Data-driven journalism
Data-driven journalism, often shortened to "ddj", is a term in use since 2009, to describe a journalistic process based on analyzing and filtering large data sets for the purpose of creating a news story. Main drivers for this process are newly available resources such as open source software, open access publishing and open data. This approach to journalism builds on older practices, most notably on CAR (acronym for "computer-assisted reporting") a label used mainly in the US for decades. Other labels for partially similar approaches are "precision journalism", based on a book by Philipp Meyer, published in 1972, where he advocated the use of techniques from social sciences in researching stories.
Data-driven journalism has an even wider approach. At the core the process builds on the growing availability of open data that is freely available online and analyzed with open source tools.[1] Data-driven journalism strives to reach new levels of service for the public, helping consumers, managers, politicians to understand patterns and make decisions based on the findings. As such, data driven journalism might help to put journalists into a role relevant for society in a new way.
As projects like the MP Expense Scandal (2009) and the 2013 release of the "Offshore leaks" demonstrate, data-driven journalism can assume an investigative role, dealing with "not-so open" aka secret data on occasion.
Definitions
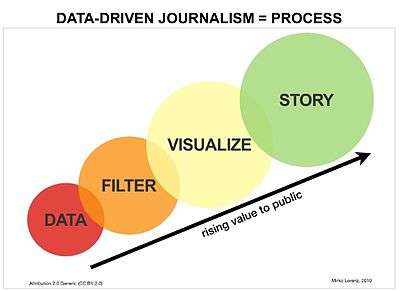
According to information architect and multimedia journalist Mirko Lorenz, data-driven journalism is primarily a workflow that consists of the following elements: digging deep into data by scraping, cleansing and structuring it, filtering by mining for specific information, visualizing and making a story.[2] This process can be extended to provide information results that cater to individual interests and the broader public.
Data journalism trainer and writer Paul Bradshaw describes the process of data-driven journalism in a similar manner: data must be found, which may require specialized skills like MySQL or Python, then interrogated, for which understanding of jargon and statistics is necessary, and finally visualized and mashed with the aid of open source tools.[3]
A more results driven definition comes from data reporter and web strategist Henk van Ess (2012).[4] "Data-driven journalism enables reporters to tell untold stories, find new angles or complete stories via a workflow of finding, processing and presenting significant amounts of data (in any given form) with or without open source tools." Van Ess claims that some of the data-driven workflow leads to products that "are not in orbit with the laws of good story telling" because the result emphazes on showing the problem, not explaining the problem. "A good data driven production has different layers. It allows you to find personalized details that are only important for you, by drilling down to relevant details but also enables you to zoom out to get the big picture".
In 2013, Van Ess came with a shorter definition in [5] that doesn't involve visualisation per se:
"Datajournalism is journalism based on data that has to be processed first with tools before a relevant story is possible."
Reporting based on data
Telling stories based on the data is the primary goal. The findings from data can be transformed into any form of journalistic writing. Visualizations can be used to create a clear understanding of a complex situation. Furthermore, elements of storytelling can be used to illustrate what the findings actually mean, from the perspective of someone who is affected by a development. This connection between data and story can be viewed as a "new arc" trying to span the gap between developments that are relevant, but poorly understood, to a story that is verifiable, trustworthy, relevant and easy to remember.
Data quality
In many investigations the data that can be found might have omissions or is misleading. As one layer of data-driven journalism a critical examination of the data quality is important. In other cases the data might not be public or is not in the right format for further analysis, e.g. is only available in a PDF. Here the process of data-driven journalism can turn into stories about data quality or refusals to provide the data by institutions. As the practice as a whole is in early development steps, examinations of data sources, data sets, data quality and data format are therefore an equally important part of this work.
Data-driven journalism and the value of trust
Based on the perspective of looking deeper into facts and drivers of events, there is a suggested change in media strategies: In this view the idea is to move "from attention to trust". The creation of attention, which has been a pillar of media business models has lost its relevance because reports of new events are often faster distributed via new platforms such as Twitter than through traditional media channels. On the other hand, trust can be understood as a scarce resource. While distributing information is much easier and faster via the web, the abundance of offerings creates costs to verify and check the content of any story create an opportunity. The view to transform media companies into trusted data hubs has been described in an article cross-published in February 2011 on Owni.eu[6] and Nieman Lab.[7]
Process of data-driven journalism
The process to transform raw data into stories is akin to a refinement and transformation. The main goal is to extract information recipients can act upon. The task of a data journalist is to extract what is hidden. This approach can be applied to almost any context, such as finances, health, environment or other areas of public interest.
Inverted pyramid of data journalism
In 2011, Paul Bradshaw introduced a model, he called "The Inverted Pyramid of Data Journalism".
