ELKI
|
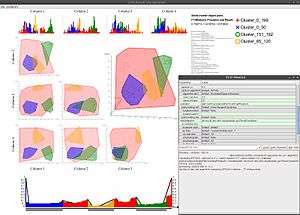
Screenshot of ELKI 0.4 visualizing OPTICS cluster analysis. | |
| Developer(s) | Ludwig Maximilian University of Munich, Heidelberg University, University of Southern Denmark |
|---|---|
| Stable release |
0.7.1
/ February 11, 2016 |
| Repository |
github |
| Written in | Java |
| Operating system | Microsoft Windows, Linux, Mac OS |
| Platform | Java platform |
| Type | Data mining |
| License | AGPL (since version 0.4.0) |
| Website |
elki-project |
ELKI (for Environment for DeveLoping KDD-Applications Supported by Index-Structures) is a knowledge discovery in databases (KDD, "data mining") software framework developed for use in research and teaching originally at the database systems research unit of Professor Hans-Peter Kriegel at the Ludwig Maximilian University of Munich, Germany. It aims at allowing the development and evaluation of advanced data mining algorithms and their interaction with database index structures.
Description
The ELKI framework is written in Java and built around a modular architecture. Most currently included algorithms belong to clustering, outlier detection[1] and database indexes. A key concept of ELKI is to allow the combination of arbitrary algorithms, data types, distance functions and indexes and evaluate these combinations. When developing new algorithms or index structures, the existing components can be reused and combined.
ELKI has been used in data science for example to cluster sperm whale codas,[2] phonemes,[3] spaceflight operations,[4] bike sharing redistribution,[5] and traffic prediction.[6]
Objectives
The university project is developed for use in teaching and research. The source code is written with extensibility, readability and reusability in mind, but is also well-optimized for performance. The experimental evaluation of algorithms depends on many environmental factors and implementation details can have a huge impact on the runtime.[7] ELKI aims at providing a shared codebase with comparable implementations of many algorithms.
As research project, it currently does not offer integration with business intelligence applications or an interface to common database management systems via SQL. The copyleft (AGPL) license may also be a hindrance to commercial usage. Furthermore, the application of the algorithms requires knowledge about their usage, parameters, and study of original literature. The audience are students, researchers and software engineers.
Architecture
ELKI is modeled around a database core, which uses a vertical data layout that stores data in column groups (similar to column families in NoSQL databases). This database core provides nearest neighbor search, range/radius search, and distance query functionality with index acceleration for a wide range of dissimilarity measures. Algorithms based on such queries (e.g. k-nearest-neighbor algorithm, local outlier factor and DBSCAN) can be implemented easily and benefit from the index acceleration. The database core also provides fast and memory efficient collections for object collections and associative structures such as nearest neighbor lists.
ELKI makes extensive use of Java interfaces, so that it can be extended easily in many places. For example, custom data types, distance functions, index structures, algorithms, input parsers, and output modules can be added and combined without modifying the existing code. This includes the possibility of defining a custom distance function and using existing indexes for acceleration.
ELKI uses a service loader architecture to allow publishing extensions as separate jar files.
ELKI uses optimized collections for performance rather than the standard Java API.[8] For loops for example are written similar to C++ iterators:
for (DBIDIter iter = ids.iter(); iter.valid(); iter.advance()) {
collection.add(iter); // E.g., Add the reference to a collection
relation.get(iter); // E.g., Get the referenced object
}
In contrast to typical Java iterators (which can only iterate over objects), this conserves memory, because the iterator can internally use primitive values for data storage. The reduced garbage collection improves the runtime. Optimized collections libraries such as GNU Trove3, Koloboke, and fastutil employ similar optimizations. ELKI includes data structures such as object collections and heaps (for, e.g., nearest neighbor search) using such optimizations.
Visualization
The visualization module uses SVG for scalable graphics output, and Apache Batik for rendering of the user interface as well as lossless export into PostScript and PDF for easy inclusion in scientific publications in LaTeX. Exported files can be edited with SVG editors such as Inkscape. Since cascading style sheets are used, the graphics design can be restyled easily. Unfortunately, Batik is rather slow and memory intensive, so the visualizations are not very scalable to large data sets.
Awards
Version 0.4, presented at the "Symposium on Spatial and Temporal Databases" 2011, which included various methods for spatial outlier detection,[9] won the conference's "best demonstration paper award".
Included algorithms
Select included algorithms:[10]
- Cluster analysis:
- K-means clustering
- K-medians clustering
- Expectation-maximization algorithm
- Hierarchical clustering (including SLINK and CLINK)
- Single-linkage clustering
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise, with full index acceleration for arbitrary distance functions)
- OPTICS (Ordering Points To Identify the Clustering Structure), including the extensions OPTICS-OF, DeLi-Clu, HiSC, HiCO and DiSH
- SUBCLU (Density-Connected Subspace Clustering for High-Dimensional Data)
- Canopy clustering algorithm
- Anomaly detection:
- Spatial index structures:
- Evaluation:
- Receiver operating characteristic (ROC curve)
- Scatter plot
- Histogram
- Parallel coordinates (also in 3D, using OpenGL)
- Other:
Version history
Version 0.1 (July 2008) contained several Algorithms from cluster analysis and anomaly detection, as well as some index structures such as the R*-tree. The focus of the first release was on subspace clustering and correlation clustering algorithms.[11]
Version 0.2 (July 2009) added functionality for time series analysis, in particular distance functions for time series.[12]
Version 0.3 (March 2010) extended the choice of anomaly detection algorithms and visualization modules.[13]
Version 0.4 (September 2011) added algorithms for geo data mining and support for multi-relational database and index structures.[9]
Version 0.5 (April 2012) focuses on the evaluation of cluster analysis results, adding new visualizations and some new algorithms.[14]
Version 0.6 (June 2013) introduces a new 3D adaption of parallel coordinates for data visualization, apart from the usual additions of algorithms and index structures.[15]
Version 0.7 (August 2015) adds support for uncertain data types, and algorithms for the analysis of uncertain data.[16]
Related applications
- Weka: A similar project by the University of Waikato, with a focus on classification algorithms.
