Sliced inverse regression
Sliced inverse regression (SIR) is a tool for dimension reduction in the field of multivariate statistics.
In statistics, regression analysis is a popular way of studying the relationship between a response variable y and its explanatory variable 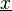 , which is a p-dimensional vector. There are several approaches which come under the term of regression. For example parametric methods include multiple linear regression; non-parametric techniques include local smoothing.
, which is a p-dimensional vector. There are several approaches which come under the term of regression. For example parametric methods include multiple linear regression; non-parametric techniques include local smoothing.
With high-dimensional data (as p grows), the number of observations needed to use local smoothing methods escalates exponentially. Reducing the number of dimensions makes the operation computable. Dimension reduction aims to show only the most important directions of the data. SIR uses the inverse regression curve, 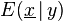 to perform a weighted principal component analysis, with which one identifies the effective dimension reducing directions.
to perform a weighted principal component analysis, with which one identifies the effective dimension reducing directions.
This article first introduces the reader to the subject of dimension reduction and how it is performed using the model here. There is then a short review on inverse regression, which later brings these pieces together.
Model
Given a response variable  and a (random) vector
and a (random) vector 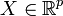 of explanatory variables, SIR is based on the model
of explanatory variables, SIR is based on the model
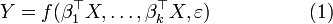
where 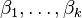 are unknown projection vectors.
are unknown projection vectors. 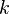 is an unknown number (the dimensionality of the space we try to reduce our data to) and, of course, as we want to reduce dimension, smaller than
is an unknown number (the dimensionality of the space we try to reduce our data to) and, of course, as we want to reduce dimension, smaller than  .
. 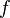 is an unknown function on
is an unknown function on 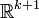 , as it only depends on arguments, and
, as it only depends on arguments, and  is the error with
is the error with ![E[\varepsilon|X]=0](../I/m/5fca1b4b6a316c651a14df1770a7c276.png) and finite variance
and finite variance  . The model describes an ideal solution, where depends on only through a dimensional subspace. I.e. one can reduce to dimension of the explanatory variable from to a smaller number without losing any information.
. The model describes an ideal solution, where depends on only through a dimensional subspace. I.e. one can reduce to dimension of the explanatory variable from to a smaller number without losing any information.
An equivalent version of  is: the conditional distribution of given
is: the conditional distribution of given  depends on only through the dimensional random vector
depends on only through the dimensional random vector  . This perfectly reduced vector can be seen as informative as the original in explaining .
. This perfectly reduced vector can be seen as informative as the original in explaining .
The unknown 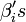 are called the effective dimension reducing directions (EDR-directions). The space that is spanned by these vectors is denoted the effective dimension reducing space (EDR-space).
are called the effective dimension reducing directions (EDR-directions). The space that is spanned by these vectors is denoted the effective dimension reducing space (EDR-space).
Relevant linear algebra background
To be able to visualize the model, note a short review on vector spaces:
For the definition of a vector space and some further properties I will refer to the article Linear Algebra and Gram-Schmidt Orthogonalization or any textbook in linear algebra and mention only the most important facts for understanding the model.
As the EDR-space is a dimensional subspace, we need to know what a subspace is. A subspace of 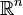 is defined as a subset
is defined as a subset  , if it holds that
, if it holds that
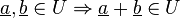
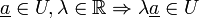
Given  , then
, then  , the set of all linear combinations of these vectors, is called a linear subspace and is therefore a vector space. One says, the vectors
, the set of all linear combinations of these vectors, is called a linear subspace and is therefore a vector space. One says, the vectors  span
span 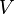 . But the vectors that span a space are not unique. This leads us to the concept of a basis and the dimension of a vector space:
. But the vectors that span a space are not unique. This leads us to the concept of a basis and the dimension of a vector space:
A set  of linear independent vectors of a vector space is called basis of , if it holds that
of linear independent vectors of a vector space is called basis of , if it holds that
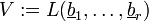
The dimension of 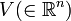 is equal to the maximum number of linearly independent vectors in . A set of
is equal to the maximum number of linearly independent vectors in . A set of  linear independent vectors of set up a basis of . The dimension of a vector space is unique, as the basis itself is not. Several bases can span the same space.
