Vector processor
In computing, a vector processor or array processor is a central processing unit (CPU) that implements an instruction set containing instructions that operate on one-dimensional arrays of data called vectors, compared to scalar processors, whose instructions operate on single data items. Vector processors can greatly improve performance on certain workloads, notably numerical simulation and similar tasks. Vector machines appeared in the early 1970s and dominated supercomputer design through the 1970s into the 1990s, notably the various Cray platforms. The rapid fall in the price-to-performance ratio of conventional microprocessor designs led to the vector supercomputer's demise in the later 1990s.
As of 2015 most commodity CPUs implement architectures that feature instructions for a form of vector processing on multiple (vectorized) data sets, typically known as SIMD (Single Instruction, Multiple Data). Common examples include Intel x86's MMX, SSE and AVX instructions, Sparc's VIS extension, PowerPC's AltiVec and MIPS' MSA. Vector processing techniques also operate in video-game console hardware and in graphics accelerators. In 2000, IBM, Toshiba and Sony collaborated to create the Cell processor, consisting of one scalar processor and eight vector processors, which found use in the Sony PlayStation 3 among other applications.
Other CPU designs may include some multiple instructions for vector processing on multiple (vectorised) data sets, typically known as MIMD (Multiple Instruction, Multiple Data) and realized with VLIW. Such designs are usually dedicated to a particular application and not commonly marketed for general-purpose computing. The Fujitsu FR-V VLIW/vector processor combines both technologies.
History
Early work
Vector processing development began in the early 1960s at Westinghouse in their Solomon project. Solomon's goal was to dramatically increase math performance by using a large number of simple math co-processors under the control of a single master CPU. The CPU fed a single common instruction to all of the arithmetic logic units (ALUs), one per "cycle", but with a different data point for each one to work on. This allowed the Solomon machine to apply a single algorithm to a large data set, fed in the form of an array.
In 1962, Westinghouse cancelled the project, but the effort was restarted at the University of Illinois as the ILLIAC IV. Their version of the design originally called for a 1 GFLOPS machine with 256 ALUs, but, when it was finally delivered in 1972, it had only 64 ALUs and could reach only 100 to 150 MFLOPS. Nevertheless it showed that the basic concept was sound, and, when used on data-intensive applications, such as computational fluid dynamics, the "failed" ILLIAC was the fastest machine in the world. The ILLIAC approach of using separate ALUs for each data element is not common to later designs, and is often referred to under a separate category, massively parallel computing.
A computer for operations with functions was presented and developed by Kartsev in 1967.[1]
Supercomputers
The first successful implementation of vector processing appears to be the Control Data Corporation STAR-100 and the Texas Instruments Advanced Scientific Computer (ASC). The basic ASC (i.e., "one pipe") ALU used a pipeline architecture that supported both scalar and vector computations, with peak performance reaching approximately 20 MFLOPS, readily achieved when processing long vectors. Expanded ALU configurations supported "two pipes" or "four pipes" with a corresponding 2X or 4X performance gain. Memory bandwidth was sufficient to support these expanded modes. The STAR was otherwise slower than CDC's own supercomputers like the CDC 7600, but at data related tasks they could keep up while being much smaller and less expensive. However the machine also took considerable time decoding the vector instructions and getting ready to run the process, so it required very specific data sets to work on before it actually sped anything up.
The vector technique was first fully exploited in 1976 by the famous Cray-1. Instead of leaving the data in memory like the STAR and ASC, the Cray design had eight "vector registers," which held sixty-four 64-bit words each. The vector instructions were applied between registers, which is much faster than talking to main memory. The Cray design used pipeline parallelism to implement vector instructions rather than multiple ALUs. In addition the design had completely separate pipelines for different instructions, for example, addition/subtraction was implemented in different hardware than multiplication. This allowed a batch of vector instructions themselves to be pipelined, a technique they called vector chaining. The Cray-1 normally had a performance of about 80 MFLOPS, but with up to three chains running it could peak at 240 MFLOPS – a respectable number even as of 2002.

Other examples followed. Control Data Corporation tried to re-enter the high-end market again with its ETA-10 machine, but it sold poorly and they took that as an opportunity to leave the supercomputing field entirely. In the early and mid-1980s Japanese companies (Fujitsu, Hitachi and Nippon Electric Corporation (NEC) introduced register-based vector machines similar to the Cray-1, typically being slightly faster and much smaller. Oregon-based Floating Point Systems (FPS) built add-on array processors for minicomputers, later building their own minisupercomputers. However Cray continued to be the performance leader, continually beating the competition with a series of machines that led to the Cray-2, Cray X-MP and Cray Y-MP. Since then, the supercomputer market has focused much more on massively parallel processing rather than better implementations of vector processors. However, recognising the benefits of vector processing IBM developed Virtual Vector Architecture for use in supercomputers coupling several scalar processors to act as a vector processor.
