Activation function
In computational networks, the activation function of a node defines the output of that node given an input or set of inputs. A standard computer chip circuit can be seen as a digital network of activation functions that can be "ON" (1) or "OFF" (0), depending on input. This is similar to the behavior of the linear perceptron in neural networks. However, only nonlinear activation functions allow such networks to compute nontrivial problems using only a small number of nodes. In artificial neural networks this function is also called the transfer function.
Functions
In biologically inspired neural networks, the activation function is usually an abstraction representing the rate of action potential firing in the cell. In its simplest form, this function is binary—that is, either the neuron is firing or not. The function looks like , where is the Heaviside step function. In this case many neurons must be used in computation beyond linear separation of categories.


A line of positive slope may be used to reflect the increase in firing rate that occurs as input current increases. Such a function would be of the form , where is the slope. This activation function is linear, and therefore has the same problems as the binary function. In addition, networks constructed using this model have unstable convergence because neuron inputs along favored paths tend to increase without bound, as this function is not normalizable.


All problems mentioned above can be handled by using a normalizable sigmoid activation function. One realistic model stays at zero until input current is received, at which point the firing frequency increases quickly at first, but gradually approaches an asymptote at 100% firing rate. Mathematically, this looks like , where the hyperbolic tangent function can be replaced by any sigmoid function. This behavior is realistically reflected in the neuron, as neurons cannot physically fire faster than a certain rate. This model runs into problems, however, in computational networks as it is not differentiable, a requirement to calculate backpropagation.

The final model, then, that is used in multilayer perceptrons is a sigmoidal activation function in the form of a hyperbolic tangent. Two forms of this function are commonly used: whose range is normalized from -1 to 1, and is vertically translated to normalize from 0 to 1. The latter model is often considered more biologically realistic, but it runs into theoretical and experimental difficulties with certain types of computational problems.


Alternative structures
A special class of activation functions known as radial basis functions (RBFs) are used in RBF networks, which are extremely efficient as universal function approximators. These activation functions can take many forms, but they are usually found as one of three functions:
- Gaussian:
- Multiquadratics:
- Inverse multiquadratics:



where is the vector representing the function center and and are parameters affecting the spread of the radius.



Support vector machines (SVMs) can effectively utilize a class of activation functions that includes both sigmoids and RBFs. In this case, the input is transformed to reflect a decision boundary hyperplane based on a few training inputs called support vectors . The activation function for the hidden layer of these machines is referred to as the inner product kernel, . The support vectors are represented as the centers in RBFs with the kernel equal to the activation function, but they take a unique form in the perceptron as


- ,

where and must satisfy certain conditions for convergence. These machines can also accept arbitrary-order polynomial activation functions where


- .[1]

Activation function having types:
- Identity function
- Binary step function
- Bipolar step function
- Sigmoidal function
- Binary sigmoidal function
- Bipolar sigmoidal function
- Ramp function
Comparison of activation functions
Some desirable properties in an activation function include:
- Nonlinear – When the activation function is non-linear, then a two-layer neural network can be proven to be a universal function approximator.[2] The identity activation function does not satisfy this property. When multiple layers use the identity activation function, the entire network is equivalent to a single-layer model.
- Continuously differentiable – This property is necessary for enabling gradient-based optimization methods. The binary step activation function is not differentiable at 0, and it differentiates to 0 for all other values, so gradient-based methods can make no progress with it.[3]
- Range – When the range of the activation function is finite, gradient-based training methods tend to be more stable, because pattern presentations significantly affect only limited weights. When the range is infinite, training is generally more efficient because pattern presentations significantly affect most of the weights. In the latter case, smaller learning rates are typically necessary.
- Monotonic – When the activation function is monotonic, the error surface associated with a single-layer model is guaranteed to be convex.[4]
- Smooth Functions with a Monotonic derivative – These have been shown to generalize better in some cases. The argument for these properties suggests that such activation functions are more consistent with Occam's razor.[5]
- Approximates identity near the origin – When activation functions have this property, the neural network will learn efficiently when its weights are initialized with small random values. When the activation function does not approximate identity near the origin, special care must be used when initializing the weights.[6] In the table below, activation functions where and and is continuous at 0 are indicated as having this property.



The following table compares the properties of several activation functions that are functions of one fold x from the previous layer or layers:
| Name | Plot | Equation | Derivative (with respect to x) | Range | Order of continuity | Monotonic | Derivative Monotonic | Approximates identity near the origin |
|---|---|---|---|---|---|---|---|---|
| Identity |  |
Yes | Yes | Yes | ||||
| Binary step |  |
Yes | No | No | ||||
| Logistic (a.k.a. Soft step) |  |
Yes | No | No | ||||
| TanH |  |
Yes | No | Yes | ||||
| ArcTan | 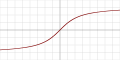 |
Yes | No | Yes | ||||
| Softsign [7][8] |  |
Yes | No | Yes | ||||
| Rectified linear unit (ReLU)[9] |  |
Yes | Yes | No | ||||
| Leaky rectified linear unit (Leaky ReLU)[10] |  |
Yes | Yes | No | ||||
| Parameteric rectified linear unit (PReLU)[11] | |
Yes iff | Yes | Yes iff | ||||
| Randomized leaky rectified linear unit (RReLU)[12] | |
Yes | Yes | No | ||||
| Exponential linear unit (ELU)[13] | 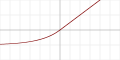 |
when , otherwise |
Yes iff | Yes iff | Yes iff | |||
| Scaled exponential linear unit (SELU)[14] |
with and |
Yes | No | No | ||||
| S-shaped rectified linear activation unit (SReLU)[15] | are parameters. |
No | No | No | ||||
| Adaptive piecewise linear (APL) [16] | No | No | No | |||||
| SoftPlus[17] |  |
Yes | Yes | No | ||||
| Bent identity |  |
Yes | Yes | Yes | ||||
| SoftExponential [18] |  |
Yes | Yes | Yes iff | ||||
| Sinusoid |  |
No | No | Yes | ||||
| Sinc |  |
No | No | No | ||||
| Gaussian |  |
No | No | No |






















































![[-1,1]](../I/m/51e3b7f14a6f70e614728c583409a0b9a8b9de01.svg)


![{\displaystyle [\approx -.217234,1]}](../I/m/7813b154f09cf5aa32f9fa13dc519fd85b1df60a.svg)


![{\displaystyle (0,1]}](../I/m/7e70f9c241f9faa8e9fdda2e8b238e288807d7a4.svg)
- ^ Here, H is the Heaviside step function.
- ^ is a stochastic variable sampled from a uniform distribution at training time and fixed to the expectation value of the distribution at test time.

The following table lists activation functions that are not functions of a single fold x from the previous layer or layers:
| Name | Equation | Derivatives | Range | Order of continuity |
|---|---|---|---|---|
| Softmax | for i = 1, …, J | |||
| Maxout[19] |




^ Here, is the Kronecker delta.

See also
References
- ↑ Haykin, Simon S. (1999). Neural Networks: A Comprehensive Foundation. Prentice Hall. ISBN 978-0-13-273350-2.
- ↑ Cybenko, G.V. (2006). "Approximation by Superpositions of a Sigmoidal function". In van Schuppen, Jan H. Mathematics of Control, Signals, and Systems. Springer International. pp. 303–314.
- ↑ Snyman, Jan (3 March 2005). Practical Mathematical Optimization: An Introduction to Basic Optimization Theory and Classical and New Gradient-Based Algorithms. Springer Science & Business Media. ISBN 978-0-387-24348-1.
- ↑ Wu, Huaiqin. "Global stability analysis of a general class of discontinuous neural networks with linear growth activation functions". Information Sciences. 179 (19): 3432–3441. doi:10.1016/j.ins.2009.06.006.
- ↑ Gashler, Michael S.; Ashmore, Stephen C. (2014-05-09). "Training Deep Fourier Neural Networks To Fit Time-Series Data". arXiv:1405.2262 [cs].
- ↑ Sussillo, David; Abbott, L. F. (2014-12-19). "Random Walk Initialization for Training Very Deep Feedforward Networks". arXiv:1412.6558 [cs, stat].
- ↑ Bergstra, James; Desjardins, Guillaume; Lamblin, Pascal; Bengio, Yoshua (2009). "Quadratic polynomials learn better image features". Technical Report 1337". Département d’Informatique et de Recherche Opérationnelle, Université de Montréal.
- ↑ Glorot, Xavier; Bengio, Yoshua (2010), "Understanding the difficulty of training deep feedforward neural networks" (PDF), International Conference on Artificial Intelligence and Statistics (AISTATS’10), Society for Artificial Intelligence and Statistics
- ↑ Nair, Vinod; Hinton, Geoffrey E. (2010), "Rectified Linear Units Improve Restricted Boltzmann Machines", 27th International Conference on International Conference on Machine Learning, ICML'10, USA: Omnipress, pp. 807–814, ISBN 9781605589077
- ↑ Maas, Andrew L.; Hannun, Awni Y.; Ng, Andrew Y. (June 2013). "Rectifier nonlinearities improve neural network acoustic models" (PDF). Proc. ICML. 30 (1). Retrieved 2 January 2017.
- ↑ He, Kaiming; Zhang, Xiangyu; Ren, Shaoqing; Sun, Jian (2015-02-06). "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification". arXiv:1502.01852 [cs].
- ↑ Xu, Bing; Wang, Naiyan; Chen, Tianqi; Li, Mu (2015-05-04). "Empirical Evaluation of Rectified Activations in Convolutional Network". arXiv:1505.00853 [cs, stat].
- ↑ Clevert, Djork-Arné; Unterthiner, Thomas; Hochreiter, Sepp (2015-11-23). "Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs)". arXiv:1511.07289 [cs].
- ↑ Klambauer, Günter; Unterthiner, Thomas; Mayr, Andreas; Hochreiter, Sepp (2017-06-08). "Self-Normalizing Neural Networks". arXiv:1706.02515 [cs, stat].
- ↑ Jin, Xiaojie; Xu, Chunyan; Feng, Jiashi; Wei, Yunchao; Xiong, Junjun; Yan, Shuicheng (2015-12-22). "Deep Learning with S-shaped Rectified Linear Activation Units". arXiv:1512.07030 [cs].
- ↑ Forest Agostinelli; Matthew Hoffman; Peter Sadowski; Pierre Baldi (21 Dec 2014). "Learning Activation Functions to Improve Deep Neural Networks". arXiv. Retrieved 2 January 2017.
- ↑ Glorot, Xavier; Bordes, Antoine; Bengio, Yoshua (2011). "International Conference on Artificial Intelligence and Statistics".
|contribution=ignored (help) - ↑ Godfrey, Luke B.; Gashler, Michael S. (2016-02-03), "7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management: KDIR", arXiv:1602.01321 [cs]: 481–486
|contribution=ignored (help) - ↑ Goodfellow, Ian J.; Warde-Farley, David; Mirza, Mehdi; Courville, Aaron; Bengio, Yoshua (2013-02-18). "Maxout Networks". arXiv:1302.4389 [cs, stat].