Of course also dependent vectors span a space, but the linear combinations of the latter can give only rise to the set of vectors lying on a straight line. As we are searching for a dimensional subspace, we are interested in finding linearly independent vectors that span the dimensional subspace we want to project our data on.
linear independent vectors of set up a basis of . The dimension of a vector space is unique, as the basis itself is not. Several bases can span the same space.
Of course also dependent vectors span a space, but the linear combinations of the latter can give only rise to the set of vectors lying on a straight line. As we are searching for a dimensional subspace, we are interested in finding linearly independent vectors that span the dimensional subspace we want to project our data on.
Curse of dimensionality
The reason why we want to reduce the dimension of the data is due to the "curse of dimensionality" and of course, for graphical purposes. The curse of dimensionality is due to rapid increase in volume adding more dimensions to a (mathematical) space. For example, consider 100 observations from support ![[0,1]](../I/m/ccfcd347d0bf65dc77afe01a3306a96b.png) , which cover the interval quite well, and compare it to 100 observations from the corresponding
, which cover the interval quite well, and compare it to 100 observations from the corresponding  dimensional unit hypersquare, which are isolated points in a vast empty space. It is easy to draw inferences about the underlying properties of the data in the first case, whereas in the latter, it is not.
dimensional unit hypersquare, which are isolated points in a vast empty space. It is easy to draw inferences about the underlying properties of the data in the first case, whereas in the latter, it is not.
Inverse regression
Computing the inverse regression curve (IR) means instead of looking for
![\,E[Y|X=x]](../I/m/b3abc3002a91b757662a1731e617e5d5.png) , which is a curve in
, which is a curve in 
we calculate
![\,E[X|Y=y]](../I/m/a4ce58db8db761b9e21e3a64690bcf57.png) , which is also a curve in , but consisting of one-dimensional regressions.
, which is also a curve in , but consisting of one-dimensional regressions.
The center of the inverse regression curve is located at ![\,E[E[X|Y]]=E[X]](../I/m/607eb0fa694cbd4c20141f4bcd3849c0.png) . Therefore, the centered inverse regression curve is
. Therefore, the centered inverse regression curve is
which is a dimensional curve in . In what follows we will consider this centered inverse regression curve and we will see that it lies on a dimensional subspace spanned by 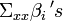 .
.
But before seeing that this holds true, we will have a look at how the inverse regression curve is computed within the SIR-Algorithm, which will be introduced in detail later. What comes is the "sliced" part of SIR. We estimate the inverse regression curve by dividing the range of into 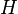 nonoverlapping intervals (slices), to afterwards compute the sample means
nonoverlapping intervals (slices), to afterwards compute the sample means 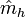 of each slice. These sample means are used as a crude estimate of the IR-curve, denoted as
of each slice. These sample means are used as a crude estimate of the IR-curve, denoted as 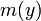 . There are several ways to define the slices, either in a way that in each slice are equally much observations, or we define a fixed range for each slice, so that we then get different proportions of the
. There are several ways to define the slices, either in a way that in each slice are equally much observations, or we define a fixed range for each slice, so that we then get different proportions of the 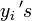 that fall into each slice.
that fall into each slice.
Inverse regression versus dimension reduction
As just mentioned, the centered inverse regression curve lies on a dimensional subspace spanned by (and therefore also the crude estimate we compute). This is the connection between our Model and Inverse Regression. We shall see that this is true, with only one condition on the design distribution that must hold. This condition is, that:

I.e. the conditional expectation is linear in 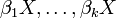 , that is, for some constants
, that is, for some constants  . This condition is satisfied when the distribution of is elliptically symmetric (e.g. the normal distribution). This seems to be a pretty strong requirement. It could help, for example, to closer examine the distribution of the data, so that outliers can be removed or clusters can be separated before analysis.
. This condition is satisfied when the distribution of is elliptically symmetric (e.g. the normal distribution). This seems to be a pretty strong requirement. It could help, for example, to closer examine the distribution of the data, so that outliers can be removed or clusters can be separated before analysis.
Given this condition and , it is indeed true that the centered inverse regression curve ![\,E[X|Y=y]-E[X]](../I/m/c32d46f4dca48ef819024bc26559b356.png) is contained in the linear subspace spanned by
is contained in the linear subspace spanned by 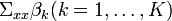 , where
, where  . The proof is provided by Duan and Li in Journal of the American Statistical Association (1991).
. The proof is provided by Duan and Li in Journal of the American Statistical Association (1991).
