Two-way analysis of variance
In statistics, the two-way analysis of variance (ANOVA) is an extension of the one-way ANOVA that examines the influence of two different categorical independent variables on one continuous dependent variable. The two-way ANOVA not only aims at assessing the main effect of each independent variable but also if there is any interaction between them.
History
In 1925, Ronald Fisher mentions the two-way ANOVA in his celebrated book from 1925, Statistical Methods for Research Workers (chapters 7 and 8). In 1934, Frank Yates published procedures for the unbalanced case.[1] Since then, an extensive literature has been produced, reviewed in 1993 by Yasunori Fujikoshi.[2] In 2005, Andrew Gelman proposed a different approach of ANOVA, viewed as a multilevel model.[3]
Data set
Let us imagine a data set for which a dependent variable may be influenced by two factors which are potential sources of variation. The first factor has  levels (
levels (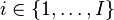 ) and the second has
) and the second has 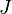 levels (
levels (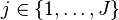 ). Each combination
). Each combination  defines a treatment, for a total of
defines a treatment, for a total of 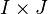 treatments. We represent the number of replicates for treatment by
treatments. We represent the number of replicates for treatment by  , and let
, and let  be the index of the replicate in this treatment (
be the index of the replicate in this treatment (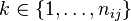 ).
).
From these data, we can build a contingency table, where 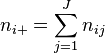 and
and 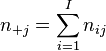 , and the total number of replicates is equal to
, and the total number of replicates is equal to 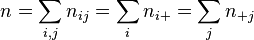 .
.
The experimental design is balanced if each treatment has the same number of replicates, 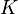 . In such a case, the design is also said to be orthogonal, allowing to fully distinguish the effects of both factors. We hence can write
. In such a case, the design is also said to be orthogonal, allowing to fully distinguish the effects of both factors. We hence can write 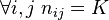 , and
, and 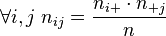 .
.
Model
Upon observing variation among all  data points, for instance via a histogram, "probability may be used to describe such variation".[4] Let us hence denote by
data points, for instance via a histogram, "probability may be used to describe such variation".[4] Let us hence denote by 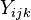 the random variable which observed value
the random variable which observed value 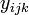 is the -th measure for treatment . The two-way ANOVA models all these variables as varying independently and normally around a mean,
is the -th measure for treatment . The two-way ANOVA models all these variables as varying independently and normally around a mean,  , with a constant variance,
, with a constant variance,  (homoscedasticity):
(homoscedasticity):
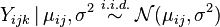 .
.
Specifically, the mean of the response variable is modeled as a linear combination of the explanatory variables:
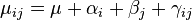 ,
,
where 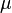 is the grand mean,
is the grand mean,  is the additive main effect of level
is the additive main effect of level  from the first factor (i-th row in the contigency table),
from the first factor (i-th row in the contigency table), 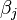 is the additive main effect of level
is the additive main effect of level 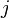 from the second factor (j-th column in the contigency table) and
from the second factor (j-th column in the contigency table) and 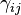 is the non-additive interaction effect of treatment from both factors (cell at row i and column j in the contigency table).
is the non-additive interaction effect of treatment from both factors (cell at row i and column j in the contigency table).
An other, equivalent way of describing the two-way ANOVA is by mentioning that, besides the variation explained by the factors, there remains some statistical noise. This amount of unexplained variation is handled via the introduction of one random variable per data point,  , called error. These random variables are seen as deviations from the means, and are assumed to be independent and normally distributed:
, called error. These random variables are seen as deviations from the means, and are assumed to be independent and normally distributed:
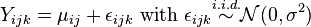 .
.
Assumptions
Following Gelman and Hill, the assumptions of the ANOVA, and more generally the general linear model, are, in decreasing order of importance:[5]
- the data points are relevant with respect to the scientific question under investigation;
- the mean of the response variable is influenced additively (if not interaction term) and linearly by the factors;
- the errors are independent;
- the errors have the same variance;
- the errors are normally distributed.
Parameter estimation
To ensure identifiability of parameters, we can add the following "sum-to-zero" constraints:
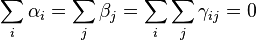
Hypothesis testing
In the classical approach, testing null hypotheses (that the factors have no effect) is achieved via their significance which requires calculating sums of squares.
Testing if the interaction term is significant can be difficult because of the potentially-large number of degrees of freedom.[6]
See also
- Analysis of variance
- One-way ANOVA
- F test (Includes a one-way ANOVA example)
- Repeated measures ANOVA
- Multivariate analysis of variance (MANOVA)
- Tukey's test of additivity
- Mixed model
References
- George Casella (18 April 2008). Statistical design. Springer. ISBN 978-0-387-75965-4.
Notes
- ↑ Yates, Frank (March 1934). "The analysis of multiple classifications with unequal numbers in the different classes". Journal of the American Statistical Association (American Statistical Association) 29 (185): 51–66. doi:10.1080/01621459.1934.10502686. Retrieved 19 June 2014.
- ↑ Fujikoshi, Yasunori (1993). "Two-way ANOVA models with unbalanced data". Discrete Mathematics (Elsevier) 116 (1): 315–334. doi:10.1016/0012-365X(93)90410-U. Retrieved 19 June 2014.
- ↑ Gelman, Andrew (February 2005). "Analysis of variance? why it is more important than ever". The Annals of Statistics 33 (1): 1–53. doi:10.1214/009053604000001048. Retrieved 19 June 2014.
- ↑ Kass, Robert E (1 February 2011). "Statistical inference: The big picture". Statistical Science (Institute of Mathematical Statistics) 26 (1): 1–9. doi:10.1214/10-sts337.
- ↑ Gelman, Andrew; Hill, Jennifer (18 December 2006). Data Analysis Using Regression and Multilevel/Hierarchical Models. Cambridge University Press. pp. 45–46. ISBN 0521867061.
- ↑ Yi-An Ko; et al. (September 2013). "Novel Likelihood Ratio Tests for Screening Gene-Gene and Gene-Environment Interactions with Unbalanced Repeated-Measures Data". Genetic epidemiology 37 (6): 581–591. doi:10.1002/gepi.21744. Retrieved 19 June 2014.