Sufficient statistic

In statistics, a statistic is sufficient with respect to a statistical model and its associated unknown parameter if "no other statistic that can be calculated from the same sample provides any additional information as to the value of the parameter".[1] In particular, a statistic is sufficient for a family of probability distributions if the sample from which it is calculated gives no additional information than does the statistic, as to which of those probability distributions is that of the population from which the sample was taken.
Roughly, given a set  of independent identically distributed data conditioned on an unknown parameter
of independent identically distributed data conditioned on an unknown parameter  , a sufficient statistic is a function
, a sufficient statistic is a function 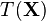 whose value contains all the information needed to compute any estimate of the parameter (e.g. a maximum likelihood estimate). Due to the factorization theorem (see below), for a sufficient statistic , the joint distribution can be written as
whose value contains all the information needed to compute any estimate of the parameter (e.g. a maximum likelihood estimate). Due to the factorization theorem (see below), for a sufficient statistic , the joint distribution can be written as 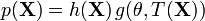 . From this factorization, it can easily be seen that the maximum likelihood estimate of will interact with only through . Typically, the sufficient statistic is a simple function of the data, e.g. the sum of all the data points.
. From this factorization, it can easily be seen that the maximum likelihood estimate of will interact with only through . Typically, the sufficient statistic is a simple function of the data, e.g. the sum of all the data points.
More generally, the "unknown parameter" may represent a vector of unknown quantities or may represent everything about the model that is unknown or not fully specified. In such a case, the sufficient statistic may be a set of functions, called a jointly sufficient statistic. Typically, there are as many functions as there are parameters. For example, for a Gaussian distribution with unknown mean and variance, the jointly sufficient statistic, from which maximum likelihood estimates of both parameters can be estimated, consists of two functions, the sum of all data points and the sum of all squared data points (or equivalently, the sample mean and sample variance).
The concept, due to Ronald Fisher, is equivalent to the statement that, conditional on the value of a sufficient statistic for a parameter, the joint probability distribution of the data does not depend on that parameter. Both the statistic and the underlying parameter can be vectors.
A related concept is that of linear sufficiency, which is weaker than sufficiency but can be applied in some cases where there is no sufficient statistic, although it is restricted to linear estimators.[2] The Kolmogorov structure function deals with individual finite data, the related notion there is the algorithmic sufficient statistic.
The concept of sufficiency has fallen out of favor in descriptive statistics because of the strong dependence on an assumption of the distributional form (see Pitman–Koopman–Darmois theorem below), but remains very important in theoretical work.[3]
Mathematical definition
A statistic T(X) is sufficient for underlying parameter θ precisely if the conditional probability distribution of the data X, given the statistic T(X), does not depend on the parameter θ,[4] i.e.
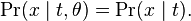
Instead of this expression, the definition still holds if one uses either of the equivalent expressions:
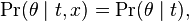 or
or
which indicate, respectively, that the conditional probability of the parameter θ, given the sufficient statistic t, does not depend on the data x; and that the conditional probability of the parameter θ given the sufficient statistic t and the conditional probability of the data x given the sufficient statistic t are statistically independent.
Example
As an example, the sample mean is sufficient for the mean (μ) of a normal distribution with known variance. Once the sample mean is known, no further information about μ can be obtained from the sample itself. On the other hand, for an arbitrary distribution the median is not sufficient for the mean: even if the median of the sample is known, knowing the sample itself would provide further information about the population mean. For example, if the observations that are less than the median are only slightly less, but observations exceeding the median exceed it by a large amount, then this would have a bearing on one's inference about the population mean.
Fisher–Neyman factorization theorem
Fisher's factorization theorem or factorization criterion provides a convenient characterization of a sufficient statistic. If the probability density function is ƒθ(x), then T is sufficient for θ if and only if nonnegative functions g and h can be found such that
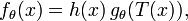
i.e. the density ƒ can be factored into a product such that one factor, h, does not depend on θ and the other factor, which does depend on θ, depends on x only through T(x).
It is easy to see that if F(t) is a one to one function and T is a sufficient statistic, then F(T) is a sufficient statistic. In particular we can multiply a sufficient statistic by a nonzero constant and get another sufficient statistic.
Likelihood principle interpretation
An implication of the theorem is that when using likelihood-based inference, two sets of data yielding the same value for the sufficient statistic T(X) will always yield the same inferences about θ. By the factorization criterion, the likelihood's dependence on θ is only in conjunction with T(X). As this is the same in both cases, the dependence on θ will be the same as well, leading to identical inferences.
Proof
Due to Hogg and Craig.[5] Let  , denote a random sample from a distribution having the pdf f(x, θ) for ι < θ < δ. Let Y1 = u1(X1, X2, ..., Xn) be a statistic whose pdf is g1(y1; θ). Then Y1 = u1(X1, X2, ..., Xn) is a sufficient statistic for θ if and only if, for some function H,
, denote a random sample from a distribution having the pdf f(x, θ) for ι < θ < δ. Let Y1 = u1(X1, X2, ..., Xn) be a statistic whose pdf is g1(y1; θ). Then Y1 = u1(X1, X2, ..., Xn) is a sufficient statistic for θ if and only if, for some function H,
![\prod_{i=1}^n f(x_i; \theta) = g_1 \left[u_1 (x_1, x_2, \dots, x_n); \theta \right] H(x_1, x_2, \dots, x_n). \,](../I/m/90c06ca975e3bd3fcafb21978e88200b.png)
First, suppose that
We shall make the transformation yi = ui(x1, x2, ..., xn), for i = 1, ..., n, having inverse functions xi = wi(y1, y2, ..., yn), for i = 1, ..., n, and Jacobian ![J = \left[w_i/y_j \right]](../I/m/cd42307186378220af841c013b5f97b5.png) . Thus,
. Thus,
![\prod_{i=1}^n f \left[ w_i(y_1, y_2, \dots, y_n); \theta \right] =
|J| g_1 (y_1; \theta) H \left[ w_1(y_1, y_2, \dots, y_n), \dots, w_n(y_1, y_2, \dots, y_n) \right].](../I/m/2116ed591cb116670daa09f8619a6001.png)
The left-hand member is the joint pdf g(y1, y2, ..., yn; θ) of Y1 = u1(X1, ..., Xn), ..., Yn = un(X1, ..., Xn). In the right-hand member, 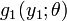 is the pdf of
is the pdf of 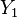 , so that
, so that ![H[ w_1, \dots , w_n] |J|](../I/m/af18e48fd2d23400d98876944e71b021.png) is the quotient of
is the quotient of 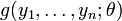 and ; that is, it is the conditional pdf
and ; that is, it is the conditional pdf 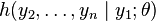 of
of 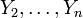 given
given  .
.
But  , and thus
, and thus ![H\left[w_1(y_1,\dots,y_n), \dots, w_n(y_1, \dots, y_n))\right]](../I/m/a217b2babcf4037991b19137df3e964f.png) , was given not to depend upon . Since was not introduced in the transformation and accordingly not in the Jacobian
, was given not to depend upon . Since was not introduced in the transformation and accordingly not in the Jacobian 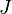 , it follows that does not depend upon and that is a sufficient statistics for .
, it follows that does not depend upon and that is a sufficient statistics for .
The converse is proven by taking:
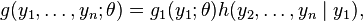
where 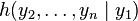 does not depend upon because
does not depend upon because 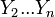 depend only upon
depend only upon 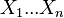 , which are independent on
, which are independent on 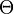 when conditioned by , a sufficient statistics by hypothesis. Now divide both members by the absolute value of the non-vanishing Jacobian , and replace
when conditioned by , a sufficient statistics by hypothesis. Now divide both members by the absolute value of the non-vanishing Jacobian , and replace 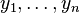 by the functions
by the functions 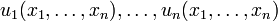 in
in  . This yields
. This yields
![\frac{g\left[ u_1(x_1, \dots, x_n), \dots, u_n(x_1, \dots, x_n); \theta \right]}{|J*|}=g_1\left[u_1(x_1,\dots,x_n); \theta\right] \frac{h(u_2, \dots, u_n \mid u_1)}{|J*|}](../I/m/32560de6e7290ed2227ce06294c225be.png)
where 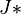 is the Jacobian with replaced by their value in terms . The left-hand member is necessarily the joint pdf
is the Jacobian with replaced by their value in terms . The left-hand member is necessarily the joint pdf  of
of  . Since , and thus
. Since , and thus 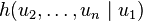 , does not depend upon , then
, does not depend upon , then
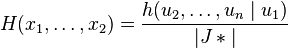
is a function that does not depend upon .
Another proof
A simpler more illustrative proof is as follows, although it applies only in the discrete case.
We use the shorthand notation to denote the joint probability of 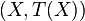 by
by  . Since
. Since  is a function of
is a function of 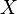 , we have
, we have 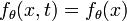 (only when
(only when 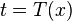 and zero otherwise) and thus:
and zero otherwise) and thus:
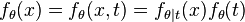
with the last equality being true by the definition of conditional probability distributions. Thus 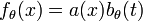 with
with  and
and  .
.
Reciprocally, if , we have

With the first equality by the definition of pdf for multiple variables, the second by the remark above, the third by hypothesis, and the fourth because the summation is not over  .
.
Thus, the conditional probability distribution is:
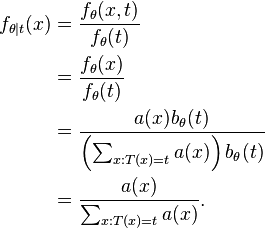
With the first equality by definition of conditional probability density, the second by the remark above, the third by the equality proven above, and the fourth by simplification. This expression does not depend on and thus is a sufficient statistic.[6]
Minimal sufficiency
A sufficient statistic is minimal sufficient if it can be represented as a function of any other sufficient statistic. In other words, S(X) is minimal sufficient if and only if[7]
- S(X) is sufficient, and
- if T(X) is sufficient, then there exists a function f such that S(X) = f(T(X)).
Intuitively, a minimal sufficient statistic most efficiently captures all possible information about the parameter θ.
A useful characterization of minimal sufficiency is that when the density fθ exists, S(X) is minimal sufficient if and only if
 is independent of θ :
is independent of θ :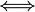 S(x) = S(y)
S(x) = S(y)
This follows as a direct consequence from Fisher's factorization theorem stated above.
A case in which there is no minimal sufficient statistic was shown by Bahadur, 1954.[8] However, under mild conditions, a minimal sufficient statistic does always exist. In particular, in Euclidean space, these conditions always hold if the random variables (associated with  ) are all discrete or are all continuous.
) are all discrete or are all continuous.
If there exists a minimal sufficient statistic, and this is usually the case, then every complete sufficient statistic is necessarily minimal sufficient[9](note that this statement does not exclude the option of a pathological case in which a complete sufficient exists while there is no minimal sufficient statistic). While it is hard to find cases in which a minimal sufficient statistic does not exist, it is not so hard to find cases in which there is no complete statistic.
The collection of likelihood ratios 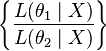 is a minimal sufficient statistic if
is a minimal sufficient statistic if 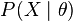 is discrete or has a density function.
is discrete or has a density function.
Examples
Bernoulli distribution
If X1, ...., Xn are independent Bernoulli-distributed random variables with expected value p, then the sum T(X) = X1 + ... + Xn is a sufficient statistic for p (here 'success' corresponds to Xi = 1 and 'failure' to Xi = 0; so T is the total number of successes)
This is seen by considering the joint probability distribution:
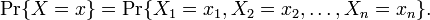
Because the observations are independent, this can be written as
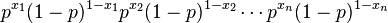
and, collecting powers of p and 1 − p, gives
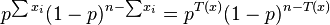
which satisfies the factorization criterion, with h(x) = 1 being just a constant.
Note the crucial feature: the unknown parameter p interacts with the data x only via the statistic T(x) = Σ xi.
As a concrete application, this gives a procedure for creating a fair coin from a biased coin.
Uniform distribution
If X1, ...., Xn are independent and uniformly distributed on the interval [0,θ], then T(X) = max(X1, ..., Xn) is sufficient for θ — the sample maximum is a sufficient statistic for the population maximum.
To see this, consider the joint probability density function of X=(X1,...,Xn). Because the observations are independent, the pdf can be written as a product of individual densities
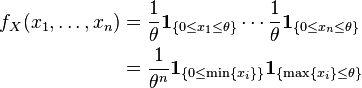
where 1{...} is the indicator function. Thus the density takes form required by the Fisher–Neyman factorization theorem, where h(x) = 1{min{xi}≥0}, and the rest of the expression is a function of only θ and T(x) = max{xi}.
In fact, the minimum-variance unbiased estimator (MVUE) for θ is

This is the sample maximum, scaled to correct for the bias, and is MVUE by the Lehmann–Scheffé theorem. Unscaled sample maximum T(X) is the maximum likelihood estimator for θ.
Uniform distribution (with two parameters)
If 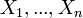 are independent and uniformly distributed on the interval
are independent and uniformly distributed on the interval ![[\alpha, \beta]\,](../I/m/8c6ce103bd2dced02e71009e5e83dbe4.png) (where
(where 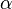 and
and  are unknown parameters), then
are unknown parameters), then 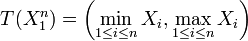 is a two-dimensional sufficient statistic for
is a two-dimensional sufficient statistic for 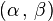 .
.
To see this, consider the joint probability density function of 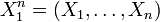 . Because the observations are independent, the pdf can be written as a product of individual densities, i.e.
. Because the observations are independent, the pdf can be written as a product of individual densities, i.e.
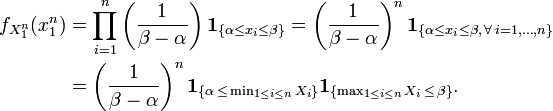
The joint density of the sample takes the form required by the Fisher–Neyman factorization theorem, by letting
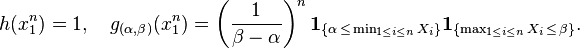
Since  does not depend on the parameter
does not depend on the parameter  and
and 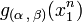 depends only on
depends only on 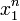 through the function
through the function 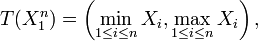
the Fisher–Neyman factorization theorem implies is a sufficient statistic for .
Poisson distribution
If X1, ...., Xn are independent and have a Poisson distribution with parameter λ, then the sum T(X) = X1 + ... + Xn is a sufficient statistic for λ.
To see this, consider the joint probability distribution:
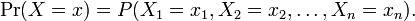
Because the observations are independent, this can be written as

which may be written as
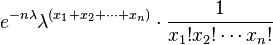
which shows that the factorization criterion is satisfied, where h(x) is the reciprocal of the product of the factorials. Note the parameter λ interacts with the data only through its sum T(X).
Normal distribution
If are independent and normally distributed with expected value θ (a parameter) and known finite variance 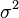 , then
, then  is a sufficient statistic for θ.
is a sufficient statistic for θ.
To see this, consider the joint probability density function of 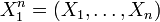 . Because the observations are independent, the pdf can be written as a product of individual densities, i.e. -
. Because the observations are independent, the pdf can be written as a product of individual densities, i.e. -
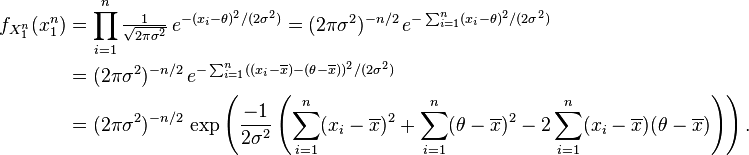
Then, since 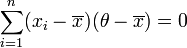 , which can be shown simply by expanding this term,
, which can be shown simply by expanding this term,

The joint density of the sample takes the form required by the Fisher–Neyman factorization theorem, by letting
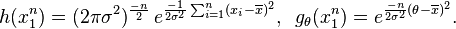
Since does not depend on the parameter and 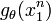 depends only on through the function
depends only on through the function 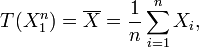
the Fisher–Neyman factorization theorem implies is a sufficient statistic for .
Exponential distribution
If are independent and exponentially distributed with expected value θ (an unknown real-valued positive parameter), then 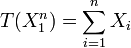 is a sufficient statistic for θ.
is a sufficient statistic for θ.
To see this, consider the joint probability density function of . Because the observations are independent, the pdf can be written as a product of individual densities, i.e. -
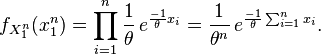
The joint density of the sample takes the form required by the Fisher–Neyman factorization theorem, by letting
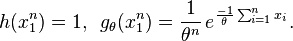
Since does not depend on the parameter and depends only on through the function
the Fisher–Neyman factorization theorem implies is a sufficient statistic for .
Gamma distribution
If 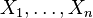 are independent and distributed as a
are independent and distributed as a 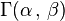 , where and are unknown parameters of a Gamma distribution, then
, where and are unknown parameters of a Gamma distribution, then  is a two-dimensional sufficient statistic for .
is a two-dimensional sufficient statistic for .
To see this, consider the joint probability density function of . Because the observations are independent, the pdf can be written as a product of individual densities, i.e. -
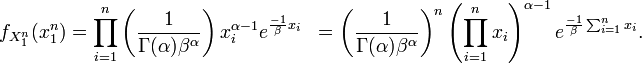
The joint density of the sample takes the form required by the Fisher–Neyman factorization theorem, by letting
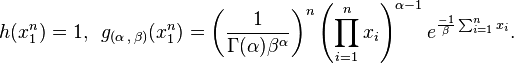
Since does not depend on the parameter and depends only on through the function 
the Fisher–Neyman factorization theorem implies 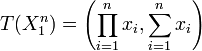 is a sufficient statistic for
is a sufficient statistic for 
Rao–Blackwell theorem
Sufficiency finds a useful application in the Rao–Blackwell theorem, which states that if g(X) is any kind of estimator of θ, then typically the conditional expectation of g(X) given sufficient statistic T(X) is a better estimator of θ, and is never worse. Sometimes one can very easily construct a very crude estimator g(X), and then evaluate that conditional expected value to get an estimator that is in various senses optimal.
Exponential family
According to the Pitman–Koopman–Darmois theorem, among families of probability distributions whose domain does not vary with the parameter being estimated, only in exponential families is there a sufficient statistic whose dimension remains bounded as sample size increases. Less tersely, suppose 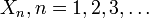 are independent identically distributed random variables whose distribution is known to be in some family of probability distributions. Only if that family is an exponential family is there a (possibly vector-valued) sufficient statistic
are independent identically distributed random variables whose distribution is known to be in some family of probability distributions. Only if that family is an exponential family is there a (possibly vector-valued) sufficient statistic 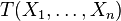 whose number of scalar components does not increase as the sample size n increases.
whose number of scalar components does not increase as the sample size n increases.
This theorem shows that sufficiency (or rather, the existence of a scalar or vector-valued of bounded dimension sufficient statistic) sharply restricts the possible forms of the distribution.
Other types of sufficiency
Bayesian sufficiency
An alternative formulation of the condition that a statistic be sufficient, set in a Bayesian context, involves the posterior distributions obtained by using the full data-set and by using only a statistic. Thus the requirement is that, for almost every x,
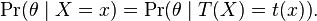
It turns out that this "Bayesian sufficiency" is a consequence of the formulation above,[10] however they are not directly equivalent in the infinite-dimensional case.[11] A range of theoretical results for sufficiency in a Bayesian context is available.[12]
Linear sufficiency
A concept called "linear sufficiency" can be formulated in a Bayesian context,[13] and more generally.[14] First define the best linear predictor of a vector Y based on X as ![\hat E[Y|X]](../I/m/4cb27a710a61f3784f06f2780fec7ed1.png) . Then a linear statistic T(x) is linear sufficient[15] if
. Then a linear statistic T(x) is linear sufficient[15] if
![\hat E[\theta\mid X]= \hat E[\theta\mid T(X)] .](../I/m/de4afe7a9c8750ba533474d7c60e6f78.png)
See also
- Completeness of a statistic
- Basu's theorem on independence of complete sufficient and ancillary statistics
- Lehmann–Scheffé theorem: a complete sufficient estimator is the best estimator of its expectation
- Rao–Blackwell theorem
- Sufficient dimension reduction
- Ancillary statistic
Notes
- ↑ Fisher, R.A. (1922). "On the mathematical foundations of theoretical statistics". Philosophical Transactions of the Royal Society A 222: 309–368. doi:10.1098/rsta.1922.0009. JFM 48.1280.02. JSTOR 91208.
- ↑ Dodge, Y. (2003) — entry for linear sufficiency
- ↑ Stigler, Stephen (December 1973). "Studies in the History of Probability and Statistics. XXXII: Laplace, Fisher and the Discovery of the Concept of Sufficiency". Biometrika 60 (3): 439–445. doi:10.1093/biomet/60.3.439. JSTOR 2334992. MR 0326872.
- ↑ Casella, George; Berger, Roger L. (2002). Statistical Inference, 2nd ed. Duxbury Press.
- ↑ Hogg, Robert V.; Craig, Allen T. (1995). Introduction to Mathematical Statistics. Prentice Hall. ISBN 978-0-02-355722-4.
- ↑ "The Fisher–Neyman Factorization Theorem".. Webpage at Connexions (cnx.org)
- ↑ Dodge (2003) — entry for minimal sufficient statistics
- ↑ Lehmann and Casella (1998), Theory of Point Estimation, 2nd Edition, Springer, p 37
- ↑ Lehmann and Casella (1998), Theory of Point Estimation, 2nd Edition, Springer, page 42
- ↑ Bernardo, J.M.; Smith, A.F.M. (1994). "Section 5.1.4". Bayesian Theory. Wiley. ISBN 0-471-92416-4.
- ↑ Blackwell, D.; Ramamoorthi, R. V. (1982). "A Bayes but not classically sufficient statistic.". Annals of Statistics 10 (3): 1025–1026. doi:10.1214/aos/1176345895. MR 663456. Zbl 0485.62004.
- ↑ Nogales, A.G.; Oyola, J.A.; Perez, P. (2000). "On conditional independence and the relationship between sufficiency and invariance under the Bayesian point of view". Statistics & Probability Letters 46 (1): 75–84. doi:10.1016/S0167-7152(99)00089-9. MR 1731351. Zbl 0964.62003.
- ↑ Goldstein, M.; O'Hagan, A. (1996). "Bayes Linear Sufficiency and Systems of Expert Posterior Assessments". Journal of the Royal Statistical Society. Series B 58 (2): 301–316. JSTOR 2345978.
- ↑ Godambe, V. P. (1966). "A New Approach to Sampling from Finite Populations. II Distribution-Free Sufficiency". Journal of the Royal Statistical Society. Series B 28 (2): 320–328. JSTOR 2984375.
- ↑ Witting, T. (1987). "The linear Markov property in credibility theory". ASTIN Bulletin 17 (1): 71–84. doi:10.2143/ast.17.1.2014984.
References
- Kholevo, A.S. (2001), "Sufficient statistic", in Hazewinkel, Michiel, Encyclopedia of Mathematics, Springer, ISBN 978-1-55608-010-4
- Lehmann, E. L.; Casella, G. (1998). Theory of Point Estimation (2nd ed.). Springer. Chapter 4. ISBN 0-387-98502-6.
- Dodge, Y. (2003) The Oxford Dictionary of Statistical Terms, OUP. ISBN 0-19-920613-9
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||