Particle filter
Particle filters or Sequential Monte Carlo (SMC) methods are a set of genetic-type particle Monte Carlo methodologies to solve the filtering problem. The term "particle filters" was first coined in 1996 by Del Moral[1] in reference to mean field interacting particle methods used in fluid mechanics since the beginning of the 1960s. The terminology "sequential Monte Carlo" was proposed by Liu and Chen in 1998.
From the statistical and probabilistic point of view, particle filters can be interpreted as mean field particle interpretations of Feynman-Kac probability measures.[2][3][4][5][6] These particle integration techniques were developed in molecular chemistry and computational physics by Theodore E. Harris and Herman Kahn in 1951, Marshall. N. Rosenbluth and Arianna. W. Rosenbluth in 1955[7] and more recently by Jack H. Hetherington in 1984.[8] In computational physics, these Feynman-Kac type path particle integration methods are also used in Quantum Monte Carlo, and more specifically Diffusion Monte Carlo methods.[9][10][11] Feynman-Kac interacting particle methods are also strongly related to mutation-selection genetic algorithms currently used in evolutionary computing to solve complex optimization problems.
The particle filter methodology is used to solve Hidden Markov Chain (HMM) and nonlinear filtering problems arising in signal processing and Bayesian statistical inference. The filtering problem consists in estimating the internal states in dynamical systems when partial observations are made, and random perturbations are present in the sensors as well as in the dynamical system. The objective is to compute the conditional probability (a.k.a. posterior distributions) of the states of some Markov process, given some noisy and partial observations. With the notable exception of linear-Gaussian signal-observation models (Kalman filter) or wider classes of models (Benes filter[12]) Mireille Chaleyat-Maurel and Dominique Michel proved in 1984 that the sequence of posterior distributions of the random states of the signal given the observations (a.k.a. optimal filter) have no finitely recursive recursion.[13] Various numerical methods based on fixed grid approximations, Markov Chain Monte Carlo techniques (MCMC), conventional linearization, extended Kalman filters, or determining the best linear system (in expect cost-error sense) have never really coped with large scale systems, unstable processes or when the nonlinearities are not sufficiently smooth.
Particle filtering methodology uses a genetic type mutation-selection sampling approach, with a set of particles (also called individuals, or samples) to represent the posterior distribution of some stochastic process given some noisy and/or partial observations. The state-space model can be nonlinear and the initial state and noise distributions can take any form required. Particle filter techniques provide a well-established methodology[1][14][15] for generating samples from the required distribution without requiring assumptions about the state-space model or the state distributions. However, these methods do not perform well when applied to very high-dimensional systems.
Particle filters implement the prediction-updating transitions of the filtering equation directly by using a genetic type mutation-selection particle algorithm. The samples from the distribution are represented by a set of particles; each particle has a likelihood weight assigned to it that represents the probability of that particle being sampled from the probability density function. Weight disparity leading to weight collapse is a common issue encountered in these filtering algorithms; however it can be mitigated by including a resampling step before the weights become too uneven. Several adaptive resampling criteria can be used, including the variance of the weights and the relative entropy w.r.t. the uniform distribution.[16] In the resampling step, the particles with negligible weights are replaced by new particles in the proximity of the particles with higher weights.
Particle filters and Feynman-Kac particle methodologies find application in signal and image processing, Bayesian inference, machine learning, risk analysis and rare event sampling, engineering and robotics, artificial intelligence, bioinformatics, phylogenetics, computational science, Economics and mathematical finance, molecular chemistry, computational physics, pharmacokinetic and other fields.
History
Heuristic like algorithms
From the statistical and probabilistic viewpoint, particle filters belong to the class of branching/genetic type algorithms, and mean field type interacting particle methodologies. The interpretations of these particle methods depends on the scientific discipline. In Evolutionary Computing, mean field genetic type particle methodologies are often used as a heuristic and natural search algorithms (a.k.a. Metaheuristic). In computational physics and molecular chemistry they are used to solve Feynman-Kac path integration problems, or the compute Boltzmann-Gibbs measures, top eigenvalues and ground states of Schrödinger operators. In Biology and Genetics they also represent the evolution of a population of individuals or genes in some environment.
The origins of mean field type evolutionary computational techniques can be traced to 1950 and 1954 with the seminal work of Alan Turing on genetic type mutation-selection learning machines[17] and the articles by Nils Aall Barricelli at the Institute for Advanced Study in Princeton, New Jersey.[18][19] The first trace of particle filters in statistical methodology dates back to the mid-50's; the 'Poor Man's Monte Carlo',[20] that was proposed by Hammersley et al., in 1954, contained hints of the genetic type particle filtering methods used today. In 1963, Nils Aall Barricelli simulated a genetic type algorithm to mimic the ability of individuals to play a simple game.[21] In evolutionary computing literature, genetic type mutation-selection algorithms became popular through the seminal work of John Holland in the early 1970s, and particularly his book[22] published in 1975.
