Systolic array
In parallel computer architectures, a systolic array is a homogeneous network of tightly coupled Data Processing Units (DPUs) called cells or nodes. Each node or DPU independently computes a partial result as a function of the data received from its upstream neighbors, stores the result within itself and passes it downstream. Systolic arrays were invented by Richard P. Brent and H.T. Kung, who developed them to compute Greatest common divisors of integers and polynomials. [1] They are sometimes classified as Multiple Instruction Single Data (MISD) architectures under Flynn's Taxonomy, but this classification is questionable because a strong argument can be made to distinguish systolic arrays from any of Flynn's four categories: SISD, SIMD, MISD, MIMD, as discussed later in this article.
The parallel input data flows through a network of hard-wired processor nodes, resembling the human brain which combine, process, merge or sort the input data into a derived result. Because the wave-like propagation of data through a systolic array resembles the pulse of the human circulatory system, the name systolic was coined from medical terminology. The name is derived from Systole (medicine) as an analogy to the regular pumping of blood by the heart.
Applications
Systolic arrays are often hard-wired for specific operations, such as "multiply and accumulate", to perform massively parallel integration, convolution, correlation, matrix multiplication or data sorting tasks.
Architecture
A systolic array typically consists of a large monolithic network of primitive computing nodes which can be hardwired or software configured for a specific application. The nodes are usually fixed and identical, while the interconnect is programmable. The more general wavefront processors, by contrast, employ sophisticated and individually programmable nodes which may or may not be monolithic, depending on the array size and design parameters. The other distinction is that systolic arrays rely on synchronous data transfers, while wavefront tend to work asynchronously.
Unlike the more common Von Neumann architecture, where program execution follows a script of instructions stored in common memory, addressed and sequenced under the control of the CPU's program counter (PC), the individual nodes within a systolic array are triggered by the arrival of new data and always process the data in exactly the same way. The actual processing within each node may be hard wired or block microcoded, in which case the common node personality can be block programmable.
The systolic array paradigm with data-streams driven by data counters, is the counterpart of the Von Neumann architecture with instruction-stream driven by a program counter. Because a systolic array usually sends and receives multiple data streams, and multiple data counters are needed to generate these data streams, it supports data parallelism.
The actual nodes can be simple and hardwired or consist of more sophisticated units using micro code, which may be block programmable.
Goals and benefits
A major benefit of systolic arrays is that all operand data and partial results are stored within (passing through) the processor array. There is no need to access external buses, main memory or internal caches during each operation as is the case with Von Neumann or Harvard sequential machines. The sequential limits on parallel performance dictated by Amdahl's Law also do not apply in the same way, because data dependencies are implicitly handled by the programmable node interconnect and there are no sequential steps in managing the highly parallel data flow.
Systolic arrays are therefore extremely good at artificial intelligence, image processing, pattern recognition, computer vision and other tasks which animal brains do so particularly well. Wavefront processors in general can also be very good at machine learning by implementing self configuring neural nets in hardware.
Classification controversy
While systolic arrays are officially classified as MISD, their classification is somewhat problematic. Because the input is typically a vector of independent values, the systolic array is definitely not SISD. Since these input values are merged and combined into the result(s) and do not maintain their independence as they would in a SIMD vector processing unit, the array cannot be classified as such. Consequently, the array cannot be classified as a MIMD either, because MIMD can be viewed as a mere collection of smaller SISD and SIMD machines.
Finally, because the data swarm is transformed as it passes through the array from node to node, the multiple nodes are not operating on the same data, which makes the MISD classification a misnomer. The other reason why a systolic array should not qualify as a MISD is the same as the one which disqualifies it from the SISD category: The input data is typically a vector not a single data value, although one could argue that any given input vector is a single data set.
In spite of all of the above, systolic arrays are often offered as a classic example of MISD architecture in textbooks on parallel computing and in the engineering class. If the array is viewed from the outside as atomic it should perhaps be classified as SFMuDMeR = Single Function, Multiple Data, Merged Result(s).
