Kendall rank correlation coefficient
In statistics, the Kendall rank correlation coefficient, commonly referred to as Kendall's tau coefficient (after the Greek letter τ), is a statistic used to measure the association between two measured quantities. A tau test is a non-parametric hypothesis test for statistical dependence based on the tau coefficient.
It is a measure of rank correlation: the similarity of the orderings of the data when ranked by each of the quantities. It is named after Maurice Kendall, who developed it in 1938,[1] though Gustav Fechner had proposed a similar measure in the context of time series in 1897.[2]
Definition
Let (x1, y1), (x2, y2), …, (xn, yn) be a set of observations of the joint random variables X and Y respectively, such that all the values of (xi) and (yi) are unique. Any pair of observations (xi, yi) and (xj, yj), where 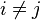 , are said to be concordant if the ranks for both elements agree: that is, if both xi > xj and yi > yj or if both xi < xj and yi < yj. They are said to be discordant, if xi > xj and yi < yj or if xi < xj and yi > yj. If xi = xj or yi = yj, the pair is neither concordant nor discordant.
, are said to be concordant if the ranks for both elements agree: that is, if both xi > xj and yi > yj or if both xi < xj and yi < yj. They are said to be discordant, if xi > xj and yi < yj or if xi < xj and yi > yj. If xi = xj or yi = yj, the pair is neither concordant nor discordant.
The Kendall τ coefficient is defined as:
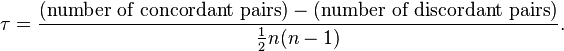
Properties
The denominator is the total number of pair combinations, so the coefficient must be in the range −1 ≤ τ ≤ 1.
- If the agreement between the two rankings is perfect (i.e., the two rankings are the same) the coefficient has value 1.
- If the disagreement between the two rankings is perfect (i.e., one ranking is the reverse of the other) the coefficient has value −1.
- If X and Y are independent, then we would expect the coefficient to be approximately zero.
Hypothesis test
The Kendall rank coefficient is often used as a test statistic in a statistical hypothesis test to establish whether two variables may be regarded as statistically dependent. This test is non-parametric, as it does not rely on any assumptions on the distributions of X or Y or the distribution of (X,Y).
Under the null hypothesis of independence of X and Y, the sampling distribution of τ has an expected value of zero. The precise distribution cannot be characterized in terms of common distributions, but may be calculated exactly for small samples; for larger samples, it is common to use an approximation to the normal distribution, with mean zero and variance
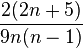 .[4]
.[4]
Accounting for ties
A pair {(xi, yi), (xj, yj)} is said to be tied if xi = xj or yi = yj; a tied pair is neither concordant nor discordant. When tied pairs arise in the data, the coefficient may be modified in a number of ways to keep it in the range [−1, 1]:
Tau-a
The Tau-a statistic tests the strength of association of the cross tabulations. Both variables have to be ordinal. Tau-a will not make any adjustment for ties. It is defined as:
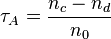
where nc, nd and n0 are defined as in the next section.
Tau-b
The Tau-b statistic, unlike Tau-a, makes adjustments for ties.[5] Values of Tau-b range from −1 (100% negative association, or perfect inversion) to +1 (100% positive association, or perfect agreement). A value of zero indicates the absence of association.
The Kendall Tau-b coefficient is defined as:
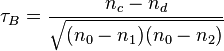
where

Tau-c
Tau-c differs from Tau-b as in being more suitable for rectangular tables than for square tables.
Significance tests
When two quantities are statistically independent, the distribution of 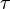 is not easily characterizable in terms of known distributions. However, for
is not easily characterizable in terms of known distributions. However, for  the following statistic,
the following statistic, 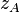 , is approximately distributed as a standard normal when the variables are statistically independent:
, is approximately distributed as a standard normal when the variables are statistically independent:
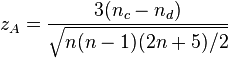
Thus, to test whether two variables are statistically dependent, one computes , and finds the cumulative probability for a standard normal distribution at 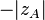 . For a 2-tailed test, multiply that number by two to obtain the p-value. If the p-value is below a given significance level, one rejects the null hypothesis (at that significance level) that the quantities are statistically independent.
. For a 2-tailed test, multiply that number by two to obtain the p-value. If the p-value is below a given significance level, one rejects the null hypothesis (at that significance level) that the quantities are statistically independent.
Numerous adjustments should be added to when accounting for ties. The following statistic, 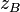 , has the same distribution as the
, has the same distribution as the 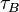 distribution, and is again approximately equal to a standard normal distribution when the quantities are statistically independent:
distribution, and is again approximately equal to a standard normal distribution when the quantities are statistically independent:
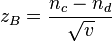
where
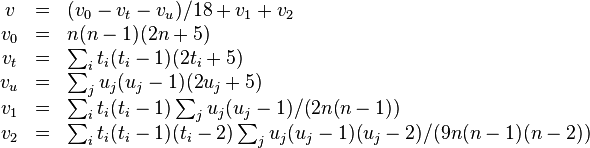
pvrank[6] is a very recent R package that computes rank correlations and their p-values with various options for tied ranks. It is possible to compute exact Kendall coefficient test p-values for n ≤ 60.