Steps of the process
In order to achieve this, the process should be split up into several steps. While the steps leading to results can differ, a basic distinction can be made by looking at six phases:
- Find: Searching for data on the web
- Clean: Process to filter and transform data, preparation for visualization
- Visualize: Displaying the pattern, either as a static or animated visual
- Publish: Integrating the visuals, attaching data to stories
- Distribute: Enabling access on a variety of devices, such as the web, tablets and mobile
- Measure: Tracking usage of data stories over time and across the spectrum of uses.
Description of the steps
Find data
Data can be obtained directly from governmental databases such as data.gov, data.gov.uk and World Bank Data API[8] but also by placing Freedom of Information requests to government agencies; some requests are made and aggregated on websites like the UK's What Do They Know. While there is a worldwide trend towards opening data, there are national differences as to what extent that information is freely available in usable formats. If the data is in a webpage, scrapers are used to generate a spreadsheet. Examples of scrapers are: Import.io, ScraperWiki, Firefox plugin OutWit Hub or Needlebase (retired in 2012[9]). In other cases OCR-Software can be used to get data from PDFs.
Data can also be created by the public through crowd sourcing, as shown in March 2012 at the Datajournalism Conference in Hamburg by Henk van Ess [10]
Clean data
Usually data is not in a format that is easy to visualize. Examples being that there are too many data points or that the rows and columns need to be sorted differently. Another issue is that once investigated many datasets need to be cleaned, structured and transformed. Various tools like Google Refine (open source), Data Wrangler and Google Spreadsheets[11] allow uploading, extracting or formatting data.
Visualize data
To visualize data in the form of graphs and charts, applications such as Many Eyes or Tableau Public are available. Yahoo! Pipes and Open Heat Map[12] are examples of tools that enable the creation of maps based on data spreadsheets. The number of options and platforms is expanding. Some new offerings provide options to search, display and embed data, an example being Timetric.[13]
To create meaningful and relevant visualizations, journalists use a growing number of tools. There are by now, several descriptions what to look for and how to do it. Most notable published articles are:
- Joel Gunter: #ijf11: Lessons in data journalism from the New York Times, published on Journalism.co.uk (April 16, 2011)[14]
- Steve Myers: Using Data Visualization as a Reporting Tool Can Reveal Story’s Shape, published on Poynter (April 10, 2009, updated March 4, 2011), including a link to a tutorial by Sarah Cohen[15]
As of 2011, the use of HTML 5 libraries using the canvas tag is gaining in popularity. There are numerous libraries enabling to graph data in a growing variety of forms. One example here would be RGraph.[16] As of 2011 there is a growing list of JavaScript libraries allowing to visualize data.
Publish data story
There are different options to publish data and visualizations. A basic approach is to attach the data to single stories, similar to embedding web videos. More advanced concepts allow to create single dossiers, e.g. to display a number of visualizations, articles and links to the data on one page. Often such specials have to be coded individually, as many Content Management Systems are designed to display single posts based on the date of publication.
Distribute data
Providing access to existing data is another phase, which is gaining importance. Think of the sites as "marketplaces" (commercial or not), where datasets can be found easily by others. Especially of the insights for an article where gained from Open Data, journalists should provide a link to the data they used for others to investigate (potentially starting another cycle of interrogation, leading to new insights).
Providing access to data and enabling groups to discuss what information could be extracted is the main idea behind Buzzdata,[17] a site using the concepts of social media such as sharing and following to create a community for data investigations.
Other platforms (which can be used both to gather or to distribute data):
- Help Me Investigate (created by Paul Bradshaw)[18]
- Timetric[19]
- ScraperWiki[20]
Measuring the impact of data stories
A final step of the process is to measure how often a dataset or visualization is viewed.