- RapidMiner: An application available commercially (an old version is available as open-source, too) with a focus on machine learning.
- KNIME: An open source platform which integrates various components for machine learning and data mining.
References
- ↑ Hans-Peter Kriegel, Peer Kröger, Arthur Zimek (2009). "Outlier Detection Techniques (Tutorial)" (PDF). 13th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2009). Bangkok, Thailand. Retrieved 2010-03-26.
- ↑ Gero, Shane; Whitehead, Hal; Rendell, Luke (2016). "Individual, unit and vocal clan level identity cues in sperm whale codas". Royal Society Open Science. 3 (1): 150372. ISSN 2054-5703. doi:10.1098/rsos.150372.
- ↑ Stahlberg, Felix; Schlippe, Tim; Vogel, Stephan; Schultz, Tanja (2013). "Pronunciation Extraction from Phoneme Sequences through Cross-Lingual Word-to-Phoneme Alignment". 7978: 260–272. ISSN 0302-9743. doi:10.1007/978-3-642-39593-2_23.
- ↑ Verzola, Ivano; Donati, Alessandro; Martinez, Jose; Schubert, Matthias; Somodi, Laszlo (2016). "Project Sibyl: A Novelty Detection System for Human Spaceflight Operations". doi:10.2514/6.2016-2405.
- ↑ Adham, Manal T.; Bentley, Peter J. (2016). "Evaluating clustering methods within the Artificial Ecosystem Algorithm and their application to bike redistribution in London". Biosystems. 146: 43–59. ISSN 0303-2647. doi:10.1016/j.biosystems.2016.04.008.
- ↑ Wisely, Michael; Hurson, Ali; Sarvestani, Sahra Sedigh (2015). "An extensible simulation framework for evaluating centralized traffic prediction algorithms": 391–396. doi:10.1109/ICCVE.2015.86.
- ↑ Kriegel, Hans-Peter; Schubert, Erich; Zimek, Arthur (2016). "The (black) art of runtime evaluation: Are we comparing algorithms or implementations?". Knowledge and Information Systems. ISSN 0219-1377. doi:10.1007/s10115-016-1004-2.
- ↑ "DBIDs". ELKI homepage. Retrieved 13 December 2016.
- 1 2 Elke Achtert, Achmed Hettab, Hans-Peter Kriegel, Erich Schubert, Arthur Zimek (2011). Spatial Outlier Detection: Data, Algorithms, Visualizations. 12th International Symposium on Spatial and Temporal Databases (SSTD 2011). Minneapolis, MN: Spinger. doi:10.1007/978-3-642-22922-0_41.
- ↑ excerpt from "Data Mining Algorithms in ELKI 0.4". Retrieved August 17, 2011.
- ↑ Elke Achtert, Hans-Peter Kriegel, Arthur Zimek (2008). ELKI: A Software System for Evaluation of Subspace Clustering Algorithms (PDF). Proceedings of the 20th international conference on Scientific and Statistical Database Management (SSDBM 08). Hong Kong, China: Springer. doi:10.1007/978-3-540-69497-7_41.
- ↑ Elke Achtert, Thomas Bernecker, Hans-Peter Kriegel, Erich Schubert, Arthur Zimek (2009). ELKI in time: ELKI 0.2 for the performance evaluation of distance measures for time series (PDF). Proceedings of the 11th International Symposium on Advances in Spatial and Temporal Databases (SSTD 2010). Aalborg, Dänemark: Springer. doi:10.1007/978-3-642-02982-0_35.
- ↑ Elke Achtert, Hans-Peter Kriegel, Lisa Reichert, Erich Schubert, Remigius Wojdanowski, Arthur Zimek (2010). Visual Evaluation of Outlier Detection Models. 15th International Conference on Database Systems for Advanced Applications (DASFAA 2010). Tsukuba, Japan: Spinger. doi:10.1007/978-3-642-12098-5_34.
- ↑ Elke Achtert, Sascha Goldhofer, Hans-Peter Kriegel, Erich Schubert, Arthur Zimek (2012). Evaluation of Clusterings Metrics and Visual Support. 28th International Conference on Data Engineering (ICDE). Washington, DC. doi:10.1109/ICDE.2012.128.
- ↑ Elke Achtert, Hans-Peter Kriegel, Erich Schubert, Arthur Zimek (2013). Interactive Data Mining with 3D-Parallel-Coordinate-Trees. Proceedings of the ACM International Conference on Management of Data (SIGMOD). New York City, NY. doi:10.1145/2463676.2463696.
- ↑ Erich Schubert; Alexander Koos; Tobias Emrich; Andreas Züfle; Klaus Arthur Schmid; Arthur Zimek (2015). "A Framework for Clustering Uncertain Data." (PDF). Proceedings of the VLDB Endowment. 8 (12): 1976–1987.
External links
- Official website of ELKI with download and documentation.