Term indexing
In computer science, a term index is a data structure to facilitate fast lookup of terms and clauses in a logic program,[1] deductive database, or automated theorem prover.
Many operations in automatic theorem provers require search in huge collections of terms and clauses. Such operations typically fall into the following scheme. Given a collection 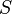 of terms (clauses) and a query term (clause)
of terms (clauses) and a query term (clause) 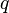 , find in some/all terms
, find in some/all terms  related to according to a certain retrieval condition. Most interesting retrieval conditions are formulated as existence of a substitution that relates in a special way the query and the retrieved objects . Here is a list of retrieval conditions frequently used in provers:
related to according to a certain retrieval condition. Most interesting retrieval conditions are formulated as existence of a substitution that relates in a special way the query and the retrieved objects . Here is a list of retrieval conditions frequently used in provers:
- term is unifiable with term , i.e., there exists a substitution
 , such that
, such that 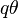 =
= 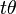
- term is an instance of , i.e., there exists a substitution , such that =
- term is a generalisation of , i.e., there exists a substitution , such that =
- clause subsumes clause , i.e., there exists a substitution , such that is a subset/submultiset of
- clause is subsumed by , i.e., there exists a substitution , such that is a subset/submultiset of
More often than not, we are actually interested in finding the appropriate
substitutions explicitly, together with the retrieved terms ,
rather than just in establishing existence of such substitutions.
Very often the sizes of term sets to be searched are large,
the retrieval calls are frequent and the retrieval condition test
is rather complex. In such situations linear search in , when the retrieval
condition is tested on every term from , becomes prohibitively costly.
To overcome this problem, special data structures, called indexes, are
designed in order to support fast retrieval. Such data structures,
together with the accompanying algorithms for index maintenance
and retrieval, are called term indexing techniques.
Classic indexing techniques
- discrimination trees
- substitution trees
- path indexing
Modern indexing techniques
- feature vector indexing
- code trees
- context trees
- relational path indexing
References
- ↑ Colomb, Robert M. (1991). "Enhancing unification in PROLOG through clause indexing". The Journal of Logic Programming 10: 23. doi:10.1016/0743-1066(91)90004-9.
Further reading
- P. Graf, Term Indexing, Lecture Notes in Computer Science 1053, 1996 (slightly outdated overview)
- R. Sekar and I.V. Ramakrishnan and A. Voronkov, Term Indexing, in A. Robinson and A. Voronkov, editors, Handbook of Automated Reasoning, volume 2, 2001 (recent overview)
- W. W. McCune, Experiments with Discrimination-Tree Indexing and Path Indexing for Term Retrieval, Journal of Automated Reasoning, 9(2), 1992
- P. Graf, Substitution Tree Indexing, Proc. of RTA, Lecture Notes in Computer Science 914, 1995
- M. Stickel, The Path Indexing Method for Indexing Terms, Tech. Rep. 473, Artificial Intelligence Center, SRI International, 1989
- S. Schulz, Simple and Efficient Clause Subsumption with Feature Vector Indexing, Proc. of IJCAR-2004 workshop ESFOR, 2004
- A. Riazanov and A. Voronkov, Partially Adaptive Code Trees, Proc. JELIA, Lecture Notes in Artificial Intelligence 1919, 2000
- H. Ganzinger and R. Nieuwenhuis and P. Nivela, Fast Term Indexing with Coded Context Trees, Journal of Automated Reasoning, 32(2), 2004
- A. Riazanov and A. Voronkov, Efficient Instance Retrieval with Standard and Relational Path Indexing, Information and Computation, 199(1–2), 2005