Coefficient of variation
In probability theory and statistics, the coefficient of variation (CV), also known as relative standard deviation (RSD), is a standardized measure of dispersion of a probability distribution or frequency distribution. It is often expressed as a percentage, and is defined as the ratio of the standard deviation 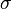 to the mean
to the mean 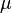 (or its absolute value,
(or its absolute value, 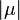 ).
The CV or RSD is widely used in analytical chemistry to express the precision and repeatability of an assay. It is also commonly used in fields such as engineering or physics when doing quality assurance studies and ANOVA gauge R&R.
).
The CV or RSD is widely used in analytical chemistry to express the precision and repeatability of an assay. It is also commonly used in fields such as engineering or physics when doing quality assurance studies and ANOVA gauge R&R.
Definition
The coefficient of variation (CV) is defined as the ratio of the standard deviation to the mean :[1]
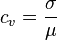
It shows the extent of variability in relation to the mean of the population.
The coefficient of variation should be computed only for data measured on a ratio scale, as these are the measurements that can only take non-negative values. The coefficient of variation may not have any meaning for data on an interval scale.[2] For example, most temperature scales (e.g., Celsius, Fahrenheit etc.) are interval scales that can take both positive and negative values, whereas the kelvin temperature can never be less than zero, which is the complete absence of thermal energy. Hence, the kelvin scale is a ratio scale. While the standard deviation (SD) can be derived on both the kelvin and the celsius scale (with both leading to the same SDs), the CV is only relevant as a measure of relative variability for the kelvin scale.
Measurements that are log-normally distributed exhibit stationary CV; in contrast, SD varies depending upon the expected value of measurements.
A more robust possibility is the quartile coefficient of dispersion, i.e. interquartile range  divided by the median
divided by the median 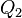 .
.
Examples
A data set of [100, 100, 100] has constant values. Its standard deviation is 0 and average is 100:
- 100% × 0 / 100 = 0%
A data set of [90, 100, 110] has more variability. Its standard deviation is 8.16 and its average is 100:
- 100% × 8.16 / 100 = 8.16%
A data set of [1, 5, 6, 8, 10, 40, 65, 88] has more variability again. Its standard deviation is 30.78 and its average is 27.875:
- 100% × 30.78 / 27.875 = 110.4%
Examples of misuse
To see why the coefficient of variation should not be applied to interval level data, compare the same set of temperatures in Celsius and Fahrenheit:
Celsius: [0, 10, 20, 30, 40] Fahrenheit: [32, 50, 68, 86, 104]
The CV of the first set is 15.81/20 = 0.79. For the second set (which are the same temperatures) it is 28.46/68 = 0.42.
Estimation
When only a sample of data from a population is available, the population CV can be estimated using the ratio of the sample standard deviation  to the sample mean
to the sample mean 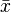 :
:
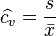
But this estimator, when applied to a small or moderately sized sample, tends to be too low: it is a biased estimator. For normally distributed data, an unbiased estimator[3] for a sample of size n is:
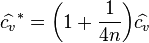
Log-normal data
In many applications, it can be assumed that data are log-normally distributed (evidenced by the presence of skewness in the sampled data).[4] In such cases, a more accurate estimate, derived from the properties of the log-normal distribution,[5][6][7] is defined as:
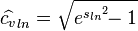
where 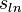 is the sample standard deviation of the data after a natural log transformation. (In the event that measurements are recorded using any other logarithmic base, b, their standard deviation
is the sample standard deviation of the data after a natural log transformation. (In the event that measurements are recorded using any other logarithmic base, b, their standard deviation 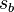 is converted to base e using
is converted to base e using 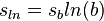 , and the formula for
, and the formula for 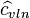 remains the same.[8]) This estimate is sometimes referred to as the “geometric CV”[9][10] in order to distinguish it from the simple estimate above. However, "geometric coefficient of variation" has also been defined by Kirkwood[11] as:
remains the same.[8]) This estimate is sometimes referred to as the “geometric CV”[9][10] in order to distinguish it from the simple estimate above. However, "geometric coefficient of variation" has also been defined by Kirkwood[11] as:
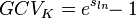
This term was intended to be analogous to the coefficient of variation, for describing multiplicative variation in log-normal data, but this definition of GCV has no theoretical basis as an estimate of 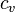 itself.
itself.
For many practical purposes (such as sample size determination and calculation of confidence intervals) it is 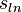 which is of most use in the context of log-normally distributed data. If necessary, this can be derived from an estimate of or GCV by inverting the corresponding formula.
which is of most use in the context of log-normally distributed data. If necessary, this can be derived from an estimate of or GCV by inverting the corresponding formula.
