Monte Carlo tree search
In computer science, Monte Carlo tree search (MCTS) is a heuristic search algorithm for some kinds of decision processes, most notably those employed in game play. Two leading examples of Monte Carlo tree search are the computer game Total War: Rome II's implementation in their high level campaign AI[1] and recent computer Go programs,[2] but it also has been used in other board games, as well as real-time video games and non-deterministic games such as poker (see history section).
Principle of operation
The focus of Monte Carlo tree search is on the analysis of the most promising moves, expanding the search tree based on random sampling of the search space. The application of Monte Carlo tree search in games is based on many playouts. In each playout, the game is played out to the very end by selecting moves at random. The final game result of each playout is then used to weight the nodes in the game tree so that better nodes are more likely to be chosen in future playouts.
The most basic way to use playouts is to apply the same number of playouts after each legal move of the current player, then choosing the move which led to the most victories.[3] The efficiency of this method—called Pure Monte Carlo Game Search—often increases with time as more playouts are assigned to the moves that have frequently resulted in the player's victory (in previous playouts). Full Monte Carlo tree search employs this principle recursively on many depths of the game tree. Each round of Monte Carlo tree search consists of four steps:[4]
- Selection: start from root R and select successive child nodes down to a leaf node L. The section below says more about a way of choosing child nodes that lets the game tree expand towards most promising moves, which is the essence of Monte Carlo tree search.
- Expansion: unless L ends the game with a win/loss for either player, create one (or more) child nodes and choose node C from one of them.
- Simulation: play a random playout from node C. This step is sometimes also called playout or rollout.
- Backpropagation: use the result of the playout to update information in the nodes on the path from C to R.
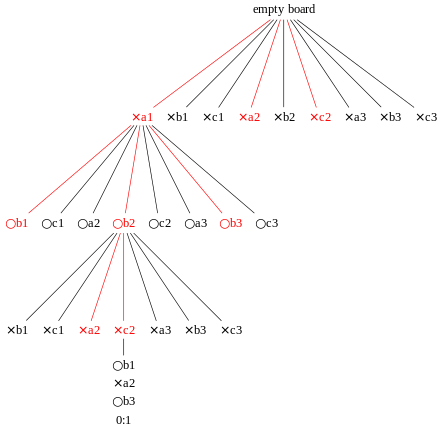
Sample steps from one round are shown in the figure below. Each tree node stores the number of won/played playouts.
.svg.png)
Note that the updating of the number of wins in each node during backpropagation should arise from the player who made the move that resulted in that node (this is not accurately reflected in the sample image above). This ensures that during selection, each player's choices expand towards the most promising moves for that player, which mirrors the goal of each player to maximize the value of their move.
Rounds of search are repeated as long as the time allotted to a move remains. Then the move with the most simulations made is selected rather than the move with the highest average win rate.
Pure Monte Carlo game search
This basic procedure can be applied to any game whose positions necessarily have a finite number of moves and finite length. For each position, all feasible moves are determined: k random games are played out to the very end, and the scores are recorded. The move leading to the best score is chosen. Ties are broken by fair coin flips. Pure Monte Carlo Game Search results in strong play in several games with random elements, as in EinStein würfelt nicht!. It converges to optimal play (as k tends to infinity) in board filling games with random turn order, for instance in Hex with random turn order. [5]
Exploration and exploitation
The main difficulty in selecting child nodes is maintaining some balance between the exploitation of deep variants after moves with high average win rate and the exploration of moves with few simulations. The first formula for balancing exploitation and exploration in games, called UCT (Upper Confidence Bound 1 applied to trees), was introduced by Levente Kocsis and Csaba Szepesvári.[6] UCT is based on the UCB1 formula derived by Auer, Cesa-Bianchi, and Fischer[7] and the provably convergent AMS (Adaptive Multi-stage Sampling) algorithm first applied to multi-stage decision making models (specifically, Markov Decision Processes) by Chang, Fu, Hu, and Marcus.[8] Kocsis and Szepesvári recommend to choose in each node of the game tree the move for which the expression has the highest value. In this formula:

- wi stands for the number of wins after the i-th move;
- ni stands for the number of simulations after the i-th move;
- c is the exploration parameter—theoretically equal to √2; in practice usually chosen empirically;
- t stands for the total number of simulations for the node considered. It is equal to the sum of all the ni.
