Word lists by frequency
Word lists by frequency are lists of a language's words grouped by frequency of occurrence within some given text corpus, either by levels or as a ranked list, serving the purpose of vocabulary acquisition. A word list by frequency "provides a rational basis for making sure that learners get the best return for their vocabulary learning effort", (Nation 1997) but is mainly intended for course writers, not directly for learners. Some major pitfalls are the corpus content, the corpus register, and the definition of "word". While word counting is a thousand years old, with still gigantic analysis done by hand in the mid-20th century, natural language electronic processing of large corpora such as movie subtitles (SUBTLEX megastudy) has accelerated the research field.
In computational linguistics, a frequency list is a sorted list of words (word types) together with their frequency, where frequency here usually means the number of occurrences in a given corpus, from which the rank, less meaningful, can be derived
| Type | Occurrences | Rank |
|---|---|---|
| the | 3789654 | 1st |
| he | 2098762 | 2nd |
| [...] | ||
| king | 57897 | 1,356th |
| boy | 56975 | 1,357th |
| [...] | ||
| stringyfy | 5 | 34,589th |
| [...] | ||
| transducionalify | 1 | 123,567th |
Methodology
Factors
Nation (Nation 1997) noted the incredible help provided by computing capabilities, making corpus analysis much easier. He cited several key issues which influence the construction of frequency lists:
- corpus representativeness
- word frequency and range
- treatment of word families
- treatment of idioms and fixed expressions
- range of information
- various other criteria
Corpora
- Traditional written corpus
Most of currently available studies are based on written texts.
- SUBTLEX movement
However, New et al. 2007 proposed to tap into the large number of subtitles available online to analyse large numbers of speeches. Brysbaert & New 2009 made a long critical evaluation of this traditional textual analysis approach, and support a move toward speech analysis and analysis of film subtitles available online. This has recently been followed by a handful of copy-cat studies, providing valuable frequency count analysis for various languages. Indeed, the SUBTLEX movement completed in five years full studies for French (New et al. 2007), American English (Brysbaert & New 2009; Brysbaert, New & Keuleers 2012), Dutch (Keuleers & New 2010), Chinese (Cai & Brysbaert 2010), Spanish (Cuetos et al. 2011), Greek (Dimitropoulou et al. Carreiras), Vietnamese (Pham, Bolger & Baayen 2011), and Polish[1]
Lexical unit
In any case, the basic "word" unit should be defined. For Latin scripts, words are usually one or several characters separated either by spaces or punctuation. But exceptions can arise, such as English "can't", French "aujourd'hui", or idioms. It may also be preferable to group words of a word family under the representation of its base word. Thus, possible, impossible, possibility are words of the same word family, represented by the base word *possib*. For statistical purpose, all these words are summed up under the base word form *possib*, allowing the ranking of a concept and form occurrence. Moreover, other languages may present specific difficulties. Such is the case of Chinese, which does not use spaces between words, and where a specified chain of several characters can be interpreted as either a phrase of unique-character words, or as a multi-character unique word.
Statistics
It seems that Zipf's law holds for frequency lists drawn from longer texts of any natural language. Frequency lists are a useful tool when building an electronic dictionary, which is a prerequisite for a wide range of applications in computational linguistics.
German linguists define the Häufigkeitsklasse (frequency class) 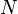 of an item in the list using the base 2 logarithm of the ratio between its frequency and the frequency of the most frequent item. The most common item belongs to frequency class 0 (zero) and any item that is approximately half as frequent belongs in class 1. In the example list above, the misspelled word outragious has a ratio of 76/3789654 and belongs in class 16.
of an item in the list using the base 2 logarithm of the ratio between its frequency and the frequency of the most frequent item. The most common item belongs to frequency class 0 (zero) and any item that is approximately half as frequent belongs in class 1. In the example list above, the misspelled word outragious has a ratio of 76/3789654 and belongs in class 16.

where  is the floor function.
is the floor function.
Frequency lists, together with semantic networks, are used to identify the least common, specialized terms to be replaced by their hypernyms in a process of semantic compression.
Pedagogy
Those lists are not intended to be given directly to students, but rather to serve as a guideline for teachers and book makers (Nation 1997). Paul Nation's modern language teaching summary encourages first to "move from high frequency vocabulary and special purposes [thematic] vocabulary to low frequency vocabulary, then to teach learners strategies to sustain autonomous vocabulary expansion" (Nation 2006la).
Effects of words frequency
Word frequency is known to have various effects (Brysbaert et al. Bölte; Rudell 1993). Memorization is positively affected by higher word frequency, likely because the learner is subject to more exposures (Laufer 1997). Lexical access is positively influenced by high word frequency (Segui, Mehler & Frauenfelder Morton1982).
Languages
Below is a review of available resources.
English
Word counting dates back to Hellenistic time. Thorndike & Lorge, assisted by their colleagues, counted 18,000,000 running words to provide the first large scale frequency list in 1944, before modern computers made such projects far easier (Nation 1997).
Traditional lists
These all suffer from their age. In particular, words relating to technology, such as "blog," which, in 2014, was #7665 in frequency[2] in the Corpus of Contemporary American English,[3] was first attested to in 1999,[4][5][6] and does not appear in any of these three lists.
- The Teachers Word Book of 30,000 words (Thorndike and Lorge, 1944)
The TWB contains 30,000 lemmas or ~13,000 word families (Goulden, Nation and Read, 1990). A corpus of 18,000,000 written words was hand analysed. The size of its source corpus increased its usefulness, but its age, and language changes, have reduced its applicability (Nation 1997).
- The General Service List (West, 1953)
The GSL contains 2,000 headwords divided into two sets of 1,000 words. A corpus of 5,000,000 written words was analyzed in the 1940s. The rate of occurrence (%) for different meanings, and parts of speech, of the headword are provided. Various criteria, other than frequence and range, were carefully applied to the corpus. Thus, despite its age, some errors, and its corpus being entirely written text, it is still an excellent database of word frequency, frequency of meanings, and reduction of noise (Nation 1997).
- The American Heritage Word Frequency Book (Carroll, Davies and Richman, 1971)
A corpus of 5,000,000 running words, from written texts used in United States schools (various grades, various subject areas). Its value is in its focus on school teaching materials, and its tagging of words by the frequency of each word, in each of the school grade, and in each of the subject areas (Nation 1997).
- The Brown (Francis and Kucera, 1982) LOB and related corpora
These now contain 1,000,000 words from a written corpora representing different dialects of English. These sources are used to produce frequency lists (Nation 1997).
French
- Traditional datasets
A review has been made by New & Pallier 3.01. An attempt was made in the 1950s–60s with the Français fondamental. It includes the F.F.1 list with 1,500 high-frequency words, completed by a later F.F.2 list with 1,700 mid-frequency words, and the most used syntax rules.[7] It is claimed that 70 grammatical words constitute 50% of the communicatives sentence,[8] while 3,680 words make about 95~98% of coverage.[9] A list of 3,000 frequent words is available.[10]
The French Ministry of the Education also provide a ranked list of the 1,500 most frequent word families, provided by the lexicologue Étienne Brunet.[11] Jean Baudot made a study on the model of the American Brown study, entitled "Fréquences d'utilisation des mots en français écrit contemporain".[12]
More recently, the project Lexique 3 provided a list of 135,000 French words, with orthography, phonetic, syllabation, part of speech, gender, number, frequency, associated lexemes, etc., available under an open-source license[13]
- Subtlex
New 2007 made a completely new counting based on online film subtitles.
Spanish
There have been several studies of Spanish word frequency (Cuetos et al. 2011).[14]
Chinese
As a frequency toolkit, Da (Da 1998) and the Taiwanese Ministry of Education (TME 1997) provided large databases with frequency ranks for characters and words. The HSK list of 8,848 high and medium frequency words in the People's Republic of China, and the Republic of China (Taiwan)'s TOP list of about 8,600 common traditional Chinese words are two other lists displaying common Chinese words and characters. Following the SUBTLEX movement, Cai & Brysbaert 2010 recently made a rich study of Chinese word and character frequencies.
See also
Notes
- ↑ http://www.ncbi.nlm.nih.gov/pubmed/24942246
- ↑ http://www.wordandphrase.info/frequencylist.asp
- ↑ http://corpus.byu.edu/coca/
- ↑ "It's the links, stupid". The Economist. 2006-04-20. Retrieved 2008-06-05.
- ↑ Merholz, Peter (1999). "Peterme.com". Internet Archive. Archived from the original on 1999-10-13. Retrieved 2008-06-05.
- ↑ Kottke, Jason (2003-08-26). "kottke.org". Retrieved 2008-06-05.
- ↑ "Le français fondamental". Archived from the original on July 4, 2010.
- ↑ Ouzoulias, André (2004), Comprendre et aider les enfants en difficulté scolaire: Le Vocabulaire fondamental, 70 mots essentiels (PDF), Retz - Citing V.A.C Henmon
- ↑ "Generalities".
- ↑ "PDF 3000 French words".