In Biology and Genetics, the Australian geneticist Alex Fraser also published in 1957 a series of papers on the genetic type simulation of artificial selection of organisms.[23] The computer simulation of evolution by biologists became more common in the early 1960s, and the methods were described in books by Fraser and Burnell (1970)[24] and Crosby (1973).[25] Fraser's simulations included all of the essential elements of modern mutation-selection genetic particle algorithms.
From the mathematical viewpoint, the conditional distribution of the random states of a signal given some partial and noisy observations is described by a Feynman-Kac probability on the random trajectories of the signal weighted by a sequence of likelihood potential functions.[2][3] Quantum Monte Carlo, and more specifically Diffusion Monte Carlo methods can also be interpreted as a mean field genetic type particle approximation of Feynman-Kac path integrals.[2][3][4][8][9][26][27] The origins of Quantum Monte Carlo methods are often attributed to Enrico Fermi and Robert Richtmyer who developed in 1948 a mean field particle interpretation of neutron-chain reactions,[28] but the first heuristic-like and genetic type particle algorithm (a.k.a. Resampled or Reconfiguration Monte Carlo methods) for estimating ground state energies of quantum systems (in reduced matrix models) is due to Jack H. Hetherington in 1984.[8] We also quote an earlier seminal works of Theodore E. Harris and Herman Kahn in particle physics, published in 1951, using mean field but heuristic-like genetic methods for estimating particle transmission energies.[29] In molecular chemistry, the use of genetic heuristic-like particle methodologies (a.k.a. pruning and enrichment strategies) can be traced back to 1955 with the seminal work of Marshall. N. Rosenbluth and Arianna. W. Rosenbluth.[7]
The use of genetic particle algorithms in advanced signal processing and Bayesian inference is more recent. It was in 1993, that Gordon et al., published in their seminal work[30] the first application of genetic type algorithm in Bayesian statistical inference. The authors named their algorithm 'the bootstrap filter', and demonstrated that compared to other filtering methods, their bootstrap algorithm does not require any assumption about that state-space or the noise of the system. We also quote another pioneering article in this field of Genshiro Kitagawa on a related "Monte Carlo filter",[31] and the ones by Pierre Del Moral[1] and Himilcon Carvalho, Pierre Del Moral, André Monin and Gérard Salut[32] on particle filters published in the mid-1990s. Particle filters were also developed in signal processing in the early 1989-1992 by P. Del Moral, J.C. Noyer, G. Rigal, and G. Salut in the LAAS-CNRS in a series of restricted and classified research reports with STCAN (Service Technique des Constructions et Armes Navales), the IT company DIGILOG, and the LAAS-CNRS (the Laboratory for Analysis and Architecture of Systems) on RADAR/SONAR and GPS signal processing problems.[33][34][35][36][37][38]
Mathematical foundations
From 1950 to 1996, all the publications on particle filters, genetic algorithms, including the pruning and resample Monte Carlo methods introduced in computational physics and molecular chemistry, present natural and heuristic-like algorithms applied to different situations without a single proof of their consistency, nor a discussion on the bias of the estimates and on genealogical and ancestral tree based algorithms.
The mathematical foundations and the first rigorous analysis of these particle algorithms are due to Pierre Del Moral[1][14] in 1996. The article[1] also contains a proof of the unbiased properties of a particle approximations of likelihood functions and unnormalized conditional probability measures. The unbiased particle estimator of the likelihood functions presented in this article is used today in Bayesian statistical inference.
Branching type particle methodologies with varying population sizes were also developed toward the end of the 1990s by Dan Crisan, Jessica Gaines and Terry Lyons,[39][40][41] and by Dan Crisan, Pierre Del Moral and Terry Lyons.[42] Further developments in this field were developed in 2000 by P. Del Moral, A. Guionnet and L. Miclo.[3][43][44] The first central limit theorems are due to Pierre Del Moral and Alice Guionnet[45] in 1999 and Pierre Del Moral and Laurent Miclo[3] in 2000. The first uniform convergence results with respect to the time parameter for particle filters were developed in the end of the 1990s by Pierre Del Moral and Alice Guionnet.[43][44] The first rigorous analysis of genealogical tree based particle filter smoothers is due to P. Del Moral and L. Miclo in 2001[46]
The theory on Feynman-Kac particle methodologies and related particle filters algorithms has been developed in 2000 and 2004 in the books.[3][15] These abstract probabilistic models encapsulate genetic type algorithms, particle and bootstrap filters, interacting Kalman filters (a.k.a. Rao–Blackwellized particle filter[47]), importance sampling and resampling style particle filter techniques, including genealogical tree based and particle backward methodologies for solving filtering and smoothing problems. Other classes of particle filtering methodologies includes genealogical tree based models,[5][15][48] backward Markov particle models,[5][49] adaptive mean field particle models,[16] island type particle models,[50][51] and particle Markov chain Monte Carlo methodologies.[52][53]
The filtering problem
Objective
The objective of a particle filter is to estimate the posterior density of the state variables given the observation variables. The particle filter is designed for a hidden Markov Model, where the system consists of hidden and observable variables. The observable variables (observation process) are related to the hidden variables (state-process) by some functional form that is known. Similarly the dynamical system describing the evolution of the state variables is also known probabilistically.
A generic particle filter estimates the posterior distribution of the hidden states using the observation measurement process. Consider a state-space shown in the diagram below.

