Tree decomposition

In graph theory, a tree decomposition is a mapping of a graph into a tree that can be used to define the treewidth of the graph and speed up solving certain computational problems on the graph.
In machine learning, tree decompositions are also called junction trees, clique trees, or join trees; they play an important role in problems like probabilistic inference, constraint satisfaction, query optimization, and matrix decomposition.
The concept of tree decompositions was originally introduced by Rudolf Halin (1976). Later it was rediscovered by Neil Robertson and Paul Seymour (1984) and has since been studied by many other authors.[1]
Definition
Intuitively, a tree decomposition represents the vertices of a given graph G as subtrees of a tree, in such a way that vertices in the given graph are adjacent only when the corresponding subtrees intersect. Thus, G forms a subgraph of the intersection graph of the subtrees. The full intersection graph is a chordal graph.
Each subtree associates a graph vertex with a set of tree nodes. To define this formally, we represent each tree node as the set of vertices associated with it. Thus, given a graph G = (V, E), a tree decomposition is a pair (X, T), where X = {X1, ..., Xn} is a family of subsets of V, and T is a tree whose nodes are the subsets Xi, satisfying the following properties:[2]
- The union of all sets Xi equals V. That is, each graph vertex is associated with at least one tree node.
- For every edge (v, w) in the graph, there is a subset Xi that contains both v and w. That is, vertices are adjacent in the graph only when the corresponding subtrees have a node in common.
- If Xi and Xj both contain a vertex v, then all nodes Xk of the tree in the (unique) path between Xi and Xj contain v as well. That is, the nodes associated with vertex v form a connected subset of T. This is also known as coherence, or the running intersection property. It can be stated equivalently that if
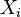 ,
,  and
and  are nodes, and is on the path from to , then
are nodes, and is on the path from to , then  .
.
The tree decomposition of a graph is far from unique; for example, a trivial tree decomposition contains all vertices of the graph in its single root node.
A tree decomposition in which the underlying tree is a path graph is called a path decomposition, and the width parameter derived from these special types of tree decompositions is known as pathwidth.
A tree decomposition (X, T = (I, F)) of treewidth k is smooth, if for all  , and for all
, and for all  .[3]
.[3]
Treewidth

The width of a tree decomposition is the size of its largest set Xi minus one. The treewidth tw(G) of a graph G is the minimum width among all possible tree decompositions of G. In this definition, the size of the largest set is diminished by one in order to make the treewidth of a tree equal to one. Treewidth may also be defined from other structures than tree decompositions, including chordal graphs, brambles, and havens.
It is NP-complete to determine whether a given graph G has treewidth at most a given variable k.[4] However, when k is any fixed constant, the graphs with treewidth k can be recognized, and a width k tree decomposition constructed for them, in linear time.[3] The time dependence of this algorithm on k is exponential.
Dynamic programming
At the beginning of the 1970s, it was observed that a large class of combinatorial optimization problems defined on graphs could be efficiently solved by non serial dynamic programming as long as the graph had a bounded dimension,[5] a parameter related to treewidth. Later, several authors independently observed at the end of the 1980s[6] that many algorithmic problems that are NP-complete for arbitrary graphs may be solved efficiently by dynamic programming for graphs of bounded treewidth, using the tree-decompositions of these graphs.
As an example, consider the problem of finding the maximum independent set in a graph of treewidth k. To solve this problem, first choose one of the nodes of the tree decomposition to be the root, arbitrarily. For a node Xi of the tree decomposition, let Di be the union of the sets Xj descending from Xi. For an independent set S ⊂ Xi, let A(S,i) denote the size of the largest independent subset I of Di such that I ∩ Xi = S. Similarly, for an adjacent pair of nodes Xi and Xj, with Xi farther from the root of the tree than Xj, and an independent set S ⊂ Xi ∩ Xj, let B(S,i,j) denote the size of the largest independent subset I of Di such that I ∩ Xi ∩ Xj = S. We may calculate these A and B values by a bottom-up traversal of the tree:


where the sum in the calculation of  is over the children of node .
is over the children of node .
At each node or edge, there are at most 2k sets S for which we need to calculate these values, so if k is a constant then the whole calculation takes constant time per edge or node. The size of the maximum independent set is the largest value stored at the root node, and the maximum independent set itself can be found (as is standard in dynamic programming algorithms) by backtracking through these stored values starting from this largest value. Thus, in graphs of bounded treewidth, the maximum independent set problem may be solved in linear time. Similar algorithms apply to many other graph problems.
This dynamic programming approach is used in machine learning via the junction tree algorithm for belief propagation in graphs of bounded treewidth. It also plays a key role in algorithms for computing the treewidth and constructing tree decompositions: typically, such algorithms have a first step that approximates the treewidth, constructing a tree decomposition with this approximate width, and then a second step that performs dynamic programming in the approximate tree decomposition to compute the exact value of the treewidth.[3]
See also
- Brambles and havens, two kinds of structures that can be used as an alternative to tree decomposition in defining the treewidth of a graph
- Branch-decomposition, a closely related structure whose width is within a constant factor of treewidth
- Decomposition Method, Tree Decomposition is used in Decomposition Method for solving onstraint satisfaction problem.
Notes
References
- Arnborg, S.; Corneil, D.; Proskurowski, A. (1987), "Complexity of finding embeddings in a k-tree", SIAM Journal on Matrix Analysis and Applications 8 (2): 277–284, doi:10.1137/0608024.
- Arnborg, S.; Proskurowski, A. (1989), "Linear time algorithms for NP-hard problems restricted to partial k-trees", Discrete Applied Mathematics 23 (1): 11–24, doi:10.1016/0166-218X(89)90031-0.
- Bern, M. W.; Lawler, E. L.; Wong, A. L. (1987), "Linear-time computation of optimal subgraphs of decomposable graphs", Journal of Algorithms 8 (2): 216–235, doi:10.1016/0196-6774(87)90039-3.
- Bertelé, Umberto; Brioschi, Francesco (1972), Nonserial Dynamic Programming, Academic Press, ISBN 0-12-093450-7.
- Bodlaender, Hans L. (1988), "Dynamic programming on graphs with bounded treewidth", Proc. 15th International Colloquium on Automata, Languages and Programming, Lecture Notes in Computer Science 317, Springer-Verlag, pp. 105–118, doi:10.1007/3-540-19488-6_110.
- Bodlaender, Hans L. (1996), "A linear time algorithm for finding tree-decompositions of small treewidth", SIAM Journal on Computing 25 (6): 1305–1317, doi:10.1137/S0097539793251219.
- Diestel, Reinhard (2005), Graph Theory (3rd ed.), Springer, ISBN 3-540-26182-6.
- Halin, Rudolf (1976), "S-functions for graphs", Journal of Geometry 8: 171–186, doi:10.1007/BF01917434.
- Robertson, Neil; Seymour, Paul D. (1984), "Graph minors III: Planar tree-width", Journal of Combinatorial Theory, Series B 36 (1): 49–64, doi:10.1016/0095-8956(84)90013-3.