Shapiro–Wilk test
The Shapiro–Wilk test is a test of normality in frequentist statistics. It was published in 1965 by Samuel Sanford Shapiro and Martin Wilk.[1]
Theory
The Shapiro–Wilk test utilizes the null hypothesis principle to check whether a sample x1, ..., xn came from a normally distributed population. The test statistic is:

where
-
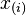 (with parentheses enclosing the subscript index i) is the ith order statistic, i.e., the ith-smallest number in the sample;
(with parentheses enclosing the subscript index i) is the ith order statistic, i.e., the ith-smallest number in the sample; -
 is the sample mean;
is the sample mean; - the constants
 are given by[1]
are given by[1]
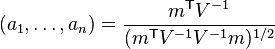
- where

- and
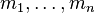 are the expected values of the order statistics of independent and identically distributed random variables sampled from the standard normal distribution, and
are the expected values of the order statistics of independent and identically distributed random variables sampled from the standard normal distribution, and 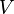 is the covariance matrix of those order statistics.
is the covariance matrix of those order statistics.
The user may reject the null hypothesis if 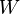 is below a predetermined threshold .
is below a predetermined threshold .
Interpretation
The null-hypothesis of this test is that the population is normally distributed. Thus if the p-value is less than the chosen alpha level, then the null hypothesis is rejected and there is evidence that the data tested are not from a normally distributed population. In other words, the data are not normal. On the contrary, if the p-value is greater than the chosen alpha level, then the null hypothesis that the data came from a normally distributed population cannot be rejected. E.g. for an alpha level of 0.05, a data set with a p-value of 0.02 rejects the null hypothesis that the data are from a normally distributed population.[2] However, since the test is biased by sample size,[3] the test may be statistically significant from a normal distribution in any large samples. Thus a Q–Q plot is required for verification in addition to the test.
Power analysis
Monte Carlo simulation has found that Shapiro–Wilk has the best power for a given significance, followed closely by Anderson–Darling when comparing the Shapiro–Wilk, Kolmogorov–Smirnov, Lilliefors, and Anderson–Darling tests.[4]
Approximation
Royston proposed an alternative method of calculating the coefficients vector by providing an algorithm for calculating values, which extended the sample size to 2000.[5] This technique is used in several software packages including R,[6] Stata,[7][8] SPSS and SAS.[9] Rahman and Govidarajulu extended the sample size further up to 5000.[10]
See also
- Anderson–Darling test
- Cramér–von Mises criterion
- Kolmogorov–Smirnov test
- Normal probability plot
- Ryan–Joiner test
- Watson test
- Lilliefors test
References
- 1 2 Shapiro, S. S.; Wilk, M. B. (1965). "An analysis of variance test for normality (complete samples)". Biometrika 52 (3–4): 591–611. doi:10.1093/biomet/52.3-4.591. JSTOR 2333709. MR 205384. p. 593
- ↑ "How do I interpret the Shapiro–Wilk test for normality?". JMP. 2004. Retrieved March 24, 2012.
- ↑ Field, Andy (2009). Discovering statistics using SPSS (3rd ed.). Los Angeles [i.e. Thousand Oaks, Calif.]: SAGE Publications. p. 143. ISBN 978-1-84787-906-6.
- ↑ Razali, Nornadiah; Wah, Yap Bee (2011). "Power comparisons of Shapiro–Wilk, Kolmogorov–Smirnov, Lilliefors and Anderson–Darling tests" (PDF). Journal of Statistical Modeling and Analytics 2 (1): 21–33. Retrieved 5 June 2012.
- ↑ Royston, Patrick (September 1992). "Approximating the Shapiro–Wilk W-test for non-normality". Statistics and Computing 2 (3): 117–119. doi:10.1007/BF01891203.
- ↑ Korkmaz, Selcuk. "Package 'royston'" (PDF). Cran.r-project.org. Retrieved 26 February 2014.
- ↑ Royston, Patrick. "Shapiro–Wilk and Shapiro–Francia Tests". Stata Technical Bulletin, StataCorp LP 1 (3).
- ↑ Shapiro–Wilk and Shapiro–Francia tests for normality
- ↑ Park, Hun Myoung (2002–2008). "Univariate Analysis and Normality Test Using SAS, Stata, and SPSS" (PDF). [working paper]. Retrieved 26 February 2014.
- ↑ Rahman und Govidarajulu (1997). "A modification of the test of Shapiro and Wilk for normality". Journal of Applied Statistics 24 (2): 219–236. doi:10.1080/02664769723828.
External links
- Samuel Sanford Shapiro
- Algorithm AS R94 (Shapiro Wilk) FORTRAN code
- Exploratory analysis using the Shapiro–Wilk normality test in R
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||