Comparison to standard deviation
Advantages
The coefficient of variation is useful because the standard deviation of data must always be understood in the context of the mean of the data. In contrast, the actual value of the CV is independent of the unit in which the measurement has been taken, so it is a dimensionless number. For comparison between data sets with different units or widely different means, one should use the coefficient of variation instead of the standard deviation.
Disadvantages
- When the mean value is close to zero, the coefficient of variation will approach infinity and is therefore sensitive to small changes in the mean. This is often the case if the values do not originate from a ratio scale.
- Unlike the standard deviation, it cannot be used directly to construct confidence intervals for the mean.
- CVs are not an ideal index of the certainty of a measurement when the number of replicates varies across samples because CV is invariant to the number of replicates while certainty of the mean improves with increasing replicates. In this case standard error in percent is suggested to be superior.[12]
Applications
The coefficient of variation is also common in applied probability fields such as renewal theory, queueing theory, and reliability theory. In these fields, the exponential distribution is often more important than the normal distribution. The standard deviation of an exponential distribution is equal to its mean, so its coefficient of variation is equal to 1. Distributions with CV < 1 (such as an Erlang distribution) are considered low-variance, while those with CV > 1 (such as a hyper-exponential distribution) are considered high-variance. Some formulas in these fields are expressed using the squared coefficient of variation, often abbreviated SCV. In modeling, a variation of the CV is the CV(RMSD). Essentially the CV(RMSD) replaces the standard deviation term with the Root Mean Square Deviation (RMSD). While many natural processes indeed show a correlation between the average value and the amount of variation around it, accurate sensor devices need to be designed in such a way that the coefficient of variation is close to zero, i.e., yielding a constant absolute error over their working range.
In actuarial science, the CV is known as unitized risk[13]
Laboratory measures of intra-assay and inter-assay CVs
CV measures are often used as quality controls for quantitative laboratory assays. While intra-assay and inter-assay CVs might be assumed to be calculated by simply averaging CV values across CV values for multiple samples within one assay or by averaging multiple inter-assay CV estimates, it has been suggested that these practices are incorrect and that a more complex computational process is required.[14] It has also been noted that CV values are not an ideal index of the certainty of a measurement when the number of replicates varies across samples − in this case standard error in percent is suggested to be superior.[15]
Distribution
Provided that negative and small positive values of the sample mean occur with negligible frequency, the probability distribution of the coefficient of variation for a sample of size n has been shown by Hendricks and Robey[16] to be
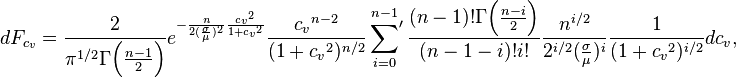
where the symbol  indicates that the summation is over only even values of n-1-i, i.e., if n is odd, sum over even values of i and if n is even, sum only over odd values of i.
indicates that the summation is over only even values of n-1-i, i.e., if n is odd, sum over even values of i and if n is even, sum only over odd values of i.
This is useful, for instance, in the construction of hypothesis tests or confidence intervals. Statistical inference for the coefficient of variation in normally distributed data is often based on McKay's chi-square approximation for the coefficient of variation [17][18][19][20]
Alternative
According to Liu (2012),[21] Lehmann (1986).[22] "also derived the sample distribution of CV in order to give an exact method for the construction of a confidence interval for CV;" it is based on a non-central t-distribution.
Similar ratios
Standardized moments are similar ratios, 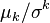 where
where  is the kth moment about the mean, which are also dimensionless and scale invariant. The variance-to-mean ratio,
is the kth moment about the mean, which are also dimensionless and scale invariant. The variance-to-mean ratio, 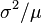 , is another similar ratio, but is not dimensionless, and hence not scale invariant. See Normalization (statistics) for further ratios.
, is another similar ratio, but is not dimensionless, and hence not scale invariant. See Normalization (statistics) for further ratios.
In signal processing, particularly image processing, the reciprocal ratio  is referred to as the signal to noise ratio in general and signal-to-noise ratio (imaging) in particular.
is referred to as the signal to noise ratio in general and signal-to-noise ratio (imaging) in particular.
- Efficiency,
- Standardized moment,
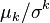
- Variance-to-mean ratio (or relative variance),
- Fano factor,
 (windowed VMR)
(windowed VMR) - Relative Standard Error
See also
References
- ↑ Everitt, Brian (1998). The Cambridge Dictionary of Statistics. Cambridge, UK New York: Cambridge University Press. ISBN 0521593468.
- ↑ "What is the difference between ordinal, interval and ratio variables? Why should I care?". GraphPad Software Inc. Retrieved 2008-02-22.