The first component of the formula above corresponds to exploitation; it is high for moves with high average win ratio. The second component corresponds to exploration; it is high for moves with few simulations.
Most contemporary implementations of Monte Carlo tree search are based on some variant of UCT that traces its roots back to the AMS simulation optimization algorithm for estimating the value function in finite-horizon Markov Decision Processes (MDPs) introduced by Chang et al.[8] (2005) in Operations Research. (AMS was the first work to explore the idea of UCB-based exploration and exploitation in constructing sampled/simulated (Monte Carlo) trees and was the main seed for UCT.[9])
Advantages and disadvantages
Although it has been proved that the evaluation of moves in Monte Carlo tree search converges to minimax,[10] the basic version of Monte Carlo tree search converges very slowly. However Monte Carlo tree search does offer significant advantages over alpha–beta pruning and similar algorithms that minimize the search space.
In particular, Monte Carlo tree search does not need an explicit evaluation function. Simply implementing the game's mechanics is sufficient to explore the search space (i.e. the generating of allowed moves in a given position and the game-end conditions). As such, Monte Carlo tree search can be employed in games without a developed theory or in general game playing.
The game tree in Monte Carlo tree search grows asymmetrically as the method concentrates on the more promising subtrees. Thus it achieves better results than classical algorithms in games with a high branching factor.
Moreover, Monte Carlo tree search can be interrupted at any time yielding the most promising move already found.
A disadvantage is that, faced in a game with an expert player, there may be a single branch which leads to a loss. Because this is not easily found at random, the search may not "see" it and will not take it into account. It is believed that this may have been part of the reason for AlphaGo's loss in its fourth game against Lee Sedol. In essence, the search attempts to prune sequences which are less relevant. In some cases, a play can lead to a very specific line of play which is significant, but which is overlooked when the tree is pruned, and this outcome is therefore "off the search radar".[11]
Improvements
Various modifications of the basic Monte Carlo tree search method have been proposed to shorten the search time. Some employ domain-specific expert knowledge, others do not.
Monte Carlo tree search can use either light or heavy playouts. Light playouts consist of random moves while heavy playouts apply various heuristics to influence the choice of moves.[12] These heuristics may employ the results of previous playouts (e.g. the Last Good Reply heuristic[13]) or expert knowledge of a given game. For instance, in many go-playing programs certain stone patterns in a portion of the board influence the probability of moving into that area.[14] Paradoxically, playing suboptimally in simulations sometimes makes a Monte Carlo tree search program play stronger overall.[15]

Domain-specific knowledge may be employed when building the game tree to help the exploitation of some variants. One such method assigns nonzero priors to the number of won and played simulations when creating each child node, leading to artificially raised or lowered average win rates that cause the node to be chosen more or less frequently, respectively, in the selection step.[16] A related method, called progressive bias, consists in adding to the UCB1 formula a element, where bi is a heuristic score of the i-th move.[4]

The basic Monte Carlo tree search collects enough information to find the most promising moves only after many rounds; until then its moves are essentially random. This exploratory phase may be reduced significantly in a certain class of games using RAVE (Rapid Action Value Estimation).[16] In these games, permutations of a sequence of moves lead to the same position. Typically, they are board games in which a move involves placement of a piece or a stone on the board. In such games the value of each move is often only slightly influenced by other moves.
In RAVE, for a given game tree node N, its child nodes Ci store not only the statistics of wins in playouts started in node N but also the statistics of wins in all playouts started in node N and below it, if they contain move i (also when the move was played in the tree, between node N and a playout). This way the contents of tree nodes are influenced not only by moves played immediately in a given position but also by the same moves played later.