SIMD
Vector processing techniques have since been added to almost all modern CPU designs, although they are typically referred to as SIMD. In these implementations, the vector unit runs beside the main scalar CPU, and is fed data from vector instruction aware programs.
Description
In general terms, CPUs are able to manipulate one or two pieces of data at a time. For instance, most CPUs have an instruction that essentially says "add A to B and put the result in C". The data for A, B and C could be—in theory at least—encoded directly into the instruction. However, in efficient implementation things are rarely that simple. The data is rarely sent in raw form, and is instead "pointed to" by passing in an address to a memory location that holds the data. Decoding this address and getting the data out of the memory takes some time, during which the CPU traditionally would sit idle waiting for the requested data to show up. As CPU speeds have increased, this memory latency has historically become a large impediment to performance; see Memory wall.
In order to reduce the amount of time consumed by these steps, most modern CPUs use a technique known as instruction pipelining in which the instructions pass through several sub-units in turn. The first sub-unit reads the address and decodes it, the next "fetches" the values at those addresses, and the next does the math itself. With pipelining the "trick" is to start decoding the next instruction even before the first has left the CPU, in the fashion of an assembly line, so the address decoder is constantly in use. Any particular instruction takes the same amount of time to complete, a time known as the latency, but the CPU can process an entire batch of operations much faster and more efficiently than if it did so one at a time.
Vector processors take this concept one step further. Instead of pipelining just the instructions, they also pipeline the data itself. The processor is fed instructions that say not just to add A to B, but to add all of the numbers "from here to here" to all of the numbers "from there to there". Instead of constantly having to decode instructions and then fetch the data needed to complete them, the processor reads a single instruction from memory, and it is simply implied in the definition of the instruction itself that the instruction will operate again on another item of data, at an address one increment larger than the last. This allows for significant savings in decoding time.
To illustrate what a difference this can make, consider the simple task of adding two groups of 10 numbers together. In a normal programming language one would write a "loop" that picked up each of the pairs of numbers in turn, and then added them. To the CPU, this would look something like this:
execute this loop 10 times read the next instruction and decode it fetch this number fetch that number add them put the result here end loop
But to a vector processor, this task looks considerably different:
read instruction and decode it fetch these 10 numbers fetch those 10 numbers add them put the results here
There are several savings inherent in this approach. For one, only two address translations are needed. Depending on the architecture, this can represent a significant savings by itself. Another saving is fetching and decoding the instruction itself, which has to be done only one time instead of ten. The code itself is also smaller, which can lead to more efficient memory use.
But more than that, a vector processor may have multiple functional units adding those numbers in parallel. The checking of dependencies between those numbers is not required as a vector instruction specifies multiple independent operations. This simplifies the control logic required, and can improve performance by avoiding stalls.
As mentioned earlier, the Cray implementations took this a step further, allowing several different types of operations to be carried out at the same time. Consider code that adds two numbers and then multiplies by a third; in the Cray, these would all be fetched at once, and both added and multiplied in a single operation. Using the pseudocode above, the Cray did:
read instruction and decode it fetch these 10 numbers fetch those 10 numbers fetch another 10 numbers add and multiply them put the results here
The math operations thus completed far faster overall, the limiting factor being the time required to fetch the data from memory.
Not all problems can be attacked with this sort of solution. Including these types of instructions necessarily adds complexity to the core CPU. That complexity typically makes other instructions run slower—i.e., whenever it is not adding up many numbers in a row. The more complex instructions also add to the complexity of the decoders, which might slow down the decoding of the more common instructions such as normal adding.
In fact, vector processors work best only when there are large amounts of data to be worked on. For this reason, these sorts of CPUs were found primarily in supercomputers, as the supercomputers themselves were, in general, found in places such as weather prediction centres and physics labs, where huge amounts of data are "crunched".
Performance and Speed Up
Let r be the vector speed ratio and f be the vectorization ratio. If the time taken for the vector unit to add an array of 64 numbers is 10 times faster than its equivalent scalar counterpart, r = 10. Also, if the total number of operations in a program is 100, out of which only 10 are scalar (after vectorization), then f = 90, i.e, 90% of the work is done by the vector unit. It follows the achievable speed up of:
![r/[(1-f)*r+f]](../I/m/2f6919772acba644d2857ddd8a03c21f.png)
So, even if the performance of the vector unit is very high (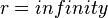 ) we get a speedup less than
) we get a speedup less than 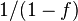 , which suggests that the ratio f is crucial to the performance. This ratio depends on the efficiency of the compilation like adjacency of the elements in memory.
, which suggests that the ratio f is crucial to the performance. This ratio depends on the efficiency of the compilation like adjacency of the elements in memory.
Real world example: vector instructions usage with the x86 architecture
Shown below is an actual x86 architecture example for vector instruction usage with the SSE instruction set. The example multiplies two arrays of single precision floating point numbers. It's written in the C language with inline assembly code parts for compilation with GCC (32bit).
//SSE simd function for vectorized multiplication of 2 arrays with single-precision floatingpoint numbers
//1st param pointer on source/destination array, 2nd param 2. source array, 3rd param number of floats per array
void mul_asm(float* out, float* in, unsigned int leng)
{ unsigned int count, rest;
//compute if array is big enough for vector operation
rest = (leng*4)%16;
count = (leng*4)-rest;
// vectorized part; 4 floats per loop iteration
if (count>0){
__asm __volatile__ (".intel_syntax noprefix\n\t"
"loop: \n\t"
"movups xmm0,[ebx+ecx] ;loads 4 floats in first register (xmm0)\n\t"
"movups xmm1,[eax+ecx] ;loads 4 floats in second register (xmm1)\n\t"
"mulps xmm0,xmm1 ;multiplies both vector registers\n\t"
"movups [eax+ecx],xmm0 ;write back the result to memory\n\t"
"sub ecx,16 ;increase address pointer by 4 floats\n\t"
"jnz loop \n\t"
".att_syntax prefix \n\t"
: : "a" (out), "b" (in), "c"(count), "d"(rest): "xmm0","xmm1");
}
// scalar part; 1 float per loop iteration
if (rest!=0)
{
__asm __volatile__ (".intel_syntax noprefix\n\t"
"add eax,ecx \n\t"
"add ebx,ecx \n\t"
"rest: \n\t"
"movss xmm0,[ebx+edx] ;load 1 float in first register (xmm0)\n\t"
"movss xmm1,[eax+edx] ;load 1 float in second register (xmm1)\n\t"
"mulss xmm0,xmm1 ;multiplies both scalar parts of registers\n\t"
"movss [eax+edx],xmm0 ;write back the result\n\t"
"sub edx,4 \n\t"
"jnz rest \n\t"
".att_syntax prefix \n\t"
: : "a" (out), "b" (in), "c"(count), "d"(rest): "xmm0","xmm1");
}
return;
}
Programming heterogeneous computing architectures
Various machines were designed to include both traditional processors and vector processors, such as the Fujitsu AP1000 and AP3000. Programming such heterogeneous machines can be difficult since developing programs that make best use of characteristics of different processors increases the programmer's burden. It increases code complexity and decreases portability of the code by requiring hardware specific code to be interleaved throughout application code.[2] Balancing the application workload across processors can be problematic, especially given that they typically have different performance characteristics. There are different conceptual models to deal with the problem, for example using a coordination language and program building blocks (programming libraries or higher order functions). Each block can have a different native implementation for each processor type. Users simply program using these abstractions and an intelligent compiler chooses the best implementation based on the context.[3]
See also
- Stream processing
- SIMD
- Automatic vectorization
- Chaining (vector processing)
- Computer for operations with functions
References
- ↑ Malinovsky, B.N. (1995 (see also here http://www.sigcis.org/files/SIGCISMC2010_001.pdf and english version here)). The history of computer technology in their faces (in Russian). Kiew: Firm "KIT". ISBN 5-7707-6131-8. Check date values in:
|date=(help) - ↑ Kunzman, D. M.; Kale, L. V. (2011). "Programming Heterogeneous Systems". 2011 IEEE International Symposium on Parallel and Distributed Processing Workshops and Phd Forum. p. 2061. doi:10.1109/IPDPS.2011.377. ISBN 978-1-61284-425-1.
- ↑ John Darlinton, Moustafa Ghanem, Yike Guo, Hing Wing To (1996), "Guided Resource Organisation in Heterogeneous Parallel Computing", Journal of High Performance Computing 4 (1): 13–23
External links
- The History of the Development of Parallel Computing (from 1955 to 1993)
| ||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||