The filtering problem is to estimate sequentially the values of the hidden states  , given the values of the observation process
, given the values of the observation process  at any time step k.
at any time step k.
All Bayesian estimates of follow from the posterior density p(xk | y0,y1,…,yk). The particle filter methodology provides an approximation of these conditional probabilities using the empirical measure associated with a genetic type particle algorithm. In contrast, the MCMC or importance sampling approach would model the full posterior p(x0,x1,…,xk | y0,y1,…,yk).
An illustration in Tracking and RADAR processing
In a 3d-simplified Singer's tracking model[54] the target is represented by a Markov chain with 3 coordinates

The first coordinate  represents the acceleration of the target at time n, the second and the third
represents the acceleration of the target at time n, the second and the third  stands for the speed and the position of the target at time n.
stands for the speed and the position of the target at time n.
The maneuver equation are often derived from a time discretization of a continuous time model given by the equations

for some viscosity coefficients  , some time step
, some time step  . In the above display, the unknown acceleration jump times are modeled by a sequence of independent and identically distributed {0, 1}-valued Bernoulli variables
. In the above display, the unknown acceleration jump times are modeled by a sequence of independent and identically distributed {0, 1}-valued Bernoulli variables  . The unknown speed-up changes are modeled by a sequence of independent and identically distributed variables
. The unknown speed-up changes are modeled by a sequence of independent and identically distributed variables  . The RADAR sensor delivers at each time step some noisy information on the position of the target. This observation model is given the equation
. The RADAR sensor delivers at each time step some noisy information on the position of the target. This observation model is given the equation

The random perturbations of the sensors coming from the thermic noise of the uncertainty of the model are represented by a sequence of independent random variable  with a prescribed probability density. The objective of the filtering problem consists of computing sequentially the conditional distribution of the signal
with a prescribed probability density. The objective of the filtering problem consists of computing sequentially the conditional distribution of the signal  given an observation sequence
given an observation sequence  , at any time step n. A more complex problem is to compute the conditional distribution of the random paths of the signal
, at any time step n. A more complex problem is to compute the conditional distribution of the random paths of the signal  given an observation sequence
given an observation sequence  at any time step n. In filtering literature, these state estimation problems can be given different names:
at any time step n. In filtering literature, these state estimation problems can be given different names:
- The optimal filter is the conditional probability distribution of the signal given the observation sequence
 .
. - The one step optimal predictor is the conditional probability distribution of the signal given the observation sequence
 .
. - The smoothing problem consists of estimating the conditional probability distribution of the signal given the observation sequence
 , for some
, for some  .
.
The Signal-Observation Model
Particle methods often assume and the observations  can be modeled in this form:
can be modeled in this form:
 is a Markov process on
is a Markov process on  (for some
(for some  ) that evolves according to the transition probability density
) that evolves according to the transition probability density  . This model is also often written in a synthetic way as
. This model is also often written in a synthetic way as

- with an initial probability density
 .
.
- The observations
 take values in some state space on
take values in some state space on  (for some
(for some  ) are conditionally independent provided that are known. In other words, each only depends on . In addition, we assume conditional distribution for given
) are conditionally independent provided that are known. In other words, each only depends on . In addition, we assume conditional distribution for given  are absolutely continuous, and in a synthetic way we have
are absolutely continuous, and in a synthetic way we have

An example of system with these properties is:


where both  and
and  are mutually independent sequences with known probability density functions and g and h are known functions. These two equations can be viewed as state space equations and look similar to the state space equations for the Kalman filter. If the functions g and h in the above example are linear, and if both and are Gaussian, the Kalman filter finds the exact Bayesian filtering distribution. If not, Kalman filter based methods are a first-order approximation (EKF) or a second-order approximation (UKF in general, but if probability distribution is Gaussian a third-order approximation is possible).
are mutually independent sequences with known probability density functions and g and h are known functions. These two equations can be viewed as state space equations and look similar to the state space equations for the Kalman filter. If the functions g and h in the above example are linear, and if both and are Gaussian, the Kalman filter finds the exact Bayesian filtering distribution. If not, Kalman filter based methods are a first-order approximation (EKF) or a second-order approximation (UKF in general, but if probability distribution is Gaussian a third-order approximation is possible).
The assumption that the initial distribution and the transitions of the Markov chain are absolutely continuous with respect to the Lebesgue measure can be relaxed. To design a particle filter we simply need to assume that we can sample the transitions  of the Markov chain
of the Markov chain  and to compute the likelihood function
and to compute the likelihood function  (see for instance the genetic selection mutation description of the particle filter given below). The absolutely continuous assumption on the Markov transitions of are only used to derive in an informal (and rather abusive) way different formulae between posterior distributions using the Bayes' rule for conditional densities.
(see for instance the genetic selection mutation description of the particle filter given below). The absolutely continuous assumption on the Markov transitions of are only used to derive in an informal (and rather abusive) way different formulae between posterior distributions using the Bayes' rule for conditional densities.
Approximate Bayesian Computation models
In some important problems, the conditional distribution of the observations given the random states of the signal may fail to have a density or may be impossible or too complex to compute. In this situation, we need to resort to an additional level of approximation. One strategy is to replace the signal by the Markov chain  and to introduce a virtual observation of the form
and to introduce a virtual observation of the form
![\mathcal Y_k=Y_k+\epsilon \mathcal V_k\quad\mbox{for some parameter}\quad\epsilon\in [0,1]](../I/m/ba8120f8d180eb24e18214593c266814.png)
for some sequence of independent sequences with known probability density functions. The central idea is to observe that

The particle filter associated with the Markov process given the partial observations  is defined in terms of particles evolving in
is defined in terms of particles evolving in  with a likelihood function given with some obvious abusive notation by
with a likelihood function given with some obvious abusive notation by  . These probabilistic techniques are closely related to Approximate Bayesian Computation (ABC). In the context of particle filters, these ABC particle filtering techniques were introduced in 1998 by P. Del Moral, J. Jacod and P. Protter in the article.[55] They were further developed by P. Del Moral, A. Doucet and A. Jasra.[56][57]
. These probabilistic techniques are closely related to Approximate Bayesian Computation (ABC). In the context of particle filters, these ABC particle filtering techniques were introduced in 1998 by P. Del Moral, J. Jacod and P. Protter in the article.[55] They were further developed by P. Del Moral, A. Doucet and A. Jasra.[56][57]
The nonlinear filtering equation
The Bayes' rule for conditional probability gives:

where

Particle filters are also an approximation, but with enough particles they can be much more accurate.[1][14][15][43][44] The nonlinear filtering equation is given by the recursion
-