- ↑ Sokal RR & Rohlf FJ. Biometry (3rd Ed). New York: Freeman, 1995. p. 58. ISBN 0-7167-2411-1
- ↑ Limpert, Eckhard; Stahel, Werner A.; Abbt, Markus (2001). "Log-normal Distributions across the Sciences: Keys and Clues". BioScience 51: 341–352. doi:10.1641/0006-3568(2001)051[0341:LNDATS]2.0.CO;2.
- ↑ Koopmans, L. H.; Owen, D. B.; Rosenblatt, J. I. (1964). "Confidence intervals for the coefficient of variation for the normal and log normal distributions". Biometrika 51: 25–32. doi:10.1093/biomet/51.1-2.25.
- ↑ Diletti, E; Hauschke, D; Steinijans, VW (1992). "Sample size determination for bioequivalence assessment by means of confidence intervals". International journal of clinical pharmacology, therapy, and toxicology. 30 Suppl 1: S51–8. PMID 1601532.
- ↑ Julious, Steven A.; Debarnot, Camille A. M. (2000). "Why Are Pharmacokinetic Data Summarized by Arithmetic Means?". Journal of Biopharmaceutical Statistics 10 (1): 55–71. doi:10.1081/BIP-100101013. PMID 10709801.
- ↑ Reed, JF; Lynn, F; Meade, BD (2002). "Use of Coefficient of Variation in Assessing Variability of Quantitative Assays". Clin Diagn Lab Immunol 9 (6): 1235–1239. doi:10.1128/CDLI.9.6.1235-1239.2002.
- ↑ Sawant,S.; Mohan, N. (2011) "FAQ: Issues with Efficacy Analysis of Clinical Trial Data Using SAS", PharmaSUG2011, Paper PO08
- ↑ Schiff, MH; et al. (2014). "Head-to-head, randomised, crossover study of oral versus subcutaneous methotrexate in patients with rheumatoid arthritis: drug-exposure limitations of oral methotrexate at doses >=15 mg may be overcome with subcutaneous administration". Ann Rheum Dis 73: 1–3. doi:10.1136/annrheumdis-2014-205228.
- ↑ Kirkwood, TBL (1979). "Geometric means and measures of dispersion". Biometrics 35: 908–9. JSTOR 2530139.
- ↑ Eisenberg, Dan (2015). "Improving qPCR telomere length assays: Controlling for well position effects increases statistical power". American Journal of Human Biology 27: 570–5. doi:10.1002/ajhb.22690. PMID 25757675.
- ↑ Broverman, Samuel A. (2001). Actex study manual, Course 1, Examination of the Society of Actuaries, Exam 1 of the Casualty Actuarial Society (2001 ed.). Winsted, CT: Actex Publications. p. 104. ISBN 9781566983969. Retrieved 7 June 2014.
- ↑ Rodbard, D (October 1974). "Statistical quality control and routine data processing for radioimmunoassays and immunoradiometric assays.". Clinical Chemistry 20 (10): 1255–70. PMID 4370388.
- ↑ Eisenberg, Dan (2015). "Improving qPCR telomere length assays: Controlling for well position effects increases statistical power". American Journal of Human Biology 27: 570–5. doi:10.1002/ajhb.22690. PMID 25757675.
- ↑ Hendricks, Walter A.; Robey, Kate W. (1936). "The Sampling Distribution of the Coefficient of Variation". The Annals of Mathematical Statistics 7 (3): 129–32. doi:10.1214/aoms/1177732503. JSTOR 2957564.
- ↑ Iglevicz, Boris; Myers, Raymond (1970). "Comparisons of approximations to the percentage points of the sample coefficient of variation". Technometrics 12 (1): 166–169. doi:10.2307/1267363. JSTOR 1267363.
- ↑ Bennett, B. M. (1976). "On an approximate test for homogeneity of coefficients of variation". Contributions to Applied Statistics Dedicated to A. Linder. Experentia Suppl 22: 169–171.
- ↑ Vangel, Mark G. (1996). "Confidence intervals for a normal coefficient of variation". The American Statistician 50 (1): 21–26. doi:10.1080/00031305.1996.10473537. JSTOR 2685039..
- ↑ Forkman, Johannes. "Estimator and tests for common coefficients of variation in normal distributions" (PDF). Communications in Statistics - Theory and Methods. pp. 21–26. doi:10.1080/03610920802187448. Retrieved 2013-09-23.
- ↑ , p.3
- ↑ Lehmann, E. L. (1986). Testing Statistical Hypothesis. 2nd ed. New York: Wiley.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||