In the context of data-driven journalism, the extent of such tracking, such as collecting user data or any other information that could be used for marketing reasons or other uses beyond the control of the user, should be viewed as problematic. One newer, non-intrusive option to measure usage is a lightweight tracker called PixelPing. The tracker is the result of a project by ProPublica and DocumentCloud.[21] There is a corresponding service to collect the data. The software is open source and can be downloaded via GitHub.[22]
Examples
There is a growing list of examples how data-driven journalism can be applied:
- The Guardian, being one of the pioneering media companies in this space (see: Data journalism at the Guardian: what is it and how do we do it?),[23] has compiled an extensive list of data stories, see: All of our data journalism in one spreadsheet[24]
Other prominent uses of data driven journalism is related to the release by whistle-blower organization WikiLeaks of the Afghan War Diary, a compendium of 91,000 secret military reports covering the war in Afghanistan from 2004 to 2010.[25] Three global broadsheets, namely The Guardian, The New York Times and Der Spiegel, dedicated extensive sections[26][27][28] to the documents; The Guardian's reporting included an interactive map pointing out the type, location and casualties caused by 16,000 IED attacks,[29] The New York Times published a selection of reports that permits rolling over underlined text to reveal explanations of military terms,[30] while Der Spiegel provided hybrid visualizations (containing both graphs and maps) on topics like the number deaths related to insurgent bomb attacks.[31] For the Iraq War logs release, The Guardian used Google Fusion Tables to create an interactive map of every incident where someone died,[32] a technique it used again in the England riots of 2011.[33]
See also
- Database journalism
- Data journalism
- Computational journalism
- Geojournalism
- Open science data
- Open source
- Open knowledge
- Freedom of information legislation
- Information visualization
References
- ↑ Lorenz, Mirko (2010) Data driven journalism: What is there to learn? Edited conference documentation, based on presentations of participants, 24 August 2010, Amsterdam, The Netherlands
- ↑ Lorenz, Mirko. (2010). Data driven journalism: What is there to learn? Presented at IJ-7 Innovation Journalism Conference, 7–9 June 2010, Stanford, CA
- ↑ Bradshaw, Paul (1 October 2010). How to be a data journalist. The Guardian
- ↑ van Ess, Henk. (2012). Gory details of data driven journalism
- ↑ van Ess, Henk. (2013). Handboek Datajournalistiek
- ↑ Media Companies Must Become Trusted Data Hubs » OWNI.eu, News, Augmented. Owni.eu (2011-02-28). Retrieved on 2013-08-16.
- ↑ Voices: News organizations must become hubs of trusted data in a market seeking (and valuing) trust » Nieman Journalism Lab. Niemanlab.org (2013-08-09). Retrieved on 2013-08-16.
- ↑ World Bank Data API
- ↑ http://googleblog.blogspot.de/2012/01/renewing-old-resolutions-for-new-year.html (accessed June 16, 2015)
- ↑ Crowdsourcing: how to find a crowd (Presented at ARD/ZDF Academy in. Slideshare.net (2010-09-17). Retrieved on 2013-08-16.
- ↑ Data Scraping Wikipedia with Google Spreadsheets | OUseful.Info, the blog. Blog.ouseful.info. Retrieved on 2013-08-16.
- ↑ OpenHeatMap. OpenHeatMap. Retrieved on 2013-08-16.
- ↑ Critical Intelligence for Key Sectors. timetric.com. Retrieved on 2013-08-16.
- ↑ #ijf11: Lessons in data journalism from the New York Times | Editors Blog | Journalism.co.uk. Blogs.journalism.co.uk (2011-04-16). Retrieved on 2013-08-16.
- ↑ Using Data Visualization as a Reporting Tool Can Reveal Story’s Shape | Poynter. Poynter.. Retrieved on 2013-08-16.
- ↑ Free HTML5 and JavaScript charts. RGraph. Retrieved on 2013-08-16.
- ↑ BuzzData. BuzzData. Retrieved on 2013-08-16.
- ↑ A network helping people investigate questions in the public interest. Help Me Investigate (2006-04-04). Retrieved on 2013-08-16.
- ↑ Critical Intelligence for Key Sectors. timetric.com. Retrieved on 2013-08-16.
- ↑ ScraperWiki. ScraperWiki. Retrieved on 2013-08-16.
- ↑ Larson, Jeff. (2010-09-08) Pixel Ping: A node.js Stats Tracker. ProPublica. Retrieved on 2013-08-16.
- ↑ documentcloud/pixel-ping ¡ GitHub. Github.com. Retrieved on 2013-08-16.
- ↑ Rogers, Simon (2011) https://www.theguardian.com/news/datablog/2011/jul/28/data-journalism
- ↑ Evans, Lisa (2011) https://www.theguardian.com/news/datablog/2011/jan/27/data-store-office-for-national-statistics
- ↑ Kabul War Diary, 26 July 2010, WikiLeaks
- ↑ Afghanistan The War Logs, 26 July 2010, The Guardian
- ↑ The War Logs, 26 July 2010 The New York Times
- ↑ The Afghanistan Protocol: Explosive Leaks Provide Image of War from Those Fighting It, 26 July 2010, Der Spiegel
- ↑ Afghanistan war logs: IED attacks on civilians, coalition and Afghan troops, 26 July 2010, The Guardian
- ↑ Text From a Selection of the Secret Dispatches, 26 July 2010, The New York Times
- ↑ Deathly Toll: Death as a result of insurgent bomb attacks, 26 July 2010, Der Spiegel
- ↑ Wikileaks Iraq war logs: every death mapped, 22 October 2010, Guardian Datablog
- ↑ UK riots: every verified incident - interactive map, 11 August 2011, Guardian Datablog