(Eq. 1)
with the convention  for k = 0. The nonlinear filtering problem consists in computing sequentially these sequence of conditional distributions.
for k = 0. The nonlinear filtering problem consists in computing sequentially these sequence of conditional distributions.
Feynman-Kac formulation
We fix a time horizon n and a sequence of observations , and for each k = 0, ..., n we set:

In this notation, for any bounded function F on the set of trajectories of from the origin k = 0 up to time k = n, we have the Feynman-Kac formula

These Feynman-Kac path integration models arise in a variety of scientific disciplines, including in computational physics, biology, information theory and computer sciences.[3][5][15] Their interpretations depend on the application domain. For instance, if we choose the indicator function  of some subset of the state space, they represent the conditional distribution of a Markov chain given it stays in a given tube; that is, we have:
of some subset of the state space, they represent the conditional distribution of a Markov chain given it stays in a given tube; that is, we have:

and

as soon as the normalizing constant is strictly positive.
Particle filters
A Genetic type particle algorithm
Initially we start with N independent random variable  with common probability density . The genetic algorithm selection-mutation transitions
with common probability density . The genetic algorithm selection-mutation transitions

mimic/approximate the updating-prediction transitions of the optimal filter evolution (Eq. 1):
- During the selection-updating transition we sample N (conditionally) independent random variables
 with common (conditional) distribution
with common (conditional) distribution

- During the mutation-prediction transition, from each selected particle
 we sample independently a transition
we sample independently a transition

In the above displayed formulae  stands for the likelihood function evaluated at
stands for the likelihood function evaluated at  , and
, and  stands for the conditional density
stands for the conditional density  evaluated at
evaluated at  .
.
At each time k, we have the particle approximations

and

A detailed proof of these convergence results can be found in,[1][14] see also the more recent developments provided in the books.[5][15] In Genetic algorithms and Evolutionary computing community, the mutation-selection
Markov chain described above is often called the genetic algorithm with proportional selection. Several branching variants, including with random population sizes have also been proposed in the articles.[15][39][42]
Monte Carlo principles
Particle methods, like all sampling-based approaches (e.g., MCMC), generate a set of samples that approximate the filtering density

For example, we may have N samples from the approximate posterior distribution of , where the samples are labeled with superscripts as

Then, expectations with respect to the filtering distribution are approximated by
-

(Eq. 2)
with

where  stands for the Dirac measure at a given state a. The function f, in the usual way for Monte Carlo, can give all the moments etc. of the distribution up to some degree of approximation. When the approximation equation (Eq. 2) is satisfied for any bounded function f we write
stands for the Dirac measure at a given state a. The function f, in the usual way for Monte Carlo, can give all the moments etc. of the distribution up to some degree of approximation. When the approximation equation (Eq. 2) is satisfied for any bounded function f we write

Particle filters can be interpreted as a genetic type particle algorithm evolving with mutation and selection transitions. We can keep track of the ancestral lines

of the particles  . The random states
. The random states  , with the lower indices l=0,...,k, stands for the ancestor of the individual
, with the lower indices l=0,...,k, stands for the ancestor of the individual  at level l=0,...,k. In his situation, we have the approximation formula
at level l=0,...,k. In his situation, we have the approximation formula
-

(Eq. 3)
with the empirical measure

Here F stands for any founded function on the path space of the signal. In a more synthetic form (Eq. 3) is equivalent to

Particle filters can be interpreted in many different ways. From the probabilistic point of view they coincide with a mean field particle interpretation of the nonlinear filtering equation. The updating-prediction transitions of the optimal filter evolution can also be interpreted as the classical genetic type selection-mutation transitions of individuals. The sequential importance resampling technique provides another interpretation of the filtering transitions coupling importance sampling with the bootstrap resampling step. Last, but not least, particle filters can be seen as an acceptance-rejection methodology equipped with a recycling mechanism.[5][15]
Mean field particle simulation
The general probabilistic principle
The nonlinear filtering evolution can be interpreted as a dynamical system in the set of probability measures of the following form  where
where  stands for some mapping from the set of probability distribution into itself. For instance, the evolution of the one-step optimal predictor
stands for some mapping from the set of probability distribution into itself. For instance, the evolution of the one-step optimal predictor 
satisfies a nonlinear evolution starting with the probability distribution  . One of the simplest way to approximate these probability measures is to start with N independent random variables with common probability distribution . Suppose we have defined a sequence of N random variables
. One of the simplest way to approximate these probability measures is to start with N independent random variables with common probability distribution . Suppose we have defined a sequence of N random variables  such that
such that

At the next step we sample N (conditionally) independent random variables  with common law .
with common law .

