Randomness extractor
A randomness extractor, often simply called an "extractor", is a function, which being applied to output from a weakly random entropy source, together with a short, uniformly random seed, generates a highly random output that appears independent from the source and uniformly distributed.[1] Examples of weakly random sources include radioactive decay or thermal noise; the only restriction on possible sources is that there is no way they can be fully controlled, calculated or predicted, and that a lower bound on their entropy rate can be established. For a given source, a randomness extractor can even be considered to be a true random number generator (TRNG); but there is no single extractor that has been proven to produce truly random output from any type of weakly random source.
Sometimes the term "bias" is used to denote a weakly random source's departure from uniformity, and in older literature, some extractors are called unbiasing algorithms,[2] as they take the randomness from a so-called "biased" source and output a distribution that appears unbiased. The weakly random source will always be longer than the extractor's output, but an efficient extractor is one that lowers this ratio of lengths as much as possible, while simultaneously keeping the seed length low. Intuitively, this means that as much randomness as possible has been "extracted" from the source.
Note that an extractor has some conceptual similarities with a pseudorandom generator (PRG), but the two concepts are not identical. Both are functions that take as input a small, uniformly random seed and produce a longer output that "looks" uniformly random. Some pseudorandom generators are, in fact, also extractors. (When a PRG is based on the existence of hard-core predicates, one can think of the weakly random source as a set of truth tables of such predicates and prove that the output is statistically close to uniform.[3]) However, the general PRG definition does not specify that a weakly random source must be used, and while in the case of an extractor, the output should be statistically close to uniform, in a PRG it is only required to be computationally indistinguishable from uniform, a somewhat weaker concept.
NIST Special Publication 800-90B (draft) recommends several extractors, including the SHA hash family and states that if the amount of entropy input is twice the number of bits output from them, that output can be considered essentially fully random.[4]
Formal definition of extractors
The min-entropy of a distribution 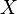 (denoted
(denoted 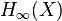 ), is the largest real number
), is the largest real number  such that
such that ![\Pr[X =x] \leq 2^{-k}](../I/m/72f74f32d7f1455e16490a1755a61948.png) for every
for every  in the range of . In essence, this measures how likely is to take its most likely value, giving a worst-case bound on how random appears. Letting
in the range of . In essence, this measures how likely is to take its most likely value, giving a worst-case bound on how random appears. Letting 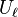 denote the uniform distribution over
denote the uniform distribution over 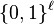 , clearly
, clearly 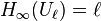 .
.
For an n-bit distribution with min-entropy k, we say that is an 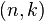 distribution.
distribution.
Definition (Extractor): (k, ε)-extractor
Let 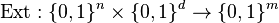 be a function that takes as input a sample from an distribution and a d-bit seed from
be a function that takes as input a sample from an distribution and a d-bit seed from 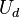 , and outputs an m-bit string.
, and outputs an m-bit string.
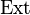 is a (k, ε)-extractor, if for all distributions , the output distribution of is ε-close to
is a (k, ε)-extractor, if for all distributions , the output distribution of is ε-close to 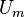 .
.
In the above definition, ε-close refers to statistical distance.
Intuitively, an extractor takes a weakly random n-bit input and a short, uniformly random seed and produces an m-bit output that looks uniformly random. The aim is to have a low 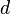 (i.e. to use as little uniform randomness as possible) and as high an
(i.e. to use as little uniform randomness as possible) and as high an  as possible (i.e. to get out as many close-to-random bits of output as we can).
as possible (i.e. to get out as many close-to-random bits of output as we can).
Strong extractors
An extractor is strong if concatenating the seed with the extractor's output yields a distribution that is still close to uniform.
Definition (Strong Extractor): A  -strong extractor is a function
-strong extractor is a function
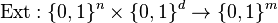
such that for every distribution the distribution 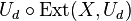 (the two copies of denote the same random variable) is
(the two copies of denote the same random variable) is  -close to the uniform distribution on
-close to the uniform distribution on 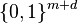 .
.
Explicit extractors
Using the probabilistic method, it can be shown that there exists a (k, ε)-extractor, i.e. that the construction is possible. However, it is usually not enough merely to show that an extractor exists. An explicit construction is needed, which is given as follows:
Definition (Explicit Extractor): For functions k(n), ε(n), d(n), m(n) a family Ext = {Extn} of functions

is an explicit (k, ε)-extractor, if Ext(x, y) can be computed in polynomial time (in its input length) and for every n, Extn is a (k(n), ε(n))-extractor.
By the probabilistic method, it can be shown that there exists a (k, ε)-extractor with seed length
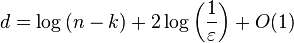
and output length
-
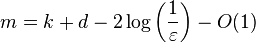 .[5]
.[5]
Dispersers
A variant of the randomness extractor with weaker properties is the disperser.
Randomness extractors in cryptography
One of the most important aspects of cryptography is random key generation.[6] It is often necessary to generate secret and random keys from sources that are semi-secret or which may be compromised to some degree. By taking a single, short (and secret) random key as a source, an extractor can be used to generate a longer pseudo-random key, which then can be used for public key encryption. More specifically, when a strong extractor is used its output will appear be uniformly random, even to someone who sees part (but not all) of the source. For example, if the source is known but the seed is not known (or vice versa). This property of extractors is particularly useful in what is commonly called Exposure-Resilient cryptography in which the desired extractor is used as an Exposure-Resilient Function (ERF). Exposure-Resilient cryptography takes into account that the fact that it is difficult to keep secret the initial exchange of data which often takes place during the initialization of an encryption application e.g., the sender of encrypted information has to provide the receivers with information which is required for decryption.
The following paragraphs define and establish an important relationship between two kinds of ERF--k-ERF and k-APRF--which are useful in Exposure-Resilient cryptography.
Definition (k-ERF): An adaptive k-ERF is a function 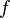 where, for a random input
where, for a random input  , when a computationally unbounded adversary
, when a computationally unbounded adversary 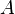 can adaptively read all of except for bits,
can adaptively read all of except for bits, 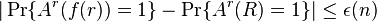 for some negligible function
for some negligible function 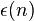 (defined below).
(defined below).
The goal is to construct an adaptive ERF whose output is highly random and uniformly distributed. But a stronger condition is often needed in which every output occurs with almost uniform probability. For this purpose Almost-Perfect Resilient Functions (APRF) are used. The definition of an APRF is as follows:
Definition (k-APRF): A 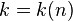 APRF is a function where, for any setting of
APRF is a function where, for any setting of  bits of the input to any fixed values, the probability vector
bits of the input to any fixed values, the probability vector 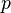 of the output
of the output  over the random choices for the remaining bits satisfies
over the random choices for the remaining bits satisfies 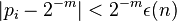 for all
for all  and for some negligible function .
and for some negligible function .
Kamp and Zuckerman[7] have proved a theorem stating that if a function is a k-APRF, then is also a k-ERF. More specifically, any extractor having sufficiently small error and taking as input an oblivious, bit-fixing source is also an APRF and therefore also a k-ERF. A more specific extractor is expressed in this lemma:
Lemma: Any 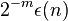 -extractor
-extractor 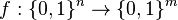 for the set of oblivious bit-fixing sources, where is negligible, is also a k-APRF.
for the set of oblivious bit-fixing sources, where is negligible, is also a k-APRF.
This lemma is proved by Kamp and Zuckerman.[7] The lemma is proved by examining the distance from uniform of the output, which in a -extractor obviously is at most, which satisfies the condition of the APRF.
The lemma leads to the following theorem, stating that there in fact exists a k-APRF function as described:
Theorem (existence): For any positive constant 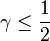 , there exists an explicit k-APRF
, there exists an explicit k-APRF 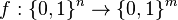 , computable in a linear number of arithmetic operations on -bit strings, with
, computable in a linear number of arithmetic operations on -bit strings, with 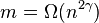 and
and 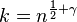 .
.
Definition (negligible function): In the proof of this theorem, we need a definition of a negligible function. A function is defined as being negligible if 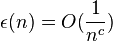 for all constants
for all constants  .
.
Proof:
Consider the following -extractor: The function is an extractor for the set of 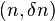 oblivious bit-fixing source: . has
oblivious bit-fixing source: . has 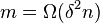 ,
, 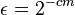 and
and 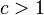 .
.
The proof of this extractor's existence with 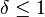 , as well as the fact that it is computable in linear computing time on the length of can be found in the paper by Jesse Kamp and David Zuckerman (p. 1240).
, as well as the fact that it is computable in linear computing time on the length of can be found in the paper by Jesse Kamp and David Zuckerman (p. 1240).