When using RAVE, the selection step selects the node, for which the modified UCB1 formula has the highest value. In this formula, and stand for the number of won playouts containing move i and the number of all playouts containing move i, and the function should be close to one and to zero for relatively small and relatively big ni and , respectively. One of many formulas for , proposed by D. Silver,[17] says that in balanced positions one can take , where b is an empirically chosen constant.





Heuristics used in Monte Carlo tree search often require many parameters. There are automated methods to tune the parameters to maximize the win rate.[18]
Monte Carlo tree search can be concurrently executed by many threads or processes. There are several fundamentally different methods of its parallel execution:[19]
- Leaf parallelization, i.e. parallel execution of many playouts from one leaf of the game tree.
- Root parallelization, i.e. building independent game trees in parallel and making the move basing on the root-level branches of all these trees.
- Tree parallelization, i.e. parallel building of the same game tree, protecting data from simultaneous writes either with one, global mutex, with more mutexes, or with non-blocking synchronization.[20]
History
The Monte Carlo method, based on random sampling, dates back to the 1940s. Bruce Abramson explored the idea in his 1987 PhD thesis and said it "is shown to be precise, accurate, easily estimable, efficiently calculable, and domain-independent."[21] He experimented in-depth with Tic-tac-toe and then with machine generated evaluation functions for Othello and Chess. Such methods were first explored and successfully applied to heuristic search in the field of automated theorem proving by W. Ertel, J. Schumann and C. Suttner in 1989,[22][23][24] thus improving the exponential search times of uninformed search algorithms such as e.g. breadth-first search, depth-first search or iterative deepening. In 1992, B. Brügmann employed it for the first time in a go-playing program.[3] Chang et al.[8] proposed the idea of "recursive rolling out and backtracking" with "adaptive" sampling choices in their Adaptive Multi-stage Sampling (AMS) algorithm for the model of Markov decision processes. (AMS was the first work to explore the idea of UCB-based exploration and exploitation in constructing sampled/simulated (Monte Carlo) trees and was the main seed for UCT.[9]). Inspired by these predecessors,[25] Rémi Coulom described the application of the Monte Carlo method to game-tree search and coined the name Monte Carlo tree search,[26] L. Kocsis and Cs. Szepesvári developed the UCT algorithm,[6] and S. Gelly et al. implemented UCT in their program MoGo.[14] In 2008, MoGo achieved dan (master) level in 9×9 go,[27] and the Fuego program began to win with strong amateur players in 9×9 go.[28] In January 2012, the Zen program won 3:1 in a Go match on a 19×19 board with an amateur 2 dan player.[29] Google Deepmind developed the program AlphaGo, which in October 2015 became the first Computer Go program to beat a professional human Go player without handicaps on a full-sized 19x19 board.[30][31] In March 2016, AlphaGo was awarded an honorary 9-dan (master) level in 19×19 go for defeating Lee Sedol in a five-game match with a final score of four games to one.[32] AlphaGo represents a significant improvement over previous Go programmes as well as a milestone in machine learning as it uses Monte Carlo tree search via artificial neural networks (a deep learning method) with efficiency far surpassing previous programmes.[33]
Monte Carlo tree search has also been used in programs that play other board games (for example Hex,[35] Havannah,[36] Game of the Amazons,[37] and Arimaa[38]), real-time video games (for instance Ms. Pac-Man,[39][40] Fable Legends and Total War: Rome II[41]), and nondeterministic games (such as skat,[42] poker,[43] Magic: The Gathering,[44] or Settlers of Catan[45]).
See also
- AlphaGo, a human-equivalent Go program using both Monte Carlo tree search and deep learning.
References
- ↑ "Monte-Carlo Tree Search in TOTAL WAR: ROME II’s Campaign AI". AI Game Dev. Retrieved 25 February 2017.
