File comparison
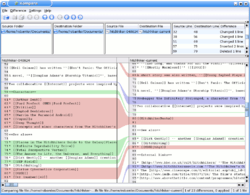
In computing, file comparison is the calculation and display of the differences and similarities between data objects, typically text files such as source code.
The methods, implementations, and results are typically called a diff,[1] after the Unix diff utility. The output may be presented in a graphical user interface or used as part of larger tasks in networks, file systems, or revision control.
Some widely used file comparison programs are diff, cmp, FileMerge, WinMerge, Beyond Compare, and Microsoft File Compare.
Many text editors and word processors perform file comparison to highlight the changes to a document.
Method types
Most file comparison tools find the longest common subsequence between two files. Any data not in the longest common subsequence is presented as an insertion or deletion.
In 1978, Paul Heckel published an algorithm that identifies most moved blocks of text.[2] This is used in the IBM History Flow tool.[3] Other file comparison programs find block moves.
Some specialized file comparison tools find the longest increasing subsequence between two files.[4] The rsync protocol uses a rolling hash function to compare two files on two distant computers with low communication overhead.
File comparison in word processors is typically at the word level, while comparison in most programming tools is at the line level. Byte or character-level comparison is useful in some specialized applications.
Display
Display of file comparison varies, with the main approaches being either showing two files side-by-side, or showing a single file, with markup showing the changes from one file to the other. In either case, particularly side-by-side viewing, code folding or text folding may be used to hide unchanged portions of the file, only showing the changed portions.
Reasoning
Comparison tools are used for various reasons. When one wishes to compare binary files, byte-level is probably best. But if one wishes to compare text files or computer programs, a side-by-side visual comparison is usually best. This gives the user the chance to decide which file is the preferred one to retain, if the files should be merged to create one containing all of the differences, or perhaps to keep them both as-is for later reference, through some form of "versioning" control.
File comparison is an important, and most likely integral, part of file synchronization and backup. In backup methodologies, the issue of data corruption is an important one. Corruption occurs without warning and without our knowledge; at least usually until too late to recover the missing parts. Usually, the only way to know for sure if a file has become corrupted is when it is next used or opened. Barring that, one must use a comparison tool to at least recognize that a difference has occurred. Therefore, all file sync or backup programs must include file comparison if these programs are to be actually useful and trusted.
Historical uses
Prior to file comparison, machines existed to compare magnetic tapes or punch cards. The IBM 519 Card Reproducer could determine whether a deck of punched cards were equivalent. In 1957, John Van Gardner developed a system to compare the check sums of loaded sections of Fortran programs to debug compilation problems on the IBM 704.[5]
See also
- Comparison of file comparison tools
- Computer-assisted reviewing
- Data differencing
- Delta encoding
- Edit distance
References
- ↑ "diff", The Jargon File.
- ↑ Heckel, Paul (1978), "A Technique for Isolating Differences Between Files" (PDF), Communications of the ACM, 21: 264–268, doi:10.1145/359460.359467, retrieved 2011-12-04
- ↑ Viégas, Fernanda B.; Wattenberg, Martin; Kushal, Kushal Dave (2004), Studying Cooperation and Conflict between Authors with history flow Visualizations (PDF), 6, Vienna: CHI, pp. 575–582, retrieved 2011-12-01
- ↑
United States patent law Legislation Types of patent claims Procedures Other topics - ↑ John Van Gardner. "Fortran And The Genesis Of Project Intercept" (PDF). Retrieved 2011-12-06.
External links
| Wikimedia Commons has media related to File comparison. |