Wigner–Eckart theorem
The Wigner–Eckart theorem is a theorem of representation theory and quantum mechanics. It states that matrix elements of spherical tensor operators on the basis of angular momentum eigenstates can be expressed as the product of two factors, one of which is independent of angular momentum orientation, and the other a Clebsch-Gordan coefficient. The name derives from physicists Eugene Wigner and Carl Eckart who developed the formalism as a link between the symmetry transformation groups of space (applied to the Schrödinger equations) and the laws of conservation of energy, momentum, and angular momentum.[1]
Mathematically, the Wigner–Eckart theorem is generally stated in the following way. Given a tensor operator 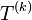 and two states of angular momenta
and two states of angular momenta 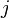 and
and 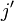 , there exists a constant
, there exists a constant 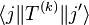 such that for all
such that for all  ,
,  , and
, and 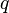 , the following equation is satisfied:
, the following equation is satisfied:
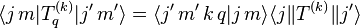
Here,
 is the q-th component of the spherical tensor operator of rank k,[2]
is the q-th component of the spherical tensor operator of rank k,[2] -
 denotes an eigenstate of total angular momentum J2 and its z-component Jz,
denotes an eigenstate of total angular momentum J2 and its z-component Jz, -
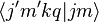 is the Clebsch–Gordan coefficient for coupling j′ with k to get j, and
is the Clebsch–Gordan coefficient for coupling j′ with k to get j, and - denotes[3] some value that does not depend on m, m′, nor q and is referred to as the reduced matrix element.
In effect, the Wigner–Eckart theorem says that operating with a spherical tensor operator of rank k on an angular momentum eigenstate is like adding a state with angular momentum k to the state. The matrix element one finds for the spherical tensor operator is proportional to a Clebsch–Gordan coefficient, which arises when considering adding two angular momenta. When stated another way, one can say that the Wigner–Eckart theorem is a theorem that tells you how vector operators behave in a subspace. Within a given subspace, a component of a vector operator will behave in a way proportional to the same component of the angular momentum operator. This definition is given in the book Quantum Mechanics by Cohen–Tannoudji, Diu and Laloe.
Background and overview
Motivating example: Position operator matrix elements for 4d→2p transition
Let's say we want to calculate transition dipole moments for an electron to transition from a 4d to a 2p orbital of a hydrogen atom, i.e. the matrix elements of the form 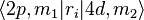 , where ri is either the x, y, or z component of the position operator, and m1, m2 are the magnetic quantum numbers that distinguish different orbitals within the 2p or 4d subshell. If we do this directly, it involves calculating 45 different integrals: There are three possibilities for m1 (-1, 0, 1), five possibilities for m2 (-2, -1, 0, 1, 2), and three possibilities for i, so the total is 3×5×3=45.
, where ri is either the x, y, or z component of the position operator, and m1, m2 are the magnetic quantum numbers that distinguish different orbitals within the 2p or 4d subshell. If we do this directly, it involves calculating 45 different integrals: There are three possibilities for m1 (-1, 0, 1), five possibilities for m2 (-2, -1, 0, 1, 2), and three possibilities for i, so the total is 3×5×3=45.
The Wigner–Eckart theorem allows one to obtain the same information after evaluating just one of those 45 integrals (any of them can be used, as long as it is nonzero). Then the other 44 integrals can be inferred just using algebra, with the help of Clebsch–Gordan coefficients, which can be easily looked up in a table, or computed by hand or computer.
Qualitative summary of proof
The Wigner–Eckart theorem works because all 45 of these different calculations are related to each other by rotations. If an electron is in one of the 2p orbitals, rotating the system will generally move it into a different 2p orbital (usually it will wind up in a quantum superposition of all three basis states, m=+1,0,-1). Similarly, if an electron is in one of the 4d orbitals, rotating the system will move it into a different 4d orbital. Finally, an analogous statement is true for the position operator: When the system is rotated, the three different components of the position operator are effectively interchanged or mixed.
If we start by knowing just one of the 45 values—say we know that 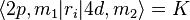 —and then we rotate the system, we can infer that K is also the matrix element between the rotated version of
—and then we rotate the system, we can infer that K is also the matrix element between the rotated version of  , the rotated version of
, the rotated version of  , and the rotated version of
, and the rotated version of 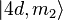 . This gives an algebraic relation involving K and some or all of the 44 unknown matrix elements. Different rotations of the system lead to different algebraic relations, and it turns out that there is enough information to figure out all of the matrix elements in this way.
. This gives an algebraic relation involving K and some or all of the 44 unknown matrix elements. Different rotations of the system lead to different algebraic relations, and it turns out that there is enough information to figure out all of the matrix elements in this way.
(In practice, when working through this math, we usually apply angular momentum operators to the states, rather than rotating the states. But this is fundamentally the same thing, because of the close mathematical relation between rotations and angular momentum operators.)
In terms of representation theory
To state these observations more precisely, and to prove them, it helps to invoke the mathematics of representation theory. For example, the set of all possible 4d orbitals (i.e., the five states m=-2,-1,0,1,2 and their quantum superpositions) form a 5-dimensional abstract vector space. Rotating the system transforms these states into each other, so this is an example of a "group representation"—in this case, the 5-dimensional irreducible representation ("irrep") of the rotation group SU(2) or SO(3), also called the "spin-2 representation". Similarly, the 2p quantum states form a 3-dimensional irrep (called "spin-1"), and the components of the position operator also form the 3-dimensional "spin-1" irrep.