- ↑ Silver, David; Huang, Aja; Maddison, Chris J.; Guez, Arthur; Sifre, Laurent; Driessche, George van den; Schrittwieser, Julian; Antonoglou, Ioannis; Panneershelvam, Veda. "Mastering the game of Go with deep neural networks and tree search". Nature. 529 (7587): 484–489. doi:10.1038/nature16961.
- 1 2 Brügmann, Bernd (1993). Monte Carlo Go (PDF). Technical report, Department of Physics, Syracuse University.
- 1 2 G.M.J.B. Chaslot; M.H.M. Winands; J.W.H.M. Uiterwijk; H.J. van den Herik; B. Bouzy (2008). "Progressive Strategies for Monte-Carlo Tree Search" (PDF). New Mathematics and Natural Computation. 4 (3): 343–359. doi:10.1142/s1793005708001094.
- ↑ Peres, Yuval; Schramm, Oded; Sheffield, Scott; Wilson, David B. (2006). "Random-Turn Hex and other selection games". arXiv:math/0508580
 [math.PR)].
[math.PR)]. - 1 2 Kocsis, Levente; Szepesvári, Csaba (2006). "Bandit based Monte-Carlo Planning". Machine Learning: ECML 2006, 17th European Conference on Machine Learning, Berlin, Germany, September 18–22, 2006, Proceedings. Lecture Notes in Computer Science 4212. Johannes Fürnkranz, Tobias Scheffer, Myra Spiliopoulou (eds.). Springer. pp. 282–293. ISBN 3-540-45375-X.
- ↑ Auer, Peter; Cesa-Bianchi, Nicolò; Fischer, Paul (2002). "Finite-time Analysis of the Multiarmed Bandit Problem" (PDF). Machine Learning. 47: 235–256. doi:10.1023/a:1013689704352.
- 1 2 3 Chang, Hyeong Soo; Fu, Michael C.; Hu, Jiaqiao; Marcus, Steven I. (2005). "An Adaptive Sampling Algorithm for Solving Markov Decision Processes" (PDF). Operations Research. 53: 126–139. doi:10.1287/opre.1040.0145.
- 1 2 Hyeong Soo Chang; Michael Fu; Jiaqiao Hu; Steven I. Marcus (2016). "Google DeepMind's Alphago: O.R.'s unheralded role in the path-breaking achievement". ORMS Today. INFORMS. 45 (5): 24–29.
- ↑ Bouzy, Bruno. "Old-fashioned Computer Go vs Monte-Carlo Go". IEEE Symposium on Computational Intelligence and Games, April 1–5, 2007, Hilton Hawaiian Village, Honolulu, Hawaii (PDF).
- ↑ "Lee Sedol defeats AlphaGo in masterful comeback - Game 4". Go Game Guru.
- ↑ Swiechowski, M.; Mandziuk, J., "Self-Adaptation of Playing Strategies in General Game Playing" (2010), IEEE Transactions on Computational Intelligence and AI in Games, doi: 10.1109/TCIAIG.2013.2275163, http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6571225&isnumber=4804729
- ↑ Drake, Peter (December 2009). "The Last-Good-Reply Policy for Monte-Carlo Go". ICGA Journal. 32 (4): 221–227.
- 1 2 3 Sylvain Gelly; Yizao Wang; Rémi Munos; Olivier Teytaud (November 2006). Modification of UCT with Patterns in Monte-Carlo Go (PDF). Technical report, INRIA.
- ↑ Seth Pellegrino; Peter Drake (2010). "Investigating the Effects of Playout Strength in Monte-Carlo Go". Proceedings of the 2010 International Conference on Artificial Intelligence, ICAI 2010, July 12–15, 2010, Las Vegas Nevada, USA. Hamid R. Arabnia, David de la Fuente, Elena B. Kozerenko, José Angel Olivas, Rui Chang, Peter M. LaMonica, Raymond A. Liuzzi, Ashu M. G. Solo (eds.). CSREA Press. pp. 1015–1018. ISBN 1-60132-148-1.
