Sore throats occurring in these individuals are caused by other agents such as a virus. In this situation the gold standard used in the evaluation study represents only the presence of bacteria (that might be harmless) but not a causal bacterial sore throat illness. It can be proven that this problem will affect positive predictive value far more than negative predictive value.[4] To evaluate diagnostic tests where the gold standard looks only at potential causes of disease, one may use an extension of the predictive value termed the Etiologic Predictive Value.[5][6]
See also
- Binary classification
- Sensitivity and specificity
- False discovery rate
- Relevance (information retrieval)
- Receiver-operator characteristic
- Diagnostic odds ratio
- Sensitivity index
References
- ↑ Fletcher, Robert H. Fletcher ; Suzanne W. (2005). Clinical epidemiology : the essentials (4th ed.). Baltimore, Md.: Lippincott Williams & Wilkins. p. 45. ISBN 0-7817-5215-9.
- 1 2 Altman, DG; Bland, JM (1994). "Diagnostic tests 2: Predictive values". BMJ. 309 (6947): 102. PMC 2540558
 . PMID 8038641. doi:10.1136/bmj.309.6947.102.
. PMID 8038641. doi:10.1136/bmj.309.6947.102. - ↑ Heston, Thomas F. (2011). "Standardizing predictive values in diagnostic imaging research". Journal of Magnetic Resonance Imaging. 33 (2): 505; author reply 506–7. PMID 21274995. doi:10.1002/jmri.22466.
- ↑ Orda, Ulrich; Gunnarsson, Ronny K; Orda, Sabine; Fitzgerald, Mark; Rofe, Geoffry; Dargan, Anna (2016). "Etiologic predictive value of a rapid immunoassay for the detection of group A Streptococcus antigen from throat swabs in patients presenting with a sore throat". International Journal of Infectious Diseases. 45 (April): 32–5. PMID 26873279. doi:10.1016/j.ijid.2016.02.002.
- ↑ Gunnarsson, Ronny K.; Lanke, Jan (2002). "The predictive value of microbiologic diagnostic tests if asymptomatic carriers are present". Statistics in Medicine. 21 (12): 1773–85. PMID 12111911. doi:10.1002/sim.1119.
- ↑ Gunnarsson, Ronny K. "EPV Calculator". Science Network TV.