Statistical model
A statistical model embodies a set of assumptions concerning the generation of the observed data, and similar data from a larger population. A model represents, often in considerably idealized form, the data-generating process. The model assumptions describe a set of probability distributions, some of which are assumed to adequately approximate the distribution from which a particular data set is sampled.
A model is usually specified by mathematical equations that relate one or more random variables and possibly other non-random variables. As such, "a model is a formal representation of a theory" (Herman Adèr quoting Kenneth Bollen).[1]
All statistical hypothesis tests and all statistical estimators are derived from statistical models. More generally, statistical models are part of the foundation of statistical inference.
Formal definition
In mathematical terms, a statistical model is usually thought of as a pair (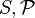 ), where
), where 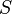 is the set of possible observations, i.e. the sample space, and
is the set of possible observations, i.e. the sample space, and 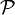 is a set of probability distributions on .[2]
is a set of probability distributions on .[2]
The intuition behind this definition is as follows. It is assumed that there is a "true" probability distribution that generates the observed data. We choose to represent a set (of distributions) which contains a distribution that adequately approximates the true distribution. Note that we do not require that contains the true distribution, and in practice that is rarely the case. Indeed, as Burnham & Anderson state, "A model is a simplification or approximation of reality and hence will not reflect all of reality"[3]—whence the saying "all models are wrong".
The set is almost always parameterized: 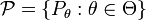 . The set
. The set 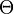 defines the parameters of the model. A parameterization is generally required to have distinct parameter values give rise to distinct distributions, i.e.,
defines the parameters of the model. A parameterization is generally required to have distinct parameter values give rise to distinct distributions, i.e., 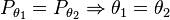 must hold (resembling injections). A parameterization that meets the condition is said to be identifiable.[2]
must hold (resembling injections). A parameterization that meets the condition is said to be identifiable.[2]
An example
Height and age are each probabilistically distributed over humans. They are stochastically related: when we know that a person is of age 10, this influences the chance of the person being 6 feet tall. We could formalize that relationship in a linear regression model with the following form: heighti = b0 + b1agei + εi, where b0 is the intercept, b1 is a parameter that age is multiplied by to get a prediction of height, ε is the error term, and i identifies the person. This implies that height is predicted by age, with some error.
An admissible model must be consistent with all the data points. Thus, the straight line (heighti = b0 + b1agei) is not a model of the data. The line cannot be a model, unless it exactly fits all the data points—i.e. all the data points lie perfectly on a straight line. The error term, εi, must be included in the model, so that the model is consistent with all the data points.
To do statistical inference, we would first need to assume some probability distributions for the εi. For instance, we might assume that the εi distributions are i.i.d. Gaussian, with zero mean. In this instance, the model would have 3 parameters: b0, b1, and the variance of the Gaussian distribution.
We can formally specify the model in the form () as follows. The sample space, , of our model comprises the set of all possible pairs (age, height). Each possible value of  = (b0, b1, σ2) determines a distribution on ; denote that distribution by
= (b0, b1, σ2) determines a distribution on ; denote that distribution by  . If is the set of all possible values of , then . (The parameterization is identifiable, and this is easy to check.)
. If is the set of all possible values of , then . (The parameterization is identifiable, and this is easy to check.)
In this example, the model is determined by (1) specifying and (2) making some assumptions relevant to . There are two assumptions: that height can be approximated by a linear function of age; that errors in the approximation are distributed as i.i.d. Gaussian. The assumptions are sufficient to specify —as they are required to do.
General remarks
A statistical model is a special type of mathematical model. What distinguishes a statistical model from other mathematical models is that a statistical model is non-deterministic. Thus, in a statistical model specified via mathematical equations, some of the variables do not have specific values, but instead have probability distributions; i.e. some of the variables are stochastic. In the example above, ε is a stochastic variable; without that variable, the model would be deterministic.
Statistical models are often used even when the physical process being modeled is deterministic. For instance, coin tossing is, in principle, a deterministic process; yet it is commonly modeled as stochastic (via a Bernoulli process).
There are three purposes for a statistical model, according to Konishi & Kitagawa.[4]
- Predictions
- Extraction of information
- Description of stochastic structures
Dimension of a model
Suppose that we have a statistical model () with . The model is said to be parametric if has a finite dimension. In notation, we write that 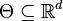 where d is a positive integer (
where d is a positive integer (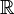 denotes the real numbers; other sets can be used, in principle). Here, d is called the dimension of the model.
denotes the real numbers; other sets can be used, in principle). Here, d is called the dimension of the model.