A particle interpretation of the filtering equation
We illustrate this mean field particle principle in the context of the evolution of the one step optimal predictors
-

(Eq. 4)
For k = 0 we use the convention  .
.
By the law of large numbers, we have

in the sense that

for any bounded function 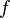 . We further assume that we have constructed a sequence of particles
. We further assume that we have constructed a sequence of particles  at some rank k such that
at some rank k such that

in the sense that for any bounded function we have

In this situation, replacing  by the empirical measure
by the empirical measure  in the evolution equation of the one-step optimal filter stated in (Eq. 4) we find that
in the evolution equation of the one-step optimal filter stated in (Eq. 4) we find that

Notice that the right hand side in the above formula is a weighted probability mixture

where stands for the density  evaluated at , and
evaluated at , and  stands for the density evaluated at for
stands for the density evaluated at for 
Then, we sample N independent random variable  with common probability density
with common probability density  so that
so that

Iterating this procedure, we design a Markov chain such that

Notice that the optimal filter is approximated at each time step k using the Bayes' formulae

The terminology "mean field approximation" comes from the fact that we replace at each time step the probability measure  by the empirical approximation . The mean field particle approximation of the filtering problem is far from being unique. Several strategies are developed in the books.[5][15]
by the empirical approximation . The mean field particle approximation of the filtering problem is far from being unique. Several strategies are developed in the books.[5][15]
Some convergence results
The analysis of the convergence of particle filters has been started in 1996[1][14] and in 2000 in the book[3] and the series of articles.[42][43][44][45][46][58][59] More recent developments can be found in the books,[5][15] When the filtering equation is stable (in the sense that it corrects any erroneous initial condition), the bias and the variance of the particle particle estimates

are controlled by the non asymptotic uniform estimates

![\sup_{k\geqslant 0}E\left(\left[\widehat{I}_k(f)-I_k(f)\right]^2\right)\leqslant \frac{c_2}{N}](../I/m/4936d9fded2872dd7e68979a2b595c23.png)
for any function f bounded by 1, and for some finite constants  In addition, for any
In addition, for any  :
:

for some finite constants  related to the asymptotic bias and variance of the particle estimate, and some finite constant c. The same results are satisfied if we replace the one step optimal predictor by the optimal filter approximation.
related to the asymptotic bias and variance of the particle estimate, and some finite constant c. The same results are satisfied if we replace the one step optimal predictor by the optimal filter approximation.
Genealogical trees and Unbiasedness properties
Genealogical tree based particle smoothing
Tracing back in time the ancestral lines

of the individuals  and
and  at every time step k, we also have the particle approximations
at every time step k, we also have the particle approximations

These empirical approximations are equivalent to the particle integral approximations

for any bounded function F on the random trajectories of the signal. As shown in[48] the evolution of the genealogical tree coincides with a mean field particle interpretation of the evolution equations associated with the posterior densities of the signal trajectories. For more details on these path space models, we refer to the books.[5][15]
Unbiased particle estimates of likelihood functions
We use the product formula

with

and the conventions  and
and  for k = 0. Replacing by the empirical approximation
for k = 0. Replacing by the empirical approximation
in the above displayed formula, we design the following unbiased particle approximation of the likelihood function

with

where stands for the density evaluated at . The design of this particle estimate and the unbiasedness property has been proved in 1996 in the article.[1] Refined variance estimates can be found in[15] and.[5]
Backward particle smoothers
Using Bayes' rule, we have the formula

Notice that

This implies that

Replacing the one-step optimal predictors  by the particle empirical measures
by the particle empirical measures

we find that

We conclude that

with the backward particle approximation

The probability measure

is the probability of the random paths of a Markov chain  running backward in time from time k=n to time k=0, and evolving at each time step k in the state space associated with the population of particles
running backward in time from time k=n to time k=0, and evolving at each time step k in the state space associated with the population of particles 
- Initially (at time k=n) the chain
 chooses randomly a state with the distribution
chooses randomly a state with the distribution

- From time k to the time (k-1), the chain starting at some state
 for some at time k moves at time (k-1) to a random state
for some at time k moves at time (k-1) to a random state  chosen with the discrete weighted probability
chosen with the discrete weighted probability

In the above displayed formula,  stands for the conditional distribution
stands for the conditional distribution  evaluated at
evaluated at  . In the same vein,
. In the same vein,  and
and  stand for the conditional densities
stand for the conditional densities  and evaluated at and
and evaluated at and  These models allows to reduce integration with respect to the densities
These models allows to reduce integration with respect to the densities  in terms of matrix operations with respect to the Markov transitions of the chain described above.[49] For instance, for any function
in terms of matrix operations with respect to the Markov transitions of the chain described above.[49] For instance, for any function  we have the particle estimates
we have the particle estimates
![\begin{align}
\int p(d(x_0,\cdots,x_n)&|(y_0,\cdots,y_{n-1}))f_k(x_k) \\
&\approx_{N\uparrow\infty} \int \widehat{p}_{backward}(d(x_0,\cdots,x_n)| (y_0,\cdots,y_{n-1})) f_k(x_k) \\
&=\int \widehat{p}(dx_n| (y_0,\cdots,y_{n-1})) \widehat{p}(dx_{n-1}|x_n,(y_0,\cdots,y_{n-1})) \cdots \widehat{p}(dx_k| x_{k+1},(y_0,\cdots,y_k)) f_k(x_k) \\
&=\underbrace{\left[\tfrac{1}{N},\cdots,\tfrac{1}{N}\right]}_{N \text{ times}}\mathbb{M}_{n-1} \cdots\mathbb M_{k} \begin{bmatrix} f_k(\xi^1_k)\\
\vdots\\ f_k(\xi^N_k) \end{bmatrix}
\end{align}](../I/m/08c56e931f733a2765b249bc251ac7a3.png)
where