- ↑ "Maitrise de la langue à l'école: Vocabulaire". Ministère de l'éducation nationale. External link in
|publisher=(help) - ↑ Baudot, J. (1992), Fréquences d'utilisation des mots en français écrit contemporain, Presses de L'Université, ISBN 2-7606-1563-4
- ↑ http://www.lexique.org/
- ↑ "Spanish word frequency lists". Vocabularywiki.pbworks.com.
References
| Look up Wiktionary:Frequency lists in Wiktionary, the free dictionary. |
- Theoretical concepts
- Nation, I.S.P. (1997), "Vocabulary size, text coverage, and word lists", in Schmitt; McCarthy, Vocabulary: Description, Acquisition and Pedagogy, Cambridge: Cambridge University Press, pp. 6–19, ISBN 978-0-521-58551-4
- Laufer,, B. (1997), "What’s in a word that makes it hard or easy? Some intralexical factors that affect the learning of words.", Vocabulary: Description, Acquisition and Pedagogy, Cambridge: Cambridge University Press, pp. 140–155, ISBN 9780521585514
- Nation, I.S.P. (2006la), Language Education - Vocabulary, Oxford: Encyclopedia of Language & Linguistics, pp. 494–499 Check date values in:
|date=(help). - Brysbaert, Marc; Buchmeier, Matthias; Conrad, Markus; Jacobs, Arthur M; Bölte, Jens; Böhl, Andrea (2011), "The word frequency effect: a review of recent developments and implications for the choice of frequency estimates in German.", Experimental Psychology 58 (5), pp. 412–424, doi:10.1027/1618-3169/a000123
- Rudell, A.P. (1993), "Frequency of word usage and perceived word difficulty : Ratings of Kucera and Francis words", Most 25 (4), pp. 455–463
- Segui, J.; Mehler, Jacques; Frauenfelder, Uli; Morton, John (1982), "The word frequency effect and lexical access", Neuropsychologia 20 (6), pp. 615–627
- Helmut Meier: Deutsche Sprachstatistik. Hildesheim: Olms 1967. (frequency list of German words)
- Written texts-based databases
- Da, Jun (1998), Jun Da: Chinese text computing [Accessed August 21, 2010].
- Taiwan Ministry of Education (1997), 八十六年常用語詞調查報告書 [Accessed August 21, 2010].
- New; Pallier (3.01), Manuel de Lexique 3 Check date values in:
|date=(help)
- SUBTLEX movement
- New, B.; Brysbaert, M.; Veronis, J.; Pallier, C. (2007), "SUBTLEX-FR: The use of film subtitles to estimate word frequencies", Applied Psycholinguistics (PDF) 28 (4), p. 661
- Brysbaert, Marc; New, Boris (2009), "Moving beyond Kucera and Francis: a critical evaluation of current word frequency norms and the introduction of a new and improved word frequency measure for American English", Behavior Research Methods (PDF) 41 (4), pp. 977–990
- Keuleers, E, M, B.; New, B. (2010), "SUBTLEX--NL: A new measure for Dutch word frequency based on film subtitles", Behavior Research Methods 42, pp. 643–650
- Cai, Q.; Brysbaert, M. (2010), "SUBTLEX-CH: Chinese Word and Character Frequencies Based on Film Subtitles", PLoS ONE 5 (6), p. 8
- Cuetos, F.; Glez-nosti, Maria; Barbón, Analía; Brysbaert, Marc (2011), "SUBTLEX-ESP : Spanish word frequencies based on film subtitles", Psicológica (PDF) 32, pp. 133–143
- Dimitropoulou, M.; Duñabeitia, Jon Andoni; Avilés, Alberto; Corral, José; Carreiras, Manuel (2010), "SUBTLEX-GR: Subtitle-Based Word Frequencies as the Best Estimate of Reading Behavior: The Case of Greek", Frontiers in Psychology 1 (December), p. 12
- Pham, H.; Bolger, P.; Baayen, R.H. (2011), "SUBTLEX-VIE : A Measure for Vietnamese Word and Character Frequencies on Film Subtitles", ACOL
- Brysbaert, M.; New, Boris; Keuleers, E. (2012), "SUBTLEX-US : Adding Part of Speech Information to the SUBTLEXus Word Frequencies", Behavior Research Methods (PDF), pp. 1–22 (databases)
- SUBTLEX-DE: [Not yet published: Buchmeier 2012:] Buchmeier (2012), The word frequency effect: A review of recent developments and implications for the choice of frequency estimates in German database
| ||||||||||||||||||||||