- 1 2 Sylvain Gelly; David Silver (2007). "Combining Online and Offline Knowledge in UCT". Machine Learning, Proceedings of the Twenty-Fourth International Conference (ICML 2007), Corvallis, Oregon, USA, June 20–24, 2007 (PDF). Zoubin Ghahramani (ed.). ACM. pp. 273–280. ISBN 978-1-59593-793-3.
- ↑ David Silver (2009). Reinforcement Learning and Simulation-Based Search in Computer Go (PDF). PhD thesis, University of Alberta.
- ↑ Rémi Coulom. "CLOP: Confident Local Optimization for Noisy Black-Box Parameter Tuning". ACG 2011: Advances in Computer Games 13 Conference, Tilburg, the Netherlands, November 20–22.
- ↑ Guillaume M.J-B. Chaslot, Mark H.M. Winands, Jaap van den Herik (2008). "Parallel Monte-Carlo Tree Search". Computers and Games, 6th International Conference, CG 2008, Beijing, China, September 29 – October 1, 2008. Proceedings (PDF). H. Jaap van den Herik, Xinhe Xu, Zongmin Ma, Mark H. M. Winands (eds.). Springer. pp. 60–71. ISBN 978-3-540-87607-6.
- ↑ Markus Enzenberger; Martin Müller (2010). "A Lock-free Multithreaded Monte-Carlo Tree Search Algorithm". Advances in Computer Games: 12th International Conference, ACG 2009, Pamplona, Spain, May 11–13, 2009, Revised Papers. Jaap Van Den Herik, Pieter Spronck (eds.). Springer. pp. 14–20. ISBN 978-3-642-12992-6.
- ↑ Abramson, Bruce (1987). The Expected-Outcome Model of Two-Player Games (PDF). Technical report, Department of Computer Science, Columbia University. Retrieved 23 December 2013.
- ↑ Wolfgang Ertel; Johann Schumann; Christian Suttner (1989). "Learning Heuristics for a Theorem Prover using Back Propagation.". In J. Retti; K. Leidlmair. 5. Österreichische Artificial-Intelligence-Tagung. Informatik-Fachberichte 208,pp. 87-95. Springer.
- ↑ Christian Suttner; Wolfgang Ertel (1990). "Automatic Acquisition of Search Guiding Heuristics.". CADE90, 10th Int. Conf. on Automated Deduction.pp. 470-484. LNAI 449. Springer.
- ↑ Christian Suttner; Wolfgang Ertel (1991). "Using Back-Propagation Networks for Guiding the Search of a Theorem Prover.". J. of Neural Networks Research & Applications. 2 (1): 3–16.
- ↑ Rémi Coulom (2008). "The Monte-Carlo Revolution in Go". Japanese-French Frontiers of Science Symposium (PDF).
- ↑ Rémi Coulom (2007). "Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search". Computers and Games, 5th International Conference, CG 2006, Turin, Italy, May 29–31, 2006. Revised Papers. H. Jaap van den Herik, Paolo Ciancarini, H. H. L. M. Donkers (eds.). Springer. pp. 72–83. ISBN 978-3-540-75537-1.
- ↑ Chang-Shing Lee; Mei-Hui Wang; Guillaume Chaslot; Jean-Baptiste Hoock; Arpad Rimmel; Olivier Teytaud; Shang-Rong Tsai; Shun-Chin Hsu; Tzung-Pei Hong (2009). "The Computational Intelligence of MoGo Revealed in Taiwan’s Computer Go Tournaments" (PDF). IEEE Transactions on Computational Intelligence and AI in Games. 1 (1): 73–89. doi:10.1109/tciaig.2009.2018703.
- ↑ Markus Enzenberger; Martin Mūller (2008). Fuego – An Open-Source Framework for Board Games and Go Engine Based on Monte Carlo Tree Search (PDF). Technical report, University of Alberta.
- ↑ "The Shodan Go Bet". Retrieved 2012-05-02.
- ↑ "Research Blog: AlphaGo: Mastering the ancient game of Go with Machine Learning". Google Research Blog. 27 January 2016.
- ↑ "Google achieves AI 'breakthrough' by beating Go champion". BBC News. 27 January 2016.
- ↑ "Match 1 - Google DeepMind Challenge Match: Lee Sedol vs AlphaGo". Youtube. 9 March 2016.
- ↑ "Google AlphaGo AI clean sweeps European Go champion". ZDNet. 28 January 2016.
- ↑ "Sensei's Library: KGSBotRatings". Retrieved 2012-05-03.
- ↑ Broderick Arneson; Ryan Hayward; Philip Henderson (June 2009). "MoHex Wins Hex Tournament" (PDF). ICGA Journal. 32 (2): 114–116.
- ↑ Timo Ewalds (2011). Playing and Solving Havannah (PDF). Master's thesis, University of Alberta.
- ↑ Richard J. Lorentz (2008). "Amazons Discover Monte-Carlo". Computers and Games, 6th International Conference, CG 2008, Beijing, China, September 29 – October 1, 2008. Proceedings. H. Jaap van den Herik, Xinhe Xu, Zongmin Ma, Mark H. M. Winands (eds.). Springer. pp. 13–24. ISBN 978-3-540-87607-6.
- ↑ Tomáš Kozelek (2009). Methods of MCTS and the game Arimaa (PDF). Master's thesis, Charles University in Prague.
- ↑ Xiaocong Gan; Yun Bao; Zhangang Han (December 2011). "Real-Time Search Method in Nondeterministic Game – Ms. Pac-Man". ICGA Journal. 34 (4): 209–222.
- ↑ Tom Pepels; Mark H. M. Winands; Marc Lanctot (September 2014). "Real-Time Monte Carlo Tree Search in Ms Pac-Man". IEEE Transactions on Computational Intelligence and AI in Games. 6 (3): 245–257. doi:10.1109/tciaig.2013.2291577.
- ↑ "Monte-Carlo Tree Search in TOTAL WAR: ROME II's Campaign AI". Retrieved 2014-08-13.
- ↑ Michael Buro; Jeffrey Richard Long; Timothy Furtak; Nathan R. Sturtevant (2009). "Improving State Evaluation, Inference, and Search in Trick-Based Card Games". IJCAI 2009, Proceedings of the 21st International Joint Conference on Artificial Intelligence, Pasadena, California, USA, July 11–17, 2009. Craig Boutilier (ed.). pp. 1407–1413.
- ↑ Jonathan Rubin; Ian Watson (April 2011). "Computer poker: A review" (PDF). Artificial Intelligence. 175 (5–6): 958–987. doi:10.1016/j.artint.2010.12.005.
- ↑ C.D. Ward; P.I. Cowling (2009). "Monte Carlo Search Applied to Card Selection in Magic: The Gathering". CIG'09 Proceedings of the 5th international conference on Computational Intelligence and Games (PDF). IEEE Press. Archived from the original (PDF) on 2016-05-28.
- ↑ István Szita; Guillaume Chaslot; Pieter Spronck (2010). "Monte-Carlo Tree Search in Settlers of Catan". Advances in Computer Games, 12th International Conference, ACG 2009, Pamplona, Spain, May 11–13, 2009. Revised Papers (PDF). H. Jaap van den Herik, Pieter Spronck (eds.). Springer. pp. 21–32. ISBN 978-3-642-12992-6.
Bibliography
- Cameron Browne; Edward Powley; Daniel Whitehouse; Simon Lucas; Peter I. Cowling; Philipp Rohlfshagen; Stephen Tavener; Diego Perez; Spyridon Samothrakis; Simon Colton (March 2012). "A Survey of Monte Carlo Tree Search Methods" (PDF). IEEE Transactions on Computational Intelligence and AI in Games. 4 (1).