This also shows that if

then
![\begin{align}
\int \overline{F}(x_0,\cdots,x_n) p(d(x_0,\cdots,x_n)|(y_0,\cdots,y_{n-1})) &\approx_{N\uparrow\infty} \int \overline{F}(x_0,\cdots,x_n) \widehat{p}_{backward}(d(x_0,\cdots,x_n)|(y_0,\cdots,y_{n-1})) \\
&=\frac{1}{n+1} \sum_{k=0}^n \underbrace{\left[\tfrac{1}{N},\cdots,\tfrac{1}{N}\right]}_{N \text{ times}}\mathbb M_{n-1}\mathbb M_{n-2}\cdots\mathbb{M}_k \begin{bmatrix} f_k(\xi^1_k)\\ \vdots\\ f_k(\xi^N_k) \end{bmatrix}
\end{align}](../I/m/ad869a5975913002b8ab72f2d8d05186.png)
Some convergence results
We shall assume that filtering equation is stable, in the sense that it corrects any erroneous initial condition.
In this situation, the particle approximations of the likelihood functions are unbiased and the relative variance is controlled by
![E\left(\widehat{p}(y_0,\cdots,y_n)\right)= p(y_0,\cdots,y_n), \qquad E\left(\left[\frac{\widehat{p}(y_0,\cdots,y_n)}{p(y_0,\cdots,y_n)}-1\right]^2\right)\leqslant \frac{cn}{N},](../I/m/aba762bcce30d2b42faa6974c26d85cd.png)
for some finite constant c. In addition, for any :

for some finite constants related to the asymptotic bias and variance of the particle estimate, and for some finite constant c.
The bias and the variance of the particle particle estimates based on the ancestral lines of the genealogical trees

are controlled by the non asymptotic uniform estimates
![\left| E\left(\widehat{I}^{path}_k(F)\right)-I_k^{path}(F)\right|\leqslant \frac{c_1 k}{N}, \qquad E\left(\left[\widehat{I}^{path}_k(F)-I_k^{path}(F)\right]^2\right)\leqslant \frac{c_2 k}{N},](../I/m/e87f661e963cbe7e3e4ab206026253a1.png)
for any function F bounded by 1, and for some finite constants In addition, for any :

for some finite constants related to the asymptotic bias and variance of the particle estimate, and for some finite constant c. The same type of bias and variance estimates hold for the backward particle smoothers. For additive functionals of the form

with

with functions bounded by 1, we have

and
![E\left(\left[\widehat{I}^{\flat,path}_n(F)-I_n^{path}(F)\right]^2\right)\leqslant \frac{c_2}{nN}+ \frac{c_3}{N^2}](../I/m/bed6a700455df132bd9d2825c778267f.png)
for some finite constants  More refined estimates including exponentially small probability of errors are developed in.[5]
More refined estimates including exponentially small probability of errors are developed in.[5]
Sequential importance sampling (SIS)
The bootstrap filter
Sequential importance sampling (SIS), the original bootstrap filtering algorithm (Gordon et al. 1993), is also a very commonly used filtering algorithm, which approximates the filtering probability density  by a weighted set of N samples
by a weighted set of N samples

The importance weights  are approximations to the relative posterior probabilities (or densities) of the samples such that
are approximations to the relative posterior probabilities (or densities) of the samples such that

SIS is a sequential (i.e., recursive) version of importance sampling. As in importance sampling, the expectation of a function f can be approximated as a weighted average

For a finite set of samples, the algorithm performance is dependent on the choice of the proposal distribution
-
 .
.
The "optimal" proposal distribution is given as the target distribution

This particular choice of proposal transition has been proposed by P. Del Moral in[14] in 1996 and 1998. When it is difficult to sample transitions according to the distribution  one natural strategy is to use the following particle approximation
one natural strategy is to use the following particle approximation

with the empirical approximation

associated with N (or any other large number of samples) independent random samples  with the conditional distribution of the random state given
with the conditional distribution of the random state given  . The consistency of the resulting particle filter of this approximation and other extensions are developed in.[14] In the above display stands for the Dirac measure at a given state a.
. The consistency of the resulting particle filter of this approximation and other extensions are developed in.[14] In the above display stands for the Dirac measure at a given state a.
However, the transition prior probability distribution is often used as importance function, since it is easier to draw particles (or samples) and perform subsequent importance weight calculations:

Sequential Importance Resampling (SIR) filters with transition prior probability distribution as importance function are commonly known as bootstrap filter and condensation algorithm.
Resampling is used to avoid the problem of degeneracy of the algorithm, that is, avoiding the situation that all but one of the importance weights are close to zero. The performance of the algorithm can be also affected by proper choice of resampling method. The stratified sampling proposed by Kitagawa (1996) is optimal in terms of variance.
A single step of sequential importance resampling is as follows:
- 1) For draw samples from the proposal distribution
-

- 2) For update the importance weights up to a normalizing constant:
- Note that when we use the transition prior probability distribution as the importance function,
- this simplifies to the following :



- 3) For compute the normalized importance weights:
-

- 4) Compute an estimate of the effective number of particles as
-
- This criteria reflects the variance of the weights, other criteria can be found in the article,[16] including their rigorous analysis and central limit theorems.

