Memory hierarchy
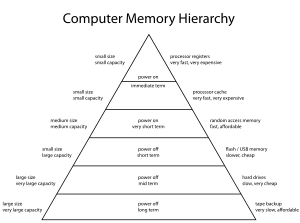
The term memory hierarchy is used in computer architecture when discussing performance issues in computer architectural design, algorithm predictions, and the lower level programming constructs such as involving locality of reference. A "memory hierarchy" in computer storage distinguishes each level in the "hierarchy" by response time. Since response time, complexity, and capacity are related,[1] the levels may also be distinguished by the controlling technology.
The many trade-offs in designing for high performance will include the structure of the memory hierarchy, i.e. the size and technology of each component. So the various components can be viewed as forming a hierarchy of memories (m1,m2,...,mn) in which each member mi is in a sense subordinate to the next highest member mi+1 of the hierarchy. To limit waiting by higher levels, a lower level will respond by filling a buffer and then signaling to activate the transfer.
There are four major storage levels.[1]
- Internal – Processor registers and cache.
- Main – the system RAM and controller cards.
- On-line mass storage – Secondary storage.
- Off-line bulk storage – Tertiary and Off-line storage.
This is a general memory hierarchy structuring. Many other structures are useful. For example, a paging algorithm may be considered as a level for virtual memory when designing a computer architecture, and one can include a level of nearline storage between online and offline storage.
Example use of the term
Here are some quotes.
- Adding complexity slows down the memory hierarchy.[2]
- CMOx memory technology stretches the Flash space in the memory hierarchy[3]
- One of the main ways to increase system performance is minimising how far down the memory hierarchy one has to go to manipulate data.[4]
- Latency and bandwidth are two metrics associated with caches and memory. Neither of them is uniform, but is specific to a particular component of the memory hierarchy.[5]
- Predicting where in the memory hierarchy the data resides is difficult.[5]
- ...the location in the memory hierarchy dictates the time required for the prefetch to occur.[5]
Application of the concept

The number of levels in the memory hierarchy and the performance at each level has increased over time. For example, the memory hierarchy of an Intel Haswell Mobile [6] processor circa 2013 is:
- Processor registers – the fastest possible access (usually 1 CPU cycle). A few thousand bytes in size
- Cache
- Level 0 (L0) Micro operations cache – 6 KiB [7] in size
- Level 1 (L1) Instruction cache – 128 KiB in size
- Level 1 (L1) Data cache – 128 KiB in size. Best access speed is around 700 GiB/second[8]
- Level 2 (L2) Instruction and data (shared) – 1 MiB in size. Best access speed is around 200 GiB/second[8]
- Level 3 (L3) Shared cache – 6 MiB in size. Best access speed is around 100 GB/second[8]
- Level 4 (L4) Shared cache – 128 MiB in size. Best access speed is around 40 GB/second[8]
- Main memory (Primary storage) – Gigabytes in size. Best access speed is around 10 GB/second.[8] In the case of a NUMA machine, access times may not be uniform
- Disk storage (Secondary storage) – Terabytes in size. As of 2013, best access speed is from a solid state drive is about 600 MB/second [9]
- Nearline storage (Tertiary storage) – Up to exabytes in size. As of 2013, best access speed is about 160 MB/second[10]
- Offline storage
The lower levels of the hierarchy – from disks downwards – are also known as tiered storage. The formal distinction between online, nearline, and offline storage is:[11]
- Online storage is immediately available for I/O.
- Nearline storage is not immediately available, but can be made online quickly without human intervention.
- Offline storage is not immediately available, and requires some human intervention to bring online.
For example, always-on spinning disks are online, while spinning disks that spin-down, such as massive array of idle disk (MAID), are nearline. Removable media such as tape cartridges that can be automatically loaded, as in a tape library, are nearline, while cartridges that must be manually loaded are offline.
Most modern CPUs are so fast that for most program workloads, the bottleneck is the locality of reference of memory accesses and the efficiency of the caching and memory transfer between different levels of the hierarchy. As a result, the CPU spends much of its time idling, waiting for memory I/O to complete. This is sometimes called the space cost, as a larger memory object is more likely to overflow a small/fast level and require use of a larger/slower level. The resulting load on memory use is known as pressure (respectively register pressure, cache pressure, and (main) memory pressure). Terms for data being missing from a higher level and needing to be fetched from a lower level are, respectively: register spilling (due to register pressure: register to cache), cache miss (cache to main memory), and (hard) page fault (main memory to disk).
Modern programming languages mainly assume two levels of memory, main memory and disk storage, though in assembly language and inline assemblers in languages such as C, registers can be directly accessed. Taking optimal advantage of the memory hierarchy requires the cooperation of programmers, hardware, and compilers (as well as underlying support from the operating system):
- Programmers are responsible for moving data between disk and memory through file I/O.
- Hardware is responsible for moving data between memory and caches.
- Optimizing compilers are responsible for generating code that, when executed, will cause the hardware to use caches and registers efficiently.
Many programmers assume one level of memory. This works fine until the application hits a performance wall. Then the memory hierarchy will be assessed during code refactoring.
See also
- Cloud storage
- Memory wall
- Use of spatial and temporal locality: hierarchical memory
- The difference between buffer and cache
- Random-access memory#Memory hierarchy
- Cache hierarchy in a modern processor
- Computer data storage
- Computer memory
- Tiered storage
References
- 1 2 Toy, Wing; Zee, Benjamin (1986). Computer Hardware/Software Architecture. Prentice Hall. p. 30. ISBN 0-13-163502-6.
- ↑ Write-combining
- ↑ "Memory Hierarchy". Unitity Semiconductor Corporation. Retrieved 16 September 2009.
- ↑ Pádraig Brady. "Multi-Core". Retrieved 16 September 2009.
- 1 2 3 van der Pas, Ruud (2002). Santa Clara, California: Sun Microsystems: 26. 817-0742-10 http://www.sun.com/. Missing or empty
|title=(help);|contribution=ignored (help) - ↑ Crothers, Brooke. "Dissecting Intel's top graphics in Apple's 15-inch MacBook Pro - CNET". News.cnet.com. Retrieved 2014-07-31.
- ↑ "Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel". AnandTech. Retrieved 2014-07-31.
- 1 2 3 4 5 "SiSoftware Zone". Sisoftware.co.uk. Retrieved 2014-07-31.
- ↑ "Charts, benchmarks SSD Charts 2013, AS-SSD Sequential Read". Tomshardware.com. Retrieved 2014-07-31.
- ↑ "Ultrium - LTO Technology - Ultrium GenerationsLTO". Lto.org. Retrieved 2014-07-31.
- ↑ Pearson, Tony (2010). "Correct use of the term Nearline.". IBM Developerworks, Inside System Storage. Retrieved 2015-08-16.