Word2vec
| Machine learning and data mining |
|---|
 |
| Problems |
| Clustering |
| Dimensionality reduction |
| Structured prediction |
| Anomaly detection |
| Neural nets |
| Theory |
| Machine learning venues |
| Data mining venues |
|
|
Word2vec is a group of related models that are used to produce so-called word embeddings. These models are shallow, two-layer neural networks, that are trained to reconstruct linguistic contexts of words: the network is shown a word, and must guess at which words occurred in adjacent positions in an input text. The order of the remaining words is not important (bag-of-words assumption).[1]
After training, word2vec models can be used to map each word to a vector of typically several hundred elements, which represent that word's relation to other words. This vector is the neural network's hidden layer.[2]
Word2vec relies on either skip-grams or continuous bag of words (CBOW) to create neural word embeddings. It was created by a team of researchers led by Tomas Mikolov at Google. The algorithm has been subsequently analysed and explained by other researchers.[3][4]
Skip grams and CBOW
Skip grams are word windows from which one word is excluded, an n-gram with gaps. With skip-grams, given a window size of n words around a word w, word2vec predicts contextual words c; i.e. in the notation of probability 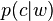 . Conversely, CBOW predicts the current word, given the context in the window,
. Conversely, CBOW predicts the current word, given the context in the window, 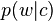 .
.
Extensions
An extension of word2vec to construct embeddings from entire documents (rather than the individual words) has been proposed.[5] This extension is called paragraph2vec or doc2vec and has been implemented in the C, Java, Scala and Python tools (see below), with the Java and Python versions also supporting inference of document embeddings on new, unseen documents.
Analysis
The reasons for successful word embedding learning in the word2vec framework are poorly understood. Goldberg and Levy point out that the word2vec objective function causes words that occur in similar contexts to have similar embeddings (as measured by cosine similarity) and note that this is in line with J. R. Firth's distributional hypothesis. They also note that this explanation is "very hand-wavy".
Implementations
See also
- Autoencoder
- Document-term matrix
- Feature extraction
- Feature learning
- Language modeling § Neural net language models
- Vector space model
References
- ↑ Mikolov, Tomas; Sutskever, Ilya; Chen, Kai; Corrado, Greg S.; Dean, Jeff (2013). Distributed representations of words and phrases and their compositionality. Advances in Neural Information Processing Systems.
- ↑ Mikolov, Tomas; et al. "Efficient Estimation of Word Representations in Vector Space" (PDF). Retrieved 2015-08-14.
- ↑ Goldberg, Yoav; Levy, Omar. "word2vec Explained: Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method" (PDF). Retrieved 2015-08-14.
- ↑ Řehůřek, Radim. "Word2vec and friends". Retrieved 2015-08-14.
- ↑ "Doc2Vec and Paragraph Vectors for Classification". Retrieved 2016-01-13.
| ||||||||||||||||||||||||||||||||||