- 5) If the effective number of particles is less than a given threshold
 , then perform resampling:
, then perform resampling:
- a) Draw N particles from the current particle set with probabilities proportional to their weights. Replace the current particle set with this new one.
- b) For set

The term Sampling Importance Resampling is also sometimes used when referring to SIR filters.
Sequential importance sampling (SIS)
- Is the same as sequential importance resampling, but without the resampling stage.
"direct version" algorithm
The "direct version" algorithm is rather simple (compared to other particle filtering algorithms) and it uses composition and rejection. To generate a single sample x at k from  :
:
- 1) Set n=0 (This will count the number of particles generated so far)
- 2) Uniformly choose an index i from the range

- 3) Generate a test
 from the distribution with
from the distribution with 
- 4) Generate the probability of
 using from
using from  where
where  is the measured value
is the measured value
- 5) Generate another uniform u from
![[0, m_k]](../I/m/7bdc57b202e156c251b7dbf9529244bd.png) where
where 
- 6) Compare u and

- 6a) If u is larger then repeat from step 2
- 6b) If u is smaller then save as
 and increment n
and increment n
- 6b) If u is smaller then save
- 7) If n == N then quit
The goal is to generate P "particles" at k using only the particles from  . This requires that a Markov equation can be written (and computed) to generate a
. This requires that a Markov equation can be written (and computed) to generate a 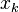 based only upon
based only upon  . This algorithm uses composition of the P particles from to generate a particle at k and repeats (steps 2–6) until P particles are generated at k.
. This algorithm uses composition of the P particles from to generate a particle at k and repeats (steps 2–6) until P particles are generated at k.
This can be more easily visualized if x is viewed as a two-dimensional array. One dimension is k and the other dimensions is the particle number. For example,  would be the ith particle at
would be the ith particle at  and can also be written
and can also be written  (as done above in the algorithm). Step 3 generates a potential based on a randomly chosen particle (
(as done above in the algorithm). Step 3 generates a potential based on a randomly chosen particle ( ) at time and rejects or accepts it in step 6. In other words, the values are generated using the previously generated .
) at time and rejects or accepts it in step 6. In other words, the values are generated using the previously generated .
Other particle filters
- Exponential Natural Particle Filter[60]
- Auxiliary particle filter[61]
- Regularized auxiliary particle filter[62]
- Gaussian particle filter
- Unscented particle filter
- Gauss–Hermite particle filter
- Cost Reference particle filter
- Hierarchical/Scalable particle filter[63]
- Rao–Blackwellized particle filter[47]
- Rejection-sampling based optimal particle filter[64][65]
- Feynman-Kac and mean field particle methodologies[1][5][15]
See also
- Mean field particle methods
- Genetic algorithms
- Ensemble Kalman filter
- Generalized filtering
- Moving horizon estimation
- Recursive Bayesian estimation
- Monte Carlo localization
References
- 1 2 3 4 5 6 7 8 9 10 Del Moral, Pierre (1996). "Non Linear Filtering: Interacting Particle Solution." (PDF). Markov Processes and Related Fields 2 (4): 555–580.
- 1 2 3 Del Moral, Pierre (2004). Feynman-Kac formulae. Genealogical and interacting particle approximations. Springer. p. 575.
Series: Probability and Applications
- 1 2 3 4 5 6 7 8 Del Moral, Pierre; Miclo, Laurent (2000). Branching and Interacting Particle Systems Approximations of Feynman-Kac Formulae with Applications to Non-Linear Filtering. (PDF). Lecture Notes in Mathematics 1729. pp. 1–145. doi:10.1007/bfb0103798.
- 1 2 Del Moral, Pierre; Miclo, Laurent (2000). "A Moran particle system approximation of Feynman-Kac formulae.". Stochastic Processes and their Applications 86 (2): 193–216. doi:10.1016/S0304-4149(99)00094-0.
- 1 2 3 4 5 6 7 8 9 10 11 12 Del Moral, Pierre (2013). Mean field simulation for Monte Carlo integration. Chapman & Hall/CRC Press. p. 626.
Monographs on Statistics & Applied Probability
- ↑ "Particle methods: An introduction with applications". ESAIM: Proc. 44: 1–46. doi:10.1051/proc/201444001.
- 1 2 Rosenbluth, Marshall, N.; Rosenbluth, Arianna, W. (1955). "Monte-Carlo calculations of the average extension of macromolecular chains". J. Chem. Phys 23: 356–359.
- 1 2 3 Hetherington, Jack, H. (1984). "Observations on the statistical iteration of matrices". Phys. Rev. A. 30 (2713): 2713–2719. Bibcode:1984PhRvA..30.2713H. doi:10.1103/PhysRevA.30.2713.
- 1 2 Del Moral, Pierre (2003). "Particle approximations of Lyapunov exponents connected to Schrödinger operators and Feynman-Kac semigroups" (PDF). ESAIM Probability & Statistics 7: 171–208. doi:10.1051/ps:2003001.
