Long short-term memory
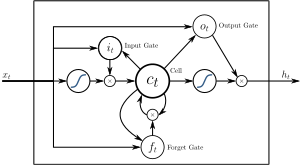


Long short-term memory (LSTM) is an artificial neural network architecture that supports machine learning. It is recurrent (RNN), allowing data to flow both forwards and backwards within the network.
An LSTM is well-suited to learn from experience to classify, process and predict time series given time lags of unknown size and bound between important events. Relative insensitivity to gap length gives an advantage to LSTM over alternative RNNs, hidden Markov models and other sequence learning methods in numerous applications.
History
LSTM was proposed in 1997 by Sepp Hochreiter and Jürgen Schmidhuber[2] and improved in 2000 by Felix Gers et al.[3]
Among other successes, LSTM achieved record results in natural language text compression,[4] unsegmented connected handwriting recognition[5] and won the ICDAR handwriting competition (2009). LSTM networks were a major component of a network that achieved a record 17.7% phoneme error rate on the classic TIMIT natural speech dataset (2013).[6]
As of 2016, major technology companies including Google, Apple, and Microsoft were using LSTM as fundamental components in new products.[7] For example, Google used LSTM for speech recognition on the smartphone,[8][9] for the smart assistant Allo[10] and for Google Translate.[11][12] Apple uses LSTM for the "Quicktype" function on the iPhone[13][14] and for Siri.[15] Amazon uses LSTM for Amazon Alexa.[16]
Architecture
A LSTM network contains LSTM units instead of, or in addition to, other network units. A LSTM unit remembers values for either long or short time periods. The key to this ability is that it uses no activation function within its recurrent components. Thus, the stored value is not iteratively modified and the gradient does not tend to vanish when trained with backpropagation through time.
LSTM units are often implemented in "blocks" containing several units. This design is typical with deep neural networks and facilitates implementations with parallel hardware. In the equations below, each variable in lowercase italics represents a vector with a length equal to the number of LSTM units in the block.
LSTM blocks contain three or four "gates" that control information flow. These gates are implemented using the logistic function to compute a value between 0 and 1. Multiplication is applied with this value to partially allow or deny information to flow into or out of the memory. For example, an "input" gate controls the extent to which a new value flows into the memory. A "forget" gate controls the extent to which a value remains in memory. An "output" gate controls the extent to which the value in memory is used to compute the output activation of the block. (In some implementations, the input and forget gates are merged into a single gate. The motivation for combining them is that the time to forget is when a new value worth remembering becomes available.)
The weights in a LSTM block ( and ) are used to direct the operation of the gates. These weights are applied to the values that feed into the block (including the input vector and the output from the previous time at step ) at each of the gates. Thus, the LSTM block determines how to maintain its memory as a function of those values, and training its weights causes the block to learn the function that minimizes loss.




Traditional LSTM
Traditional LSTM with forget gates.[2][3]
Initial values: and . The operator denotes the Hadamard product (entry-wise product).




Variables
- : input vector
- : output vector
- : cell state vector
- , and : parameter matrices and vector
- , and : gate vectors
- : Forget gate vector. Weight of remembering old information.
- : Input gate vector. Weight of acquiring new information.
- : Output gate vector. Output candidate.





- : The original is a sigmoid function.
- : The original is a hyperbolic tangent.
- : The original is a hyperbolic tangent, but the peephole LSTM paper suggests .[17][18]




Peephole LSTM
Peephole LSTM with forget gates.[17][18] is not used, is used instead in most places.

Convolutional LSTM
Convolutional LSTM.[19] denotes the convolution operator.