Now consider the matrix elements . It turns out that these are transformed by rotations according to the direct product of those three representations, i.e. the spin-1 representation of the 2p orbitals, the spin-1 representation of the components of r, and the spin-2 representation of the 4d orbitals. This direct product, a 45-dimensional representation of SU(2), is not an irreducible representation—instead it is the direct sum of a spin-4 representation, two spin-3 representations, three spin-2 representations, two spin-1 representations, and a spin-0 (i.e. trivial) representation. The nonzero matrix elements can only come from the spin-0 subspace. The Wigner–Eckart theorem works because the direct product decomposition contains one and only one spin-0 subspace, which implies that all the matrix elements are determined by a single scale factor.
Apart from the overall scale factor, calculating the matrix element is equivalent to calculating the projection of the corresponding abstract vector (in 45-dimensional space) onto the spin-0 subspace. The results of this calculation are the Clebsch–Gordan coefficients. The key qualitative aspect of the Clebsch–Gordan decomposition that makes the argument work is that in the decomposition of the tensor product of two irreducible representations, each irreducible representation that occurs occurs only once. This allows Schur's Lemma to be used.[4]
Proof
Starting with the definition of a spherical tensor operator, we have that
![[J_\pm, T^{(k)}_q] = \hbar \sqrt{(k \mp q)(k \pm q + 1)}T_{q\pm 1}^{(k)}](../I/m/116853153bebc38f8233a749712f128f.png)
which we use to then calculate
![\langle j \, m | [J_\pm, T^{(k)}_q] | j' \, m' \rangle
= \hbar \sqrt{(k \mp q) (k \pm q + 1)}
\langle j \, m | T^{(k)}_{q \pm 1} | j' \, m' \rangle](../I/m/01aa9ee21439716788036f4664e0ac2d.png) .
.
If we expand the commutator on the LHS by calculating the action of the J± on the bra and ket, then we get
![\begin{align}
\langle j \, m | [J_\pm, T^{(k)}_q] | j' \, m' \rangle
&= \sqrt{(j \pm m) (j \mp m + 1)} \langle j \, (m \mp 1) | T^{(k)}_q | j' \, m' \rangle\\
& \qquad {} - \sqrt{(j' \mp m')(j' \pm m' + 1)} \langle j \, m | T^{(k)}_q | j' \, (m' \pm 1) \rangle
\end{align}](../I/m/01e54239a7cf656d7dbc9a4d13fabe5e.png)
We may combine these two results to get
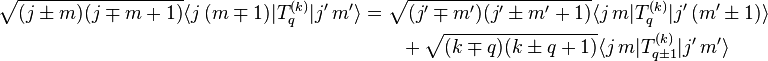
This recursion relation for the matrix elements closely resembles that of the Clebsch-Gordan coefficient. In fact, both are of the form ∑c ab, c xc = 0. We therefore have two sets of linear homogeneous equations
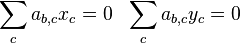
one for the Clebsch-Gordan coefficients (xc) and one for the matrix elements (yc). It is not possible to exactly solve for xc. We can only say that the ratios are equal, that is
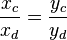
or that xc ∝ yc, where the coefficient of proportionality is independent of the indices. Hence, by comparing recursion relations, we can identify the Clebsch–Gordan coefficient ⟨j1 m1 j2 (m2 ± 1)|j m⟩ with the matrix element ⟨j′ m′|T(k)q ± 1|j m⟩, then we may write
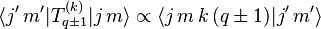 .
.
Alternative conventions
In some conventions (e.g. Sakurai's Modern Quantum Mechanics), the reduced matrix element is defined with a different factor:
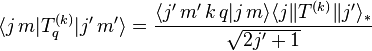
where the denominator is a normalizing factor. This article does not use this convention.
Example
Consider the position expectation value ⟨n j m|x|n j m⟩. This matrix element is the expectation value of a Cartesian operator in a spherically-symmetric hydrogen-atom-eigenstate basis, which is a nontrivial problem. However, the Wigner–Eckart theorem simplifies the problem. (In fact, we could obtain the solution quickly using parity, although a slightly longer route will be taken.)
We know that x is one component of r, which is a vector. Since vectors are rank-1 spherical tensor operators, it follows that x must be some linear combination of a rank-1 spherical tensor T(1)q with q ∈ {−1, 0, 1}. In fact, it can be shown that:
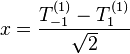 ,
,
where we define the spherical tensors as[5]
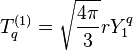
and Ylm are spherical harmonics, which themselves are also spherical tensors of rank l. Additionally, T(1)0 = z and
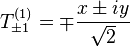
Therefore

The above expression gives us the matrix element for x in the |n j m⟩ basis. To find the expectation value, we set n′ = n, j′ = j, and m′ = m. The selection rule for m′ and m is m ± 1 = m′ for the T(1)±1 spherical tensors. As we have m′ = m, this makes the Clebsch–Gordan Coefficients zero, leading to the expectation value to be equal to zero.
References
- Hall, Brian C. (2015), Lie groups, Lie algebras, and representations: An elementary introduction, Graduate Texts in Mathematics 222 (2nd ed.), Springer
- ↑ Eckart Biography– The National Academies Press
- ↑ The parenthesized superscript (k) provides a reminder of its rank. However, unlike q, it need not be an actual index.
- ↑ This is a special notation specific to the Wigner-Eckart theorem.
- ↑ Hall 2015 Appendix C
- ↑ J. J. Sakurai: "Modern quantum mechanics" (Massachusetts, 1994, Addison-Wesley)
See Also
External links
- J. J. Sakurai, (1994). "Modern Quantum Mechanics", Addison Wesley, ISBN 0-201-53929-2.
- Weisstein, Eric W., "Wigner–Eckart theorem", MathWorld.
- Wigner–Eckart theorem
- Tensor Operators