Detailed description
A systolic array is composed of matrix-like rows of data processing units called cells. Data processing units (DPUs) are similar to central processing units (CPUs), (except for the usual lack of a program counter,[2] since operation is transport-triggered, i.e., by the arrival of a data object). Each cell shares the information with its neighbors immediately after processing. The systolic array is often rectangular where data flows across the array between neighbour DPUs, often with different data flowing in different directions. The data streams entering and leaving the ports of the array are generated by auto-sequencing memory units, ASMs. Each ASM includes a data counter. In embedded systems a data stream may also be input from and/or output to an external source.
An example of a systolic algorithm might be designed for matrix multiplication. One matrix is fed in a row at a time from the top of the array and is passed down the array, the other matrix is fed in a column at a time from the left hand side of the array and passes from left to right. Dummy values are then passed in until each processor has seen one whole row and one whole column. At this point, the result of the multiplication is stored in the array and can now be output a row or a column at a time, flowing down or across the array.[3]
Systolic arrays are arrays of DPUs which are connected to a small number of nearest neighbour DPUs in a mesh-like topology. DPUs perform a sequence of operations on data that flows between them. Because the traditional systolic array synthesis methods have been practiced by algebraic algorithms, only uniform arrays with only linear pipes can be obtained, so that the architectures are the same in all DPUs. The consequence is, that only applications with regular data dependencies can be implemented on classical systolic arrays. Like SIMD machines, clocked systolic arrays compute in "lock-step" with each processor undertaking alternate compute | communicate phases. But systolic arrays with asynchronous handshake between DPUs are called wavefront arrays. One well-known systolic array is Carnegie Mellon University's iWarp processor, which has been manufactured by Intel. An iWarp system has a linear array processor connected by data buses going in both directions.
History
Systolic arrays (< wavefront processors), were first described by H. T. Kung and Charles E. Leiserson, Who published the first paper describing systolic arrays in 1978. However, the first machine known to have used a similar technique was the Colossus Mark II in 1944.
Application example
An application Example - Polynomial Evaluation
Horner's rule for evaluating a polynomial is:
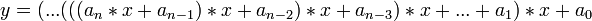
A linear systolic array in which the processors are arranged in pairs:
one multiplies its input by  and passes the result to the right,
the next adds
and passes the result to the right,
the next adds  and passes the result to the right:
and passes the result to the right:
Advantages and disadvantages
Pros
- Faster
- Scalable
Cons
- Expensive
- Highly specialized, custom hardware is required often application specific.
- Not widely implemented
- Limited code base of programs and algorithms.
Implementations
Cisco PXF network processor is internally organized as systolic array.[4]
See also
- MISD - Multiple Instruction Single Data, Example: Systolic Arrays
- iWarp - Systolic Array Computer, VLSI, Intel/CMU
- WARP (systolic array) - Systolic Array Computer, GE/CMU
Notes
- ↑ http://www.eecs.harvard.edu/~htk/publication/1984-ieeetoc-brent-kung.pdf
- ↑ The Paracel GeneMatcher series of systolic array processors do have a program counter. More complicated algorithms are implemented as a series of simple steps, with shifts specified in the instructions.
- ↑ Systolic Array Matrix Multiplication
- ↑ http://www.cisco.com/en/US/prod/collateral/routers/ps133/prod_white_paper09186a008008902a.html
References
- H. T. Kung, C. E. Leiserson: Algorithms for VLSI processor arrays; in: C. Mead, L. Conway (eds.): Introduction to VLSI Systems; Addison-Wesley, 1979
- S. Y. Kung: VLSI Array Processors; Prentice-Hall, Inc., 1988
- N. Petkov: Systolic Parallel Processing; North Holland Publishing Co, 1992
External links
- Instruction Systolic Array (ISA)
- 'A VLSI Architecture for Image Registration in Real Time' (Based on systolic array), Vol. 15, September 2007