Shannon's source coding theorem
In information theory, Shannon's source coding theorem (or noiseless coding theorem) establishes the limits to possible data compression, and the operational meaning of the Shannon entropy.
The source coding theorem shows that (in the limit, as the length of a stream of independent and identically-distributed random variable (i.i.d.) data tends to infinity) it is impossible to compress the data such that the code rate (average number of bits per symbol) is less than the Shannon entropy of the source, without it being virtually certain that information will be lost. However it is possible to get the code rate arbitrarily close to the Shannon entropy, with negligible probability of loss.
The source coding theorem for symbol codes places an upper and a lower bound on the minimal possible expected length of codewords as a function of the entropy of the input word (which is viewed as a random variable) and of the size of the target alphabet.
Statements
Source coding is a mapping from (a sequence of) symbols from an information source to a sequence of alphabet symbols (usually bits) such that the source symbols can be exactly recovered from the binary bits (lossless source coding) or recovered within some distortion (lossy source coding). This is the concept behind data compression.
Source coding theorem
In information theory, the source coding theorem (Shannon 1948)[1] informally states that (MacKay 2003, pg. 81,[2] Cover:Chapter 5[3]):
N i.i.d. random variables each with entropy H(X) can be compressed into more than N H(X) bits with negligible risk of information loss, as N → ∞; but conversely, if they are compressed into fewer than N H(X) bits it is virtually certain that information will be lost.
Source coding theorem for symbol codes
Let Σ1, Σ2 denote two finite alphabets and let Σ∗
1 and Σ∗
2 denote the set of all finite words from those alphabets (respectively).
Suppose that X is a random variable taking values in Σ1 and let f be a uniquely decodable code from Σ∗
1 to Σ∗
2 where |Σ2| = a. Let S denote the random variable given by the word length f (X).
If f is optimal in the sense that it has the minimal expected word length for X, then (Shannon 1948):
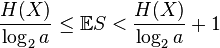
Proof: Source coding theorem
Given X is an i.i.d. source, its time series X1, ..., Xn is i.i.d. with entropy H(X) in the discrete-valued case and differential entropy in the continuous-valued case. The Source coding theorem states that for any ε > 0 for any rate larger than the entropy of the source, there is large enough n and an encoder that takes n i.i.d. repetition of the source, X1:n, and maps it to n(H(X) + ε) binary bits such that the source symbols X1:n are recoverable from the binary bits with probability at least 1 − ε.
Proof of Achievability. Fix some ε > 0, and let
![p(x_1, \ldots, x_n) = \Pr \left[X_1 = x_1, \cdots, X_n = x_n \right].](../I/m/88253cdaf1fbb6128b379a0fb2a97f56.png)
The typical set, Aε
n, is defined as follows:
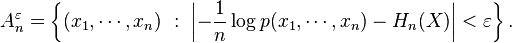
The Asymptotic Equipartition Property (AEP) shows that for large enough n, the probability that a sequence generated by the source lies in the typical set, Aε
n, as defined approaches one. In particular there for large enough n, 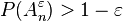 (See
AEP for a proof):
(See
AEP for a proof):
The definition of typical sets implies that those sequences that lie in the typical set satisfy:
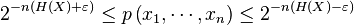
Note that:
- The probability of a sequence from X being drawn from Aε
n is greater than 1 − ε.
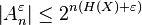 since the probability of the whole set Aε
since the probability of the whole set Aε
n is at most one.
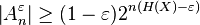 . For the proof, use the upper bound on the probability of each term in typical set and the lower bound on the probability of the whole set Aε
. For the proof, use the upper bound on the probability of each term in typical set and the lower bound on the probability of the whole set Aε
n.
Since 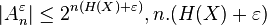 bits are enough to point to any string in this set.
bits are enough to point to any string in this set.
The encoding algorithm: The encoder checks if the input sequence lies within the typical set; if yes, it outputs the index of the input sequence within the typical set; if not, the encoder outputs an arbitrary n(H(X) + ε) digit number. As long as the input sequence lies within the typical set (with probability at least 1 − ε), the encoder doesn't make any error. So, the probability of error of the encoder is bounded above by ε.
Proof of Converse. The converse is proved by showing that any set of size smaller than Aε
n (in the sense of exponent) would cover a set of probability bounded away from 1.
Proof: Source coding theorem for symbol codes
For 1 ≤ i ≤ n let si denote the word length of each possible xi. Define 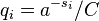 , where C is chosen so that q1 + ... + qn = 1. Then
, where C is chosen so that q1 + ... + qn = 1. Then
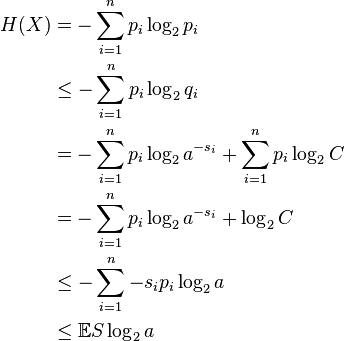
where the second line follows from Gibbs' inequality and the fifth line follows from Kraft's inequality:
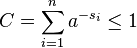
so log C ≤ 0.
For the second inequality we may set
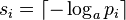
so that
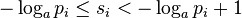
and so
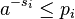
and
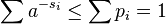
and so by Kraft's inequality there exists a prefix-free code having those word lengths. Thus the minimal S satisfies
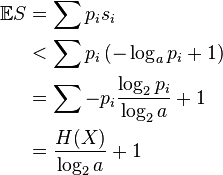
Extension to non-stationary independent sources
Fixed Rate lossless source coding for discrete time non-stationary independent sources
Define typical set Aε
n as:
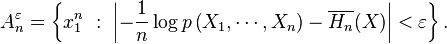
Then, for given δ > 0, for n large enough, Pr(Aε
n) > 1 − δ. Now we just encode the sequences in the typical set, and usual methods in source coding show that the cardinality of this set is smaller than 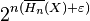 . Thus, on an average, Hn(X) + ε bits suffice for encoding with probability greater than 1 − δ, where ε and δ can be made arbitrarily small, by making n larger.
. Thus, on an average, Hn(X) + ε bits suffice for encoding with probability greater than 1 − δ, where ε and δ can be made arbitrarily small, by making n larger.
See also
References
- ↑ C.E. Shannon, "A Mathematical Theory of Communication", Bell System Technical Journal, vol. 27, pp. 379–423, 623-656, July, October, 1948
- ↑ David J. C. MacKay. Information Theory, Inference, and Learning Algorithms Cambridge: Cambridge University Press, 2003. ISBN 0-521-64298-1
- ↑ Cover, Thomas M. (2006). "Chapter 5: Data Compression". Elements of Information Theory. John Wiley & Sons. ISBN 0-471-24195-4.