Typical subspace
In quantum information theory, the idea of a typical subspace plays an important role in the proofs of many coding theorems (the most prominent example being Schumacher compression). Its role is analogous to that of the typical set in classical information theory.
Unconditional Quantum Typicality
Consider a density operator  with the following spectral decomposition:
with the following spectral decomposition:

The weakly typical subspace is defined as the span of all vectors such that
the sample entropy 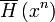 of their classical
label is close to the true entropy
of their classical
label is close to the true entropy 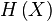 of the distribution
of the distribution
 :
:
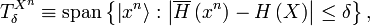
where
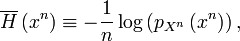
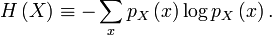
The projector 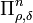 onto the typical subspace of is
defined as
onto the typical subspace of is
defined as

where we have "overloaded" the symbol
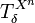 to refer also to the set of
to refer also to the set of 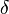 -typical sequences:
-typical sequences:
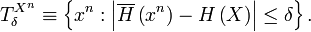
The three important properties of the typical projector are as follows:
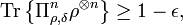
![\text{Tr}\left\{ \Pi_{\rho,\delta}^{n}\right\} \leq2^{n\left[ H\left(
X\right) +\delta\right] },](../I/m/da0c7d49b513ca076ec310c72410412b.png)
![2^{-n\left[ H\left( X\right) +\delta\right] }\Pi_{\rho,\delta}^{n}
\leq\Pi_{\rho,\delta}^{n}\rho^{\otimes n}\Pi_{\rho,\delta}^{n}\leq2^{-n\left[
H\left( X\right) -\delta\right] }\Pi_{\rho,\delta}^{n},](../I/m/61d1279511fd99494e8c9c6059be3ced.png)
where the first property holds for arbitrary 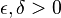 and
sufficiently large
and
sufficiently large  .
.
Conditional Quantum Typicality
Consider an ensemble 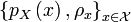 of states. Suppose that each state
of states. Suppose that each state  has the
following spectral decomposition:
has the
following spectral decomposition:
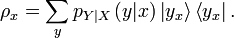
Consider a density operator 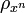 which is conditional on a classical
sequence
which is conditional on a classical
sequence 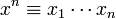 :
:
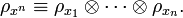
We define the weak conditionally typical subspace as the span of vectors
(conditional on the sequence  ) such that the sample conditional entropy
) such that the sample conditional entropy
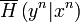 of their classical labels is close
to the true conditional entropy
of their classical labels is close
to the true conditional entropy 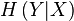 of the distribution
of the distribution
 :
:
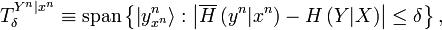
where
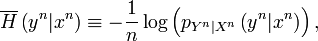

The projector 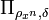 onto the weak conditionally typical
subspace of is as follows:
onto the weak conditionally typical
subspace of is as follows:
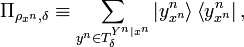
where we have again overloaded the symbol 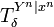 to refer
to the set of weak conditionally typical sequences:
to refer
to the set of weak conditionally typical sequences:
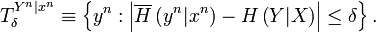
The three important properties of the weak conditionally typical projector are as follows:
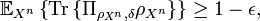
![\text{Tr}\left\{ \Pi_{\rho_{x^{n}},\delta}\right\} \leq2^{n\left[
H\left( Y|X\right) +\delta\right] },](../I/m/d5103e4bb0d39f59e5d624d9b05f680a.png)
![2^{-n\left[ H\left( Y|X\right) +\delta\right] }\ \Pi_{\rho_{x^{n}}
,\delta} \leq\Pi_{\rho_{x^{n}},\delta}\ \rho_{x^{n}}\ \Pi_{\rho_{x^{n}
},\delta} \leq2^{-n\left[ H\left( Y|X\right) -\delta\right] }\ \Pi
_{\rho_{x^{n}},\delta},](../I/m/d05867f2c3be507600719f7af0f8f5e8.png)
where the first property holds for arbitrary and
sufficiently large , and the expectation is with respect to the
distribution  .
.
See also
References
- Mark M. Wilde, "From Classical to Quantum Shannon Theory", arXiv:1106.1445.
| ||||||||||||||||||||||||||||||||||||||||||||||