Algorithms
The direct computation of the numerator 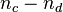 , involves two nested iterations, as characterized by the following pseudo-code:
, involves two nested iterations, as characterized by the following pseudo-code:
numer := 0 for i:=2..N do for j:=1..(i-1) do numer := numer + sign(x[i] - x[j]) * sign(y[i] - y[j]) return numer
Although quick to implement, this algorithm is  in complexity and becomes very slow on large samples. A more sophisticated algorithm[7] built upon the Merge Sort algorithm can be used to compute the numerator in
in complexity and becomes very slow on large samples. A more sophisticated algorithm[7] built upon the Merge Sort algorithm can be used to compute the numerator in 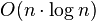 time.
time.
Begin by ordering your data points sorting by the first quantity,  , and secondarily (among ties in ) by the second quantity,
, and secondarily (among ties in ) by the second quantity, 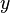 . With this initial ordering, is not sorted, and the core of the algorithm consists of computing how many steps a Bubble Sort would take to sort this initial . An enhanced Merge Sort algorithm, with
. With this initial ordering, is not sorted, and the core of the algorithm consists of computing how many steps a Bubble Sort would take to sort this initial . An enhanced Merge Sort algorithm, with  complexity, can be applied to compute the number of swaps,
complexity, can be applied to compute the number of swaps, 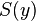 , that would be required by a Bubble Sort to sort
, that would be required by a Bubble Sort to sort 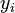 . Then the numerator for is computed as:
. Then the numerator for is computed as:
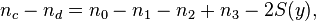
where 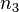 is computed like
is computed like  and
and  , but with respect to the joint ties in and .
, but with respect to the joint ties in and .
A Merge Sort partitions the data to be sorted, into two roughly equal halves, 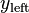 and
and 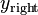 , then sorts each half recursive, and then merges the two sorted halves into a fully sorted vector. The number of Bubble Sort swaps is equal to:
, then sorts each half recursive, and then merges the two sorted halves into a fully sorted vector. The number of Bubble Sort swaps is equal to:
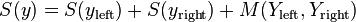
where 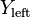 and
and 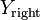 are the sorted versions of and , and
are the sorted versions of and , and 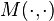 characterizes the Bubble Sort swap-equivalent for a merge operation. is computed as depicted in the following pseudo-code:
characterizes the Bubble Sort swap-equivalent for a merge operation. is computed as depicted in the following pseudo-code:
function M(L[1..n], R[1..m])
i := 1
j := 1
nSwaps := 0
while i <= n and j <= m do
if R[j] < L[i] then
nSwaps := nSwaps + n - i + 1
j := j + 1
else
i := i + 1
return nSwaps
A side effect of the above steps is that you end up with both a sorted version of and a sorted version of . With these, the factors  and
and 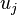 used to compute are easily obtained in a single linear-time pass through the sorted arrays.
used to compute are easily obtained in a single linear-time pass through the sorted arrays.
See also
- Correlation
- Kendall tau distance
- Kendall's W
- Spearman's rank correlation coefficient
- Goodman and Kruskal's gamma
- Theil–Sen estimator
References
- ↑ Kendall, M. (1938). "A New Measure of Rank Correlation". Biometrika 30 (1–2): 81–89. doi:10.1093/biomet/30.1-2.81. JSTOR 2332226.
- ↑ Kruskal, W.H. (1958). "Ordinal Measures of Association". Journal of the American Statistical Association 53 (284): 814–861. doi:10.2307/2281954. JSTOR 2281954. MR 100941.
- ↑ Nelsen, R.B. (2001), "Kendall tau metric", in Hazewinkel, Michiel, Encyclopedia of Mathematics, Springer, ISBN 978-1-55608-010-4
- ↑ Prokhorov, A.V. (2001), "Kendall coefficient of rank correlation", in Hazewinkel, Michiel, Encyclopedia of Mathematics, Springer, ISBN 978-1-55608-010-4
- ↑ Agresti, A. (2010). Analysis of Ordinal Categorical Data (Second ed.). New York: John Wiley & Sons.
- ↑ Amerise, I.L.; Marozzi, M.; Tarsitano, A. "R package pvrank".
- ↑ Knight, W. (1966). "A Computer Method for Calculating Kendall's Tau with Ungrouped Data". Journal of the American Statistical Association 61 (314): 436–439. doi:10.2307/2282833. JSTOR 2282833.
Further reading
- Abdi, H. (2007). "Kendall rank correlation" (PDF). In Salkind, N.J. Encyclopedia of Measurement and Statistics. Thousand Oaks (CA): Sage.
- Daniel, Wayne W. (1990). "Kendall's tau". Applied Nonparametric Statistics (2nd ed.). Boston: PWS-Kent. pp. 365–377. ISBN 0-534-91976-6.
- Kendall, M. (1948) Rank Correlation Methods, Charles Griffin & Company Limited
- Bonett, DG & Wright, TA (2000) Sample size requirements for Pearson, Kendall, and Spearman correlations, Psychometrika, 65, 23–28.
External links
- Tied rank calculation
- Software for computing Kendall's tau on very large datasets
- Online software: computes Kendall's tau rank correlation
- The CORR Procedure: Statistical Computations – McDonough School of Business
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||