Stein's example
Stein's example (or phenomenon or paradox), in decision theory and estimation theory, is the phenomenon that when three or more parameters are estimated simultaneously, there exist combined estimators more accurate on average (that is, having lower expected mean squared error) than any method that handles the parameters separately. It is named after Charles Stein of Stanford University, who discovered the phenomenon in 1955.[1]
An intuitive explanation is that optimizing for the mean-squared error of a combined estimator is not the same as optimizing for the errors of separate estimators of the individual parameters. In practical terms, if the combined error is in fact of interest, then a combined estimator should be used, even if the underlying parameters are independent; this occurs in channel estimation in telecommunications, for instance (different factors affect overall channel performance). On the other hand, if one is instead interested in estimating an individual parameter, then using a combined estimator does not help and is in fact worse.
Formal statement
The following is perhaps the simplest form of the paradox, the special case in which the number of observations is equal to (rather than greater than) the number of parameters to be estimated. Let θ be a vector consisting of n ≥ 3 unknown parameters. To estimate these parameters, a single measurement Xi is performed for each parameter θi, resulting in a vector X of length n. Suppose the measurements are independent, Gaussian random variables, with mean θ and variance 1, i.e.,

Thus, each parameter is estimated using a single noisy measurement, and each measurement is equally inaccurate.
Under such conditions, it is most intuitive (and most common) to use each measurement as an estimate of its corresponding parameter. This so-called "ordinary" decision rule can be written as

The quality of such an estimator is measured by its risk function. A commonly used risk function is the mean squared error, defined as
![\operatorname{E} \left[ \| {\boldsymbol \theta} - \hat {\boldsymbol \theta} \|^2 \right].](../I/m/b07ef32c758dd1146e9db6a75743d21b.png)
Surprisingly, it turns out that the "ordinary" estimator proposed above is suboptimal in terms of mean squared error when n ≥ 3. In other words, in the setting discussed here, there exist alternative estimators which always achieve lower mean squared error, no matter what the value of  is.
is.
For a given θ one could obviously define a perfect "estimator" which is always just θ, but this estimator would be bad for other values of θ. The estimators of Stein's paradox are, for a given θ, better than X for some values of X but necessarily worse for others (except perhaps for one particular θ vector, for which the new estimate is always better than X). It is only on average that they are better.
More accurately, an estimator 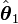 is said to dominate another estimator
is said to dominate another estimator  if, for all values of , the risk of is lower than, or equal to, the risk of , and if the inequality is strict for some . An estimator is said to be admissible if no other estimator dominates it, otherwise it is inadmissible. Thus, Stein's example can be simply stated as follows: The ordinary decision rule for estimating the mean of a multivariate Gaussian distribution is inadmissible under mean squared error risk.
if, for all values of , the risk of is lower than, or equal to, the risk of , and if the inequality is strict for some . An estimator is said to be admissible if no other estimator dominates it, otherwise it is inadmissible. Thus, Stein's example can be simply stated as follows: The ordinary decision rule for estimating the mean of a multivariate Gaussian distribution is inadmissible under mean squared error risk.
Many simple, practical estimators achieve better performance than the ordinary estimator. The best-known example is the James–Stein estimator, which works by starting at X and moving towards a particular point (such as the origin) by an amount inversely proportional to the distance of X from that point.
For a sketch of the proof of this result, see Proof of Stein's example.
Implications
Stein's example is surprising, since the "ordinary" decision rule is intuitive and commonly used. In fact, numerous methods for estimator construction, including maximum likelihood estimation, best linear unbiased estimation, least squares estimation and optimal equivariant estimation, all result in the "ordinary" estimator. Yet, as discussed above, this estimator is suboptimal.
To demonstrate the unintuitive nature of Stein's example, consider the following real-world example. Suppose we are to estimate three unrelated parameters, such as the US wheat yield for 1993, the number of spectators at the Wimbledon tennis tournament in 2001, and the weight of a randomly chosen candy bar from the supermarket. Suppose we have independent Gaussian measurements of each of these quantities. Stein's example now tells us that we can get a better estimate (on average) for the vector of three parameters by simultaneously using the three unrelated measurements.
At first sight it appears that somehow we get a better estimator for US wheat yield by measuring some other unrelated statistics such as the number of spectators at Wimbledon and the weight of a candy bar. This is of course absurd; we have not obtained a better estimator for US wheat yield by itself, but we have produced an estimator for the vector of the means of all three random variables, which has a reduced total risk. This occurs because the cost of a bad estimate in one component of the vector is compensated by a better estimate in another component. Also, a specific set of the three estimated mean values obtained with the new estimator will not necessarily be better than the ordinary set (the measured values). It is only on average that the new estimator is better.
An intuitive explanation
For any particular value of θ the new estimator will improve at least one of the individual mean square errors ![\operatorname{E} \left[ ( {\theta_i} - {\hat \theta_i})^2 \right].](../I/m/31ee8427af33a4c916c01266902cc34e.png) This is not hard − for instance, if
This is not hard − for instance, if 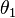 is between −1 and 1, and σ = 1, then an estimator that moves
is between −1 and 1, and σ = 1, then an estimator that moves  towards 0 by 0.5 (or sets it to zero if its absolute value was less than 0.5) will have a lower mean square error than itself. But there are other values of for which this estimator is worse than itself. The trick of the Stein estimator, and others that yield the Stein paradox, is that they adjust the shift in such a way that there is always (for any θ vector) at least one
towards 0 by 0.5 (or sets it to zero if its absolute value was less than 0.5) will have a lower mean square error than itself. But there are other values of for which this estimator is worse than itself. The trick of the Stein estimator, and others that yield the Stein paradox, is that they adjust the shift in such a way that there is always (for any θ vector) at least one 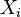 whose mean square error is improved, and its improvement more than compensates for any degradation in mean square error that might occur for another
whose mean square error is improved, and its improvement more than compensates for any degradation in mean square error that might occur for another  . The trouble is that, without knowing θ, you don't know which of the n mean square errors are improved, so you can't use the Stein estimator only for those parameters.
. The trouble is that, without knowing θ, you don't know which of the n mean square errors are improved, so you can't use the Stein estimator only for those parameters.
See also
Notes
References
- Efron, B.; Morris, C. (1977), "Stein's paradox in statistics" (PDF), Scientific American 236 (5): 119–127, doi:10.1038/scientificamerican0577-119
- Lehmann, E. L.; Casella, G. (1998), "ch.5", Theory of Point Estimation (2nd ed.), ISBN 0-471-05849-1
- Stein, C. (1956). "Inadmissibility of the usual estimator for the mean of a multivariate distribution". Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability. pp. 197–206. MR 0084922.