Tolerance interval
A tolerance interval is a statistical interval within which, with some confidence level, a specified proportion of a sampled population falls. "More specifically, a 100×p%/100×(1−α) tolerance interval provides limits within which at least a certain proportion (p) of the population falls with a given level of confidence (1−α)."[1] "A (p, 1−α) tolerance interval (TI) based on a sample is constructed so that it would include at least a proportion p of the sampled population with confidence 1−α; such a TI is usually referred to as p-content − (1−α) coverage TI."[2] "A (p, 1−α) upper tolerance limit (TL) is simply an 1−α upper confidence limit for the 100 p percentile of the population."[2]
A tolerance interval can be seen as a statistical version of a probability interval. "In the parameters-known case, a 95% tolerance interval and a 95% prediction interval are the same."[3] If we knew a population's exact parameters, we would be able to compute a range within which a certain proportion of the population falls. For example, if we know a population is normally distributed with mean 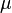 and standard deviation
and standard deviation 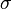 , then the interval
, then the interval 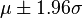 includes 95% of the population (1.96 is the z-score for 95% coverage of a normally distributed population).
includes 95% of the population (1.96 is the z-score for 95% coverage of a normally distributed population).
However, if we have only a sample from the population, we know only the sample mean  and sample standard deviation
and sample standard deviation 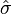 , which are only estimates of the true parameters. In that case,
, which are only estimates of the true parameters. In that case, 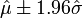 will not necessarily include 95% of the population, due to variance in these estimates. A tolerance interval bounds this variance by introducing a confidence level
will not necessarily include 95% of the population, due to variance in these estimates. A tolerance interval bounds this variance by introducing a confidence level 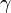 , which is the confidence with which this interval actually includes the specified proportion of the population. For a normally distributed population, a z-score can be transformed into a "k factor" or tolerance factor[4] for a given via lookup tables or several approximation formulas.[5] "As the degrees of freedom approach infinity, the prediction and tolerance intervals become equal."[6]
, which is the confidence with which this interval actually includes the specified proportion of the population. For a normally distributed population, a z-score can be transformed into a "k factor" or tolerance factor[4] for a given via lookup tables or several approximation formulas.[5] "As the degrees of freedom approach infinity, the prediction and tolerance intervals become equal."[6]
Relation to other intervals
The tolerance interval is less widely known than the confidence interval and prediction interval, a situation some educators have lamented, as it can lead to misuse of the other intervals where a tolerance interval is more appropriate.[7][8]
The tolerance interval differs from a confidence interval in that the confidence interval bounds a single-valued population parameter (the mean or the variance, for example) with some confidence, while the tolerance interval bounds the range of data values that includes a specific proportion of the population. Whereas a confidence interval's size is entirely due to sampling error, and will approach a zero-width interval at the true population parameter as sample size increases, a tolerance interval's size is due partly to sampling error and partly to actual variance in the population, and will approach the population's probability interval as sample size increases.[7][8]
The tolerance interval is related to a prediction interval in that both put bounds on variation in future samples. The prediction interval only bounds a single future sample, however, whereas a tolerance interval bounds the entire population (equivalently, an arbitrary sequence of future samples). In other words, a prediction interval covers a specified proportion of a population on average, whereas a tolerance interval covers it with a certain confidence level, making the tolerance interval more appropriate if a single interval is intended to bound multiple future samples.[8][9]
Examples
[7] gives the following example:
So consider once again a proverbial EPA mileage test scenario, in which several nominally identical autos of a particular model are tested to produce mileage figures. If such data are processed to produce a 95% confidence interval for the mean mileage of the model, it is, for example, possible to use it to project the mean or total gasoline consumption for the manufactured fleet of such autos over their first 5,000 miles of use. Such an interval, would however, not be of much help to a person renting one of these cars and wondering whether the (full) 10-gallon tank of gas will suffice to carry him the 350 miles to his destination. For that job, a prediction interval would be much more useful. (Consider the differing implications of being "95% sure" that
as opposed to being "95% sure" that
.) But neither a confidence interval for
of mileages of such autos.
