Total correlation
In probability theory and in particular in information theory, total correlation (Watanabe 1960) is one of several generalizations of the mutual information. It is also known as the multivariate constraint (Garner 1962) or multiinformation (Studený & Vejnarová 1999). It quantifies the redundancy or dependency among a set of n random variables.
Definition
For a given set of n random variables 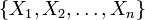 , the total correlation
, the total correlation 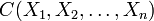 is defined as the Kullback–Leibler divergence from the joint distribution
is defined as the Kullback–Leibler divergence from the joint distribution 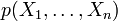 to the independent distribution of
to the independent distribution of 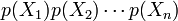 ,
,
![C(X_1, X_2, \ldots, X_n) \equiv \operatorname{D_{KL}}\left[ p(X_1, \ldots, X_n) \| p(X_1)p(X_2)\cdots p(X_n)\right] \; .](../I/m/d6d540ba96d7d041471d973c8aeb0a08.png)
This divergence reduces to the simpler difference of entropies,
![C(X_1,X_2,\ldots,X_n) = \left[\sum_{i=1}^n H(X_i)\right] - H(X_1, X_2, \ldots, X_n)](../I/m/d812b5fd44e764e0927a75042245bb74.png)
where 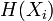 is the information entropy of variable
is the information entropy of variable 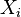 , and
, and 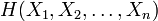 is the joint entropy of the variable set . In terms of the discrete probability distributions on variables , the total correlation is given by
is the joint entropy of the variable set . In terms of the discrete probability distributions on variables , the total correlation is given by
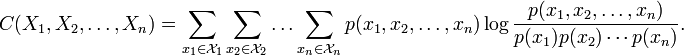
The total correlation is the amount of information shared among the variables in the set. The sum 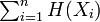 represents the amount of information in bits (assuming base-2 logs) that the variables would possess if they were totally independent of one another (non-redundant), or, equivalently, the average code length to transmit the values of all variables if each variable was (optimally) coded independently. The term
represents the amount of information in bits (assuming base-2 logs) that the variables would possess if they were totally independent of one another (non-redundant), or, equivalently, the average code length to transmit the values of all variables if each variable was (optimally) coded independently. The term  is the actual amount of information that the variable set contains, or equivalently, the average code length to transmit the values of all variables if the set of variables was (optimally) coded together. The difference between
these terms therefore represents the absolute redundancy (in bits) present in the given
set of variables, and thus provides a general quantitative measure of the
structure or organization embodied in the set of variables
(Rothstein 1952). The total correlation is also the Kullback–Leibler divergence between the actual distribution
is the actual amount of information that the variable set contains, or equivalently, the average code length to transmit the values of all variables if the set of variables was (optimally) coded together. The difference between
these terms therefore represents the absolute redundancy (in bits) present in the given
set of variables, and thus provides a general quantitative measure of the
structure or organization embodied in the set of variables
(Rothstein 1952). The total correlation is also the Kullback–Leibler divergence between the actual distribution 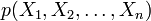 and its maximum entropy product approximation .
and its maximum entropy product approximation .
Total correlation quantifies the amount of dependence among a group of variables. A near-zero total correlation indicates that the variables in the group are essentially statistically independent; they are completely unrelated, in the sense that knowing the value of one variable does not provide any clue as to the values of the other variables. On the other hand, the maximum total correlation (for a fixed set of individual entropies H(X_i), ..., H(X_n)) is given by

and occurs when one of the variables determines all of the other variables. The variables are then maximally related in the sense that knowing the value of one variable provides complete information about the values of all the other variables, and the variables can be figuratively regarded as cogs, in which the position of one cog determines the positions of all the others (Rothstein 1952).
It is important to note that the total correlation counts up all the redundancies among a set of variables, but that these redundancies may be distributed throughout the variable set in a variety of complicated ways (Garner 1962). For example, some variables in the set may be totally inter-redundant while others in the set are completely independent. Perhaps more significantly, redundancy may be carried in interactions of various degrees: A group of variables may not possess any pairwise redundancies, but may possess higher-order interaction redundancies of the kind exemplified by the parity function. The decomposition of total correlation into its constituent redundancies is explored in a number sources (Mcgill 1954, Watanabe 1960, Garner 1962, Studeny & Vejnarova 1999, Jakulin & Bratko 2003a, Jakulin & Bratko 2003b, Nemenman 2004, Margolin et al. 2008, Han 1978, Han 1980).
Conditional total correlation
Conditional total correlation is defined analogously to the total correlation, but adding a condition to each term. Conditional total correlation is similarly defined as a Kullback-Leibler divergence between two conditional probability distributions,
![C(X_1, X_2, \ldots, X_n|Y=y) \equiv \operatorname{D_{KL}}\left[ p(X_1, \ldots, X_n|Y=y) \| p(X_1|Y=y)p(X_2|Y=y)\cdots p(X_n|Y=y)\right] \; .](../I/m/2ebba69267345071f5a0324ace8e099f.png)
Analogous to the above, conditional total correlation reduces to a difference of conditional entropies,
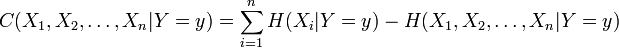
Uses of total correlation
Clustering and feature selection algorithms based on total correlation have been explored by Watanabe. Alfonso et al. (2010) applied the concept of total correlation to the optimisation of water monitoring networks.
See also
References
- Alfonso, L., Lobbrecht, A., and Price, R. (2010). Optimization of Water Level Monitoring Network in Polder Systems Using Information Theory, Water Resources Research, 46, W12553, 13 PP., 2010, doi:10.1029/2009WR008953.
- Garner W R (1962). Uncertainty and Structure as Psychological Concepts, JohnWiley & Sons, New York.
- Han T S (1978). Nonnegative entropy measures of multivariate symmetric correlations, Information and Control 36, 133–156.
- Han T S (1980). Multiple mutual information and multiple interactions in frequency data, Information and Control 46, 26–45.
- Jakulin A & Bratko I (2003a). Analyzing Attribute Dependencies, in N Lavra\quad{c}, D Gamberger, L Todorovski & H Blockeel, eds, Proceedings of the 7th European Conference on Principles and Practice of Knowledge Discovery in Databases, Springer, Cavtat-Dubrovnik, Croatia, pp. 229–240.
- Jakulin A & Bratko I (2003b). Quantifying and visualizing attribute interactions .
- Margolin A, Wang K, Califano A, & Nemenman I (2010). Multivariate dependence and genetic networks inference. IET Syst Biol 4, 428.
- McGill W J (1954). Multivariate information transmission, Psychometrika 19, 97–116.
- Nemenman I (2004). Information theory, multivariate dependence, and genetic network inference .
- Rothstein J (1952). Organization and entropy, Journal of Applied Physics 23, 1281–1282.
- Studený M & Vejnarová J (1999). The multiinformation function as a tool for measuring stochastic dependence, in M I Jordan, ed., Learning in Graphical Models, MIT Press, Cambridge, MA, pp. 261–296.
- Watanabe S (1960). Information theoretical analysis of multivariate correlation, IBM Journal of Research and Development 4, 66–82.