- ↑ Assaraf, Roland; Caffarel, Michel; Khelif, Anatole (2000). "Diffusion Monte Carlo Methods with a fixed number of walkers" (PDF). Phys. Rev. E 61: 4566–4575. Bibcode:2000PhRvE..61.4566A. doi:10.1103/physreve.61.4566.
- ↑ Caffarel, Michel; Ceperley, David; Kalos, Malvin (1993). "Comment on Feynman-Kac Path-Integral Calculation of the Ground-State Energies of Atoms". Phys. Rev. Lett. 71: 2159. Bibcode:1993PhRvL..71.2159C. doi:10.1103/physrevlett.71.2159.
- ↑ Ocone, D. L. (January 1, 1999). "Asymptotic stability of beneš filters". Stochastic Analysis and Applications 17 (6): 1053–1074. doi:10.1080/07362999908809648. ISSN 0736-2994.
- ↑ Maurel, Mireille Chaleyat; Michel, Dominique (January 1, 1984). "Des resultats de non existence de filtre de dimension finie". Stochastics 13 (1-2): 83–102. doi:10.1080/17442508408833312. ISSN 0090-9491.
- 1 2 3 4 5 6 7 Del Moral, Pierre (1998). "Measure Valued Processes and Interacting Particle Systems. Application to Non Linear Filtering Problems". Annals of Applied Probability (Publications du Laboratoire de Statistique et Probabilités, 96-15 (1996) ed.) 8 (2): 438–495. doi:10.1214/aoap/1028903535.
- 1 2 3 4 5 6 7 8 9 10 11 12 13 Del Moral, Pierre (2004). Feynman-Kac formulae. Genealogical and interacting particle approximations. http://www.springer.com/gp/book/9780387202686: Springer. Series: Probability and Applications. p. 556. ISBN 978-0-387-20268-6.
- 1 2 3 Del Moral, Pierre; Doucet, Arnaud; Jasra, Ajay (2012). "On Adaptive Resampling Procedures for Sequential Monte Carlo Methods" (PDF). Bernoulli 18 (1): 252–278. doi:10.3150/10-bej335.
- ↑ Turing, Alan M. "Computing machinery and intelligence". Mind LIX (238): 433–460. doi:10.1093/mind/LIX.236.433.
- ↑ Barricelli, Nils Aall (1954). "Esempi numerici di processi di evoluzione". Methodos: 45–68.
- ↑ Barricelli, Nils Aall (1957). "Symbiogenetic evolution processes realized by artificial methods". Methodos: 143–182.
- ↑ "Poor Man's Monte Carlo on JSTOR". www.jstor.org. Retrieved 2015-06-07.
- ↑ Barricelli, Nils Aall (1963). "Numerical testing of evolution theories. Part II. Preliminary tests of performance, symbiogenesis and terrestrial life". Acta Biotheoretica (16): 99–126.
- ↑ "Adaptation in Natural and Artificial Systems | The MIT Press". mitpress.mit.edu. Retrieved 2015-06-06.
- ↑ Fraser, Alex (1957). "Simulation of genetic systems by automatic digital computers. I. Introduction". Aust. J. Biol. Sci. 10: 484–491.
- ↑ Fraser, Alex; Burnell, Donald (1970). Computer Models in Genetics. New York: McGraw-Hill. ISBN 0-07-021904-4.
- ↑ Crosby, Jack L. (1973). Computer Simulation in Genetics. London: John Wiley & Sons. ISBN 0-471-18880-8.
- ↑ Assaraf, Roland; Caffarel, Michel; Khelif, Anatole (2000). "Diffusion Monte Carlo Methods with a fixed number of walkers" (PDF). Phys. Rev. E 61: 4566–4575. Bibcode:2000PhRvE..61.4566A. doi:10.1103/physreve.61.4566.
- ↑ Caffarel, Michel; Ceperley, David; Kalos, Malvin (1993). "Comment on Feynman-Kac Path-Integral Calculation of the Ground-State Energies of Atoms". Phys. Rev. Lett. 71: 2159. Bibcode:1993PhRvL..71.2159C. doi:10.1103/physrevlett.71.2159.
- ↑ Fermi, Enrique; Richtmyer, Robert, D. (1948). "Note on census-taking in Monte Carlo calculations" (PDF). LAM 805 (A).
Declassified report Los Alamos Archive
- ↑ Herman, Kahn; Harris, Theodore, E. (1951). "Estimation of particle transmission by random sampling" (PDF). Natl. Bur. Stand. Appl. Math. Ser. 12: 27–30.
- ↑ Gordon, N.J.; Salmond, D.J.; Smith, A.F.M. (April 1993). "Novel approach to nonlinear/non-Gaussian Bayesian state estimation". Radar and Signal Processing, IEE Proceedings F 140 (2): 107–113. doi:10.1049/ip-f-2.1993.0015. ISSN 0956-375X.
- ↑ Kitagawa, G. (1996). "Monte carlo filter and smoother for non-Gaussian nonlinear state space models". Journal of Computational and Graphical Statistics 5 (1): 1–25. doi:10.2307/1390750. JSTOR 1390750.
- ↑ Carvalho, Himilcon; Del Moral, Pierre; Monin, André; Salut, Gérard (July 1997). "Optimal Non-linear Filtering in GPS/INS Integration." (PDF). IEEE-Trans. on Aerospace and electronic systems 33 (3).
- ↑ P. Del Moral, G. Rigal, and G. Salut. Estimation and nonlinear optimal control : An unified framework for particle solutions
LAAS-CNRS, Toulouse, Research Report no. 91137, DRET-DIGILOG- LAAS/CNRS contract, April (1991). - ↑ P. Del Moral, G. Rigal, and G. Salut. Nonlinear and non Gaussian particle filters applied to inertial platform repositioning.
LAAS-CNRS, Toulouse, Research Report no. 92207, STCAN/DIGILOG-LAAS/CNRS Convention STCAN no. A.91.77.013, (94p.) September (1991). - ↑ P. Del Moral, G. Rigal, and G. Salut. Estimation and nonlinear optimal control : Particle resolution in filtering and estimation. Experimental results.
Convention DRET no. 89.34.553.00.470.75.01, Research report no.2 (54p.), January (1992). - ↑ P. Del Moral, G. Rigal, and G. Salut. Estimation and nonlinear optimal control : Particle resolution in filtering and estimation. Theoretical results
Convention DRET no. 89.34.553.00.470.75.01, