DIET
|
| |
| Developer(s) | INRIA, École Normale Supérieure de Lyon, SysFera, CNRS, Claude Bernard University Lyon 1 |
|---|---|
| Stable release |
2.8
/ 11/14/11 |
| Written in | C++, CORBA |
| Operating system | Cross-platform |
| Type | Grid and Cloud computing |
| License | CeCILL |
| Website |
graal |
DIET is a software for grid-computing. As middleware, DIET sits between the operating system (which handles the details of the hardware) and the application software (which deals with the specific computational task at hand). DIET was created in 2000.[1] It was designed for high-performance computing. It is currently developed by INRIA, École Normale Supérieure de Lyon, CNRS, Claude Bernard University Lyon 1, SysFera. It is open-source software released under the CeCILL license.
Like NetSolve/GridSolve and Ninf, DIET is compliant with the GridRPC standard from the Open Grid Forum.[2]
The aim of the DIET project is to develop a set of tools to build computational servers. The distributed resources are managed in a transparent way through the middleware. It can work with workstations, clusters, Grids and clouds.
DIET is used to manage the Décrypthon Grid installed by IBM in six French universities (Bordeaux 1, Lille 1, Paris 6, ENS Lyon, Crihan in Rouen, Orsay).
Architecture
Usually, GridRPC environments have five different components: clients that submit problems to servers, servers that solve the problems sent by clients, a database that contains information about software and hardware resources, a scheduler that chooses an appropriate server depending on the problem sent and the information contained in the database, and monitors that get information about the status of the computational resources.
DIET's architecture follows a different design. It is composed of:
- a client - the application that uses DIET to solve problems. Clients can connect to DIET from a web page or through an API or compiled program.
- a Master Agent (MA) that receives computation requests from clients. The MA then collects computation abilities from the servers and chooses one based on scheduling criteria. The reference of the chosen server is returned to the client. A client can be connected to an MA by a specific name server or a web page that stores the various MA locations.
- a Local Agent (LA) that aims at transmitting requests and information between MAs and servers. The information stored on an LA is the list of requests and, for each of its subtrees, the number of servers that can solve a given problem and information about the data distributed in this subtree. Depending on the underlying network topology, a hierarchy of LAs may be deployed between an MA and the servers.
- a Server Daemon (SeD) that is the point of entry of a computational server. It manages a processor or a cluster. The information stored on a SeD is the list of the data available on a server (possibly with their distribution and the way to access them), the list of the problems than can be solved on it, and all the information concerning its load (e.g., CPU capacity, available memory).
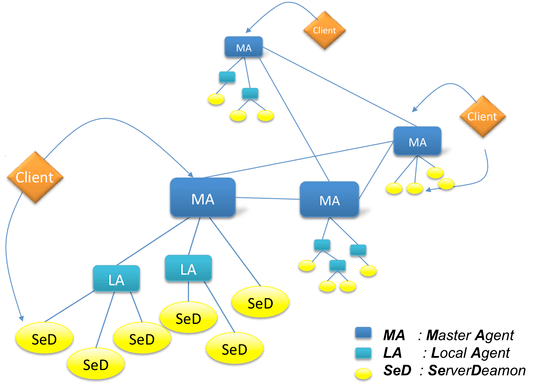
Multi-hierarchy
Two approaches were developed:
- a multi-MA extension was developed by the University of Franche-Comté. Those Master Agents are connected by a communication graph. Several DIET platforms are shared by interconnecting their respective Master Agent (MA). Clients request available SeDs from their MA as usual. If the MA finds an available SeD able to resolve the problem, it returns its reference to the client. If it does not find a SeD, it forwards the request to other MAs which can also forward it to other ones, and so on. When a MA finds a SeD which can resolve the client's request, it returns its reference to the client's MA which returns the reference to the client. The client can then use that SeD to resolve its problem.
- a P2P Multi-MA extension called DIET_j was also designed. The aggregation of different independent DIET hierarchies (a multi-hierarchy architecture) could be managed using the P2P paradigm. This approach was based on the JXTA-J2SE toolbox for the on-demand discovery and connection of MAs. This project is no longer maintained.
Workflow management
For workflow management, DIET uses an additional entity called MA DAG. This entity can work in two modes: one in which it defines a complete scheduling of the workflow (ordering and mapping), and one in which it defines only an ordering for the workflow execution. Mapping is then done in the next step by the client, using the Master Agent to find the server where the workflow services should be run.

Scheduling
DIET provides a degree of control over the scheduling subsystem via plug-in schedulers.[3] When a service request from an application arrives at a SeD, the SeD creates a performance-estimation vector, a collection of performance-estimation values that are pertinent to the scheduling process for that application. The values to be stored in this structure can be either values provided by CoRI (Collectors of Resource Information) or custom values generated by the SeD itself. The design of the estimation vector's subsystem is modular.
CoRI generates a basic set of performance-estimation values which are stored in the estimation vector and identified by system-defined tags. Information such as the number of cores, the total memory, the number of bogomips, and hard drive speed, etc., which are static, as well as dynamic information like the predicted time to solve a problem on the given resource, the average CPU load, is thus transferred from the Server Daemon to the scheduler agent in order to provide pertinent information for a better scheduling. As mentioned above, these are used in correlation with the application-driven scheduler possibility in DIET: the Server Daemon, which has a better understanding of the application needs, can request for a specific scheduling relaying on the information stored in this vector.
DIET data management
Three different data managers have been integrated into DIET:
- DTM from the University of Franche-Comté (not maintained);
- JuxMEM from the IRISA (not maintained);[4]
- DAGDA from École Normale Supérieure de Lyon.

DIET LRMS management
Parallel resources are generally accessible through a LRMS (Local Resource Management System), also called a batch system. DIET provides an interface with several existing LRMS to execute jobs: LoadLeveler (on IBM resources), OpenPBS (a fork of the well-known PBS system), and OAR (the batch scheduler used by the Grid'5000 research grid, developed by IMAG at Grenoble). Most of the submitted jobs are parallel jobs, coded using the MPI standard with an instantiation such as MPICH or LAM.
Cloud-resource management
A Cloud extension for DIET was created in 2009.[5] DIET is thus able to access Cloud resources through two existing Cloud providers:
- Eucalyptus, which is open-source software developed by the University of California, Santa Barbara.
- Amazon Elastic Compute Cloud, which is commercial software part of Amazon.com's cloud computing services.
References
- ↑ Caron, Eddy; Desprez, Frédéric (2006). "DIET: A Scalable Toolbox to Build Network Enabled Servers on the Grid". International Journal of High Performance Computing Applications. 20 (3): 335–352. doi:10.1177/1094342006067472.
- ↑ Caniou, Yves; Caron, Eddy; Desprez, Frédéric; Nakada, Hidemoto; Seymour, Keith; Tanaka, Yoshio (2009). Grid Technology and Applications: Recent Developments. Chapter: High performance GridRPC middleware. Nova Science Publishers. ISBN 978-1-60692-768-7.
- ↑ Caron, Eddy; Chis, Andréea; Desprez, Frédéric; Su, Alan (January 2008). "Design of plug-in schedulers for a GridRPC environment". Future Generation Computer Systems. 24 (1): 46–57. doi:10.1016/j.future.2007.02.005.
- ↑ Antoniu, Gabriel; Bougé, Luc; Jan, Mathieu (November 2005). "JuxMem: An Adaptive Supportive Platform for Data Sharing on the Grid". Scalable Computing: Practice and Experience. 6 (3): 45–55.
- ↑ Caron, Eddy; Desprez, Frédéric; Loureiro, David; Muresan, Adrian (September 2009). "Cloud Computing Resource Management through a Grid Middleware: A Case Study with DIET and Eucalyptus". IEEE International Conference on Cloud Computing (CLOUD 2009).