Training
To minimize LSTM's total error on a set of training sequences, iterative gradient descent such as backpropagation through time can be used to change each weight in proportion to its derivative with respect to the error. A major problem with gradient descent for standard RNNs is that error gradients vanish exponentially quickly with the size of the time lag between important events.[20][21] With LSTM blocks, however, when error values are back-propagated from the output, the error becomes trapped in the block's memory. This is referred to as an "error carousel" that continuously feeds error back to each of the gates until they become trained to cut off the value. Thus, regular backpropagation is effective at training an LSTM block to remember values for long durations.
LSTM can also be trained by a combination of artificial evolution for weights to the hidden units, and pseudo-inverse or support vector machines for weights to the output units.[22] In reinforcement learning applications LSTM can be trained by policy gradient methods, evolution strategies or genetic algorithms.
Applications
Applications of LSTM include:
- Robot control[23]
- Time series prediction[24]
- Speech recognition[25][26][27]
- Rhythm learning[18]
- Music composition[28]
- Grammar learning[29][17][30]
- Handwriting recognition[31][32]
- Human action recognition[33]
- Protein Homology Detection[34]
- Predicting subcellular localization of proteins[35]
LSTM has Turing completeness in the sense that given enough network units it can compute any result that a conventional computer can compute, provided it has the proper weight matrix, which may be viewed as its program.
See also
- Differentiable neural computer
- Gated recurrent unit
- Long-term potentiation
- Prefrontal cortex basal ganglia working memory
- Recurrent neural network
- Time series
References
- ↑ Klaus Greff; Rupesh Kumar Srivastava; Jan Koutník; Bas R. Steunebrink; Jürgen Schmidhuber (2015). "LSTM: A Search Space Odyssey". arXiv:1503.04069
 .
. - 1 2 Sepp Hochreiter; Jürgen Schmidhuber (1997). "Long short-term memory". Neural Computation. 9 (8): 1735–1780. PMID 9377276. doi:10.1162/neco.1997.9.8.1735.
- 1 2 Felix A. Gers; Jürgen Schmidhuber; Fred Cummins (2000). "Learning to Forget: Continual Prediction with LSTM". Neural Computation. 12 (10): 2451–2471. doi:10.1162/089976600300015015.
- ↑ "The Large Text Compression Benchmark". Retrieved 2017-01-13.
- ↑ Graves, A.; Liwicki, M.; Fernández, S.; Bertolami, R.; Bunke, H.; Schmidhuber, J. (May 2009). "A Novel Connectionist System for Unconstrained Handwriting Recognition". IEEE Transactions on Pattern Analysis and Machine Intelligence. 31 (5): 855–868. ISSN 0162-8828. doi:10.1109/tpami.2008.137.
- ↑ Graves, Alex; Mohamed, Abdel-rahman; Hinton, Geoffrey (2013-03-22). "Speech Recognition with Deep Recurrent Neural Networks". arXiv:1303.5778 [cs].
- ↑ "With QuickType, Apple wants to do more than guess your next text. It wants to give you an AI.". WIRED. Retrieved 2016-06-16.
- ↑ Beaufays, Françoise (August 11, 2015). "The neural networks behind Google Voice transcription". Research Blog. Retrieved 2017-06-27.
- ↑ Sak, Haşim; Senior, Andrew; Rao, Kanishka; Beaufays, Françoise; Schalkwyk, Johan (September 24, 2015). "Google voice search: faster and more accurate". Research Blog. Retrieved 2017-06-27.
- ↑ Khaitan, Pranav (May 18, 2016). "Chat Smarter with Allo". Research Blog. Retrieved 2017-06-27.
- ↑ Wu, Yonghui; Schuster, Mike; Chen, Zhifeng; Le, Quoc V.; Norouzi, Mohammad; Macherey, Wolfgang; Krikun, Maxim; Cao, Yuan; Gao, Qin (2016-09-26). "Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation". arXiv:1609.08144 [cs].
- ↑ Metz, Cade (September 27, 2016). "An Infusion of AI Makes Google Translate More Powerful Than Ever | WIRED". www.wired.com. Retrieved 2017-06-27.
- ↑ Efrati, Amir (June 13, 2016). "Apple’s Machines Can Learn Too". The Information. Retrieved 2017-06-27.
- ↑ Ranger, Steve (June 14, 2016.). "iPhone, AI and big data: Here's how Apple plans to protect your privacy | ZDNet". ZDNet. Retrieved 2017-06-27. Check date values in:
|date=(help) - ↑ Smith, Chris (2016-06-13). "iOS 10: Siri now works in third-party apps, comes with extra AI features". BGR. Retrieved 2017-06-27.
- ↑ Vogels, Werner (30 November 2016). "Bringing the Magic of Amazon AI and Alexa to Apps on AWS. - All Things Distributed". www.allthingsdistributed.com. Retrieved 2017-06-27.
- 1 2 3 Gers, F. A.; Schmidhuber, J. (2001). "LSTM Recurrent Networks Learn Simple Context Free and Context Sensitive Languages" (PDF). IEEE Transactions on Neural Networks. 12 (6): 1333–1340. doi:10.1109/72.963769.