That this extractor fulfills the criteria of the lemma is trivially true as is a negligible function.
The size of is:
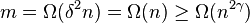
Since we know then the lower bound on is dominated by  . In the last step we use the fact that which means that the power of is at most
. In the last step we use the fact that which means that the power of is at most 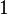 . And since is a positive integer we know that
. And since is a positive integer we know that 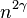 is at most .
is at most .
The value of is calculated by using the definition of the extractor, where we know:
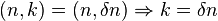
and by using the value of we have:
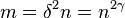
Using this value of we account for the worst case, where is on its lower bound. Now by algebraic calculations we get:

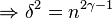
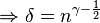
Which inserted in the value of gives
-
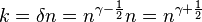 ,
,
which proves that there exists an explicit k-APRF extractor with the given properties. 
Examples
Von Neumann extractor
Perhaps the earliest example is due to John von Neumann. His extractor took successive pairs of consecutive bits (non-overlapping) from the input stream. If the two bits matched, no output was generated. If the bits differed, the value of the first bit was output. The Von Neumann extractor can be shown to produce a uniform output even if the distribution of input bits is not uniform so long as each bit has the same probability of being one and there is no correlation between successive bits.[8]
Thus, it takes as input a Bernoulli sequence with p not necessarily equal to 1/2, and outputs a Bernoulli sequence with 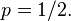 More generally, it applies to any exchangeable sequence – it only relies on the fact that for any pair, 01 and 10 are equally likely: for independent trials, these have probabilities
More generally, it applies to any exchangeable sequence – it only relies on the fact that for any pair, 01 and 10 are equally likely: for independent trials, these have probabilities 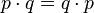 , while for an exchangeable sequence the probability may be more complicated, but both are equally likely.
, while for an exchangeable sequence the probability may be more complicated, but both are equally likely.
Cryptographic hash function
Another approach is to use the output of a cryptographic hash function applied to the input stream. This approach generally relies on assumed properties of the hash function.
Applications
Randomness extractors are used widely in cryptographic applications, whereby a cryptographic hash function is applied to a high-entropy, but non-uniform source, such as disk drive timing information or keyboard delays, to yield a uniformly random result.
Randomness extractors have played a part in recent developments in quantum cryptography, where photons are used by the randomness extractor to generate secure random bits.
Randomness extraction is also used in some branches of computational complexity theory.
Random extraction is also used to convert data to a simple random sample, which is normally distributed, and independent, which is desired by statistics.
See also
References
- ↑ "Extracting randomness from sampleable distributions". Portal.acm.org. Retrieved 2012-06-12.
- ↑ David K. Gifford, Natural Random Numbers, MIT/LCS/TM-371, Massachusetts Institute of Technology, August 1988.
- ↑ Luca Trevisan. "Extractors and Pseudorandom Generators" (PDF). Retrieved 2013-10-21.
- ↑ Recommendation for the Entropy Sources Used for Random Bit Generation (draft) NIST SP800-90B, Barker and Kelsey, August 2012, Section 6.4.2
- ↑ Ronen Shaltiel. Recent developments in explicit construction of extractors. P. 5.
- ↑ Jesse Kamp and David Zuckerman. Deterministic Extractors for Bit-Fixing Sources and Exposure-Resilient Cryptography.,SIAM J. Comput.,Vol. 36, No. 5, pp. 1231–1247.
- 1 2 Jesse Kamp and David Zuckerman. Deterministic Extractors for Bit-Fixing Sources and Exposure-Resilient Cryptography. P. 1242.
- ↑ John von Neumann. Various techniques used in connection with random digits. Applied Math Series, 12:36–38, 1951.
- Randomness Extractors for Independent Sources and Applications, Anup Rao
- Recent developments in explicit constructions of extractors, Ronen Shaltiel
- Randomness Extraction and Key Derivation Using the CBC, Cascade and HMAC Modes, Yevgeniy Dodis et al.
- Key Derivation and Randomness Extraction, Olivier Chevassut et al.
- Deterministic Extractors for Bit-Fixing Sources and Exposure-Resilient Cryptography, Jesse Kamp and David Zuckerman
- Tossing a Biased Coin (and the optimality of advanced multi-level strategy) (lecture notes), Michael Mitzenmacher