Another example is given by:[9]
The air lead levels were collected fromdifferent areas within the facility. It was noted that the log-transformed lead levels fitted a normal distribution well (that is, the data are from a lognormal distribution). Let
, respectively, denote the population mean and variance for the log-transformed data. If
denotes the corresponding random variable, we thus have
. We note that exp(mu) is the median air lead level. A confidence interval for mu can be constructed the usual way, based on the t-distribution; this in turn will provide a confidence interval for the median air lead level. If
and S denote the sample mean and standard deviation of the log-transformed data for a sample of size n, a 95% confidence interval for mu is given by
, where
denotes the 1-alpha quantile of a t-distribution with m degrees of freedom. It may also be of interest to derive a 95% upper confidence bound for the median air lead level. Such a bound for mu is given by
. Consequently, a 95% upper confidence bound for the median air lead is given by
. Now suppose we want to predict the air lead level at a particular area within the laboratory. A 95% upper prediction limit for the log-transformed lead level is given by
. A two-sided prediction interval can be similarly computed. The meaning and interpretation of these intervals are well known. For example, if the confidence interval
is computed repeatedly from independent samples, 95% of the intervals so computed will include the true value of
See also
References
- ↑ D. S. Young (2010), Book Reviews: "Statistical Tolerance Regions: Theory, Applications, and Computation", TECHNOMETRICS, FEBRUARY 2010, VOL. 52, NO. 1, pp.143-144.
- 1 2 Krishnamoorthy, K. and Lian, Xiaodong(2011) 'Closed-form approximate tolerance intervals for some general linear models and comparison studies', Journal of Statistical Computation and Simulation,, First published on: 13 June 2011 doi:10.1080/00949655.2010.545061
- ↑ Thomas P. Ryan (22 June 2007). Modern Engineering Statistics. John Wiley & Sons. pp. 222–. ISBN 978-0-470-12843-5. Retrieved 22 February 2013.
- ↑ "Statistical interpretation of data — Part 6: Determination of statistical tolerance intervals". ISO 16269-6. 2005. p. 64.
- ↑ "Tolerance intervals for a normal distribution". Engineering Statistics Handbook. NIST/Sematech. 2010. Retrieved 2011-08-26.
- ↑ De Gryze, S.; Langhans, I.; Vandebroek, M. (2007). "Using the correct intervals for prediction: A tutorial on tolerance intervals for ordinary least-squares regression". Chemometrics and Intelligent Laboratory Systems 87 (2): 147. doi:10.1016/j.chemolab.2007.03.002.
- 1 2 3 Stephen B. Vardeman (1992). "What about the Other Intervals?". The American Statistician 46 (3): 193–197. doi:10.2307/2685212. JSTOR 2685212.
- 1 2 3 Mark J. Nelson (2011-08-14). "You might want a tolerance interval". Retrieved 2011-08-26.
- 1 2 K. Krishnamoorthy (2009). Statistical Tolerance Regions: Theory, Applications, and Computation. John Wiley and Sons. pp. 1–6. ISBN 0-470-38026-8.
Further reading
- K. Krishnamoorthy (2009). Statistical Tolerance Regions: Theory, Applications, and Computation. John Wiley and Sons. ISBN 0-470-38026-8.; Chap. 1, "Preliminaries", is available at http://media.wiley.com/product_data/excerpt/68/04703802/0470380268.pdf
- Derek S. Young (August 2010). "tolerance: An R Package for Estimating Tolerance Intervals". Journal of Statistical Software 36 (5): 1–39. ISSN 1548-7660. Retrieved 19 February 2013.
- ISO 16269-6, Statistical interpretation of data, Part 6: Determination of statistical tolerance intervals, Technical Committee ISO/TC 69, Applications of statistical methods. Available at http://standardsproposals.bsigroup.com/home/getpdf/458