- 1 2 3 Gers, F.; Schraudolph, N.; Schmidhuber, J. (2002). "Learning precise timing with LSTM recurrent networks" (PDF). Journal of Machine Learning Research. 3: 115–143.
- ↑ Xingjian Shi; Zhourong Chen; Hao Wang; Dit-Yan Yeung; Wai-kin Wong; Wang-chun Woo (2015). "Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting". Proceedings of the 28th International Conference on Neural Information Processing Systems: 802–810.
- ↑ S. Hochreiter. Untersuchungen zu dynamischen neuronalen Netzen. Diploma thesis, Institut f. Informatik, Technische Univ. Munich, 1991.
- ↑ Hochreiter, S.; Bengio, Y.; Frasconi, P.; Schmidhuber, J. (2001). "Gradient Flow in Recurrent Nets: the Difficulty of Learning Long-Term Dependencies (PDF Download Available)". In Kremer and, S. C.; Kolen, J. F. A Field Guide to Dynamical Recurrent Neural Networks. ResearchGate. IEEE Press. Retrieved 2017-06-27.
- ↑ Schmidhuber, J.; Wierstra, D.; Gagliolo, M.; Gomez, F. (2007). "Training Recurrent Networks by Evolino". Neural Computation. 19 (3): 757–779. doi:10.1162/neco.2007.19.3.757.
- ↑ Mayer, H.; Gomez, F.; Wierstra, D.; Nagy, I.; Knoll, A.; Schmidhuber, J. (October 2006). "A System for Robotic Heart Surgery that Learns to Tie Knots Using Recurrent Neural Networks". 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems: 543–548. doi:10.1109/IROS.2006.282190.
- ↑ Wierstra, Daan; Schmidhuber, J.; Gomez, F. J. (2005). "Evolino: Hybrid Neuroevolution/Optimal Linear Search for Sequence Learning". Proceedings of the 19th International Joint Conference on Artificial Intelligence (IJCAI), Edinburgh: 853–858.
- ↑ Graves, A.; Schmidhuber, J. (2005). "Framewise phoneme classification with bidirectional LSTM and other neural network architectures". Neural Networks. 18 (5–6): 602–610. doi:10.1016/j.neunet.2005.06.042.
- ↑ Fernández, Santiago; Graves, Alex; Schmidhuber, Jürgen (2007). "An Application of Recurrent Neural Networks to Discriminative Keyword Spotting". Proceedings of the 17th International Conference on Artificial Neural Networks. ICANN'07. Berlin, Heidelberg: Springer-Verlag: 220–229. ISBN 3540746935.
- ↑ Graves, Alex; Mohamed, Abdel-rahman; Hinton, Geoffrey (2013). "Speech Recognition with Deep Recurrent Neural Networks". Acoustics, Speech and Signal Processing (ICASSP), 2013 IEEE International Conference on: 6645–6649.
- ↑ Eck, Douglas; Schmidhuber, Jürgen (2002-08-28). "Learning the Long-Term Structure of the Blues". Artificial Neural Networks — ICANN 2002. Springer, Berlin, Heidelberg: 284–289. ISBN 3540460845. doi:10.1007/3-540-46084-5_47.
- ↑ Schmidhuber, J.; Gers, F.; Eck, D.; Schmidhuber, J.; Gers, F. (2002). "Learning nonregular languages: A comparison of simple recurrent networks and LSTM". Neural Computation. 14 (9): 2039–2041. doi:10.1162/089976602320263980.
- ↑ Perez-Ortiz, J. A.; Gers, F. A.; Eck, D.; Schmidhuber, J. (2003). "Kalman filters improve LSTM network performance in problems unsolvable by traditional recurrent nets". Neural Networks. 16 (2): 241–250. doi:10.1016/s0893-6080(02)00219-8.
- ↑ A. Graves, J. Schmidhuber. Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks. Advances in Neural Information Processing Systems 22, NIPS'22, pp 545–552, Vancouver, MIT Press, 2009.
- ↑ Graves, Alex; Fernández, Santiago; Liwicki, Marcus; Bunke, Horst; Schmidhuber, Jürgen (2007). "Unconstrained Online Handwriting Recognition with Recurrent Neural Networks". Proceedings of the 20th International Conference on Neural Information Processing Systems. NIPS'07. USA: Curran Associates Inc.: 577–584. ISBN 9781605603520.
- ↑ M. Baccouche, F. Mamalet, C Wolf, C. Garcia, A. Baskurt. Sequential Deep Learning for Human Action Recognition. 2nd International Workshop on Human Behavior Understanding (HBU), A.A. Salah, B. Lepri ed. Amsterdam, Netherlands. pp. 29–39. Lecture Notes in Computer Science 7065. Springer. 2011
- ↑ Hochreiter, S.; Heusel, M.; Obermayer, K. (2007). "Fast model-based protein homology detection without alignment". Bioinformatics. 23 (14): 1728–1736. PMID 17488755. doi:10.1093/bioinformatics/btm247.
- ↑ Thireou, T.; Reczko, M. (2007). "Bidirectional Long Short-Term Memory Networks for predicting the subcellular localization of eukaryotic proteins". IEEE/ACM Transactions on Computational Biology and Bioinformatics (TCBB). 4 (3): 441–446. doi:10.1109/tcbb.2007.1015.
External links
- Recurrent Neural Networks with over 30 LSTM papers by Jürgen Schmidhuber's group at IDSIA
- Gers PhD thesis on LSTM networks.
- Fraud detection paper with two chapters devoted to explaining recurrent neural networks, especially LSTM.
- Paper on a high-performing extension of LSTM that has been simplified to a single node type and can train arbitrary architectures.
- Tutorial: How to implement LSTM in python with theano