As an example, if we assume that data arise from a univariate Gaussian distribution, then we are assuming that
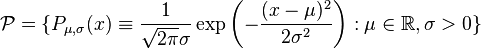 .
.
In this example, the dimension, d, equals 2.
As another example, suppose that the data consists of points (x, y) that we assume are distributed according to a straight line with i.i.d. Gaussian residuals (with zero mean). Then the dimension of the statistical model is 3: the intercept of the line, the slope of the line, and the variance of the distribution of the residuals. (Note that in geometry, a straight line has dimension 1.)
A statistical model is nonparametric if the parameter set is infinite dimensional. A statistical model is semiparametric if it has both finite-dimensional and infinite-dimensional parameters. Formally, if d is the dimension of and n is the number of samples, both semiparametric and nonparemtric models have  as
as  . If
. If 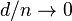 as , then the model is semiparametric; otherwise, the model is nonparametric.
as , then the model is semiparametric; otherwise, the model is nonparametric.
Parametric models are by far the most commonly-used statistical models. Regarding semiparametric and nonparametric models, Sir David Cox has said, "These typically involve fewer assumptions of structure and distributional form but usually contain strong assumptions about independencies".[5]
Nested models
Two statistical models are nested if the first model can be transformed into the second model by imposing constraints on the parameters of the first model. For example, the set of all Gaussian distributions has, nested within it, the set of zero-mean Gaussian distributions: we constrain the mean in the set of all Gaussian distributions to get the zero-mean distributions.
In that example, the first model has a higher dimension than the second model (the zero-mean model has dimension 1). Such is usually, but not always, the case. As a different example, the set of positive-mean Gaussian distributions, which has dimension 2, is nested within the set of all Gaussian distributions.
Comparing models
It is assumed that there is a "true" probability distribution that generates the observed data. The main goal of model selection is to make statements about which elements of are most likely to adequately approximate the true distribution.
Models can be compared to each other. This can either be done when we have done an exploratory data analysis or a confirmatory data analysis. In an exploratory analysis, we formulate all models we can think of, and see which describes our data best. In a confirmatory analysis we check which of the models that we have described before the data was collected best fits the data, or test if our only model fits the data.
Common criteria for comparing models include R2, Bayes factor, and the likelihood-ratio test together with its generalization relative likelihood.
Konishi & Kitagawa state: "The majority of the problems in statistical inference can be considered to be problems related to statistical modeling. They are typically formulated as comparisons of several statistical models."[6] Relatedly, Sir David Cox has said, "How [the] translation from subject-matter problem to statistical model is done is often the most critical part of an analysis".[7]
See also
Notes
- ↑ Adèr 2008
- 1 2 McCullagh 2002
- ↑ Burnham & Anderson 2002, §1.2.5
- ↑ Konishi & Kitagawa 2008, §1.1
- ↑ Cox 2006, p.2
- ↑ Konishi & Kitagawa 2008, p.75
- ↑ Cox 2006, p.197
References
- Adèr, H.J. (2008), "Modelling", in Adèr, H.J.; Mellenbergh, G.J., Advising on Research Methods: a consultant's companion, Huizen, The Netherlands: Johannes van Kessel Publishing, pp. 271–304.
- Burnham, K. P.; Anderson, D. R. (2002), Model Selection and Multimodel Inference (2nd ed.), Springer-Verlag, ISBN 0-387-95364-7.
- Cox, D.R. (2006), Principles of Statistical Inference, Cambridge University Press.
- Konishi, S.; Kitagawa, G. (2008), Information Criteria and Statistical Modeling, Springer.
- McCullagh, P. (2002), "What is a statistical model?", Annals of Statistics 30: 1225–1310, doi:10.1214/aos/1035844977.
Further reading
- Davison A.C. (2008), Statistical Models, Cambridge University Press.
- Freedman D.A. (2009), Statistical Models, Cambridge University Press.
- Helland I.S. (2010), Steps Towards a Unified Basis for Scientific Models and Methods, World Scientific.
- Kroese D.P., Chan J.C.C. (2014), Statistical Modeling and Computation, Springer.
- Stapleton J.H. (2007), Models for Probability and Statistical Inference, Wiley-Interscience.