Estimation of the EDR-directions
After having had a look at all the theoretical properties, our aim is now to estimate the EDR-directions. For that purpose, we conduct a (weighted) principal component analysis for the sample means 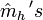 , after having standardized to
, after having standardized to 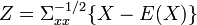 . Corresponding to the theorem above, the IR-curve
. Corresponding to the theorem above, the IR-curve ![\,m_1(y)=E[Z|Y=y]](../I/m/901e383851c18bc37cb10fb51dc490e5.png) lies in the space spanned by
lies in the space spanned by 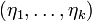 , where
, where 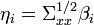 . (Due to the terminology introduced before, the
. (Due to the terminology introduced before, the 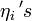 are called the standardized effective dimension reducing directions.) As a consequence, the covariance matrix
are called the standardized effective dimension reducing directions.) As a consequence, the covariance matrix ![\,cov[E[Z|Y]]](../I/m/462d2d097733e87d596162b7d3dc8c4c.png) is degenerate in any direction orthogonal to the . Therefore, the eigenvectors
is degenerate in any direction orthogonal to the . Therefore, the eigenvectors 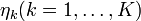 associated with the
associated with the  largest eigenvalues are the standardized EDR-directions.
largest eigenvalues are the standardized EDR-directions.
Back to PCA. That is, we calculate the estimate for 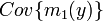 :
:
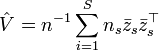
and identify the eigenvalues  and the eigenvectors
and the eigenvectors 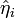 of
of  , which are the standardized EDR-directions. (For more details about that see next section: Algorithm.) Remember that the main idea of PC transformation is to find the most informative projections that maximize variance!
, which are the standardized EDR-directions. (For more details about that see next section: Algorithm.) Remember that the main idea of PC transformation is to find the most informative projections that maximize variance!
Note that in some situations SIR does not find the EDR-directions. One can overcome this difficulty by considering the conditional covariance  . The principle remains the same as before, but one investigates the IR-curve with the conditional covariance instead of the conditional expectation. For further details and an example where SIR fails, see Härdle and Simar (2003).
. The principle remains the same as before, but one investigates the IR-curve with the conditional covariance instead of the conditional expectation. For further details and an example where SIR fails, see Härdle and Simar (2003).
Algorithm
The algorithm to estimate the EDR-directions via SIR is as follows. It is taken from the textbook Applied Multivariate Statistical Analysis (Härdle and Simar 2003)
1. Let  be the covariance matrix of . Standardize to
be the covariance matrix of . Standardize to
(We can therefore rewrite as
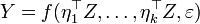
where 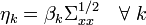 For the standardized variable Z it holds that
For the standardized variable Z it holds that ![\,E[Z]=0](../I/m/4ab19098754db6e46a9a79b5c5b6911a.png) and
and 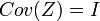 .)
.)
2. Divide the range of 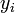 into
into 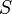 nonoverlapping slices
nonoverlapping slices  is the number of observations within each slice and
is the number of observations within each slice and 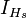 the indicator function for this slice:
the indicator function for this slice:
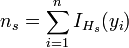
3. Compute the mean of 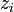 over all slices, which is a crude estimate
over all slices, which is a crude estimate  of the inverse regression curve
of the inverse regression curve 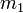 :
:

4. Calculate the estimate for :
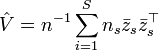
5. Identify the eigenvalues  and the eigenvectors
and the eigenvectors 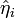 of
of 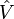 , which are the standardized EDR-directions.
, which are the standardized EDR-directions.
6. Transform the standardized EDR-directions back to the original scale. The estimates for the EDR-directions are given by:
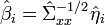
(which are not necessarily orthogonal)
For examples, see the book by Härdle and Simar (2003).
References
- Li, K-C. (1991) "Sliced Inverse Regression for Dimension Reduction", Journal of the American Statistical Association, 86, 316–327 Jstor
- Cook, R.D. and Sanford Weisberg, S. (1991) "Sliced Inverse Regression for Dimension Reduction: Comment", Journal of the American Statistical Association, 86, 328–332 Jstor
- Härdle, W. and Simar, L. (2003) Applied Multivariate Statistical Analysis, Springer Verlag. ISBN 3-540-03079-4
- Kurzfassung zur Vorlesung Mathematik II im Sommersemester 2005, A. Brandt