t-statistic
In statistics, the t-statistic is a ratio of the departure of an estimated parameter from its notional value and its standard error. It is used in hypothesis testing, for example in the Student’s t-test, in the augmented Dickey–Fuller test, and in bootstrapping.
Definition
Let 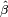 be an estimator of parameter β in some statistical model. Then a t-statistic for this parameter is any quantity of the form
be an estimator of parameter β in some statistical model. Then a t-statistic for this parameter is any quantity of the form
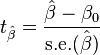
where β0 is a non-random, known constant, and 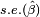 is the standard error of the estimator . By default, statistical packages report t-statistic with β0 = 0 (these t-statistics are used to test the significance of corresponding regressor). However, when t-statistic is needed to test the hypothesis of the form H0: β = β0, then a non-zero β0 may be used.
is the standard error of the estimator . By default, statistical packages report t-statistic with β0 = 0 (these t-statistics are used to test the significance of corresponding regressor). However, when t-statistic is needed to test the hypothesis of the form H0: β = β0, then a non-zero β0 may be used.
If is an ordinary least squares estimator in the classical linear regression model (that is, with normally distributed and homoskedastic error terms), and if the true value of parameter β is equal to β0, then the sampling distribution of the t-statistic is the Student's t-distribution with (n − k) degrees of freedom, where n is the number of observations, and k is the number of regressors (including the intercept).
In the majority of models the estimator is consistent for β and distributed asymptotically normally. If the true value of parameter β is equal to β0 and the quantity correctly estimates the asymptotic variance of this estimator, then the t-statistic will have asymptotically the standard normal distribution.
In some models the distribution of t-statistic is different from normal, even asymptotically. For example, when a time series with unit root is regressed in the augmented Dickey–Fuller test, the test t-statistic will asymptotically have one of the Dickey–Fuller distributions (depending on the test setting).
Use
Most frequently, t statistics are used in Student's t-tests, a form of statistical hypothesis testing, and in the computation of certain confidence intervals.
The key property of the t statistic is that it is a pivotal quantity – while defined in terms of the sample mean, its sampling distribution does not depend on the sample parameters, and thus it can be used regardless of what these may be.
One can also divide a residual by the sample standard deviation:
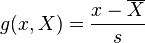
to compute an estimate for the number of standard deviations a given sample is from the mean, as a sample version of a z-score, the z-score requiring the population parameters.
Prediction
Given a normal distribution 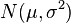 with unknown mean and variance, the t-statistic of a future observation
with unknown mean and variance, the t-statistic of a future observation  after one has made n observations, is an ancillary statistic – a pivotal quantity (does not depend on the values of μ and σ2) that is a statistic (computed from observations). This allows one to compute a frequentist prediction interval (a predictive confidence interval), via the following t-distribution:
after one has made n observations, is an ancillary statistic – a pivotal quantity (does not depend on the values of μ and σ2) that is a statistic (computed from observations). This allows one to compute a frequentist prediction interval (a predictive confidence interval), via the following t-distribution:
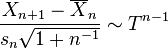
Solving for  yields the prediction distribution
yields the prediction distribution
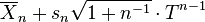
from which one may compute predictive confidence intervals – given a probability p, one may compute intervals such that 100p% of the time, the next observation will fall in that interval.
History
The term "t-statistic" is abbreviated from "hypothesis test statistic", while "Student" was the pen name of William Sealy Gosset, who introduced the t-statistic and t-test in 1908, while working for the Guinness brewery in Dublin, Ireland.
Related concepts
- z-score (standardization): If the population parameters are known, then rather than computing the t-statistic, one can compute the z-score; analogously, rather than using a t-test, one uses a z-test. This is rare outside of standardized testing.
- Studentized residual: In regression analysis, the standard errors of the estimators at different data points vary (compare the middle versus endpoints of a simple linear regression), and thus one must divide the different residuals by different estimates for the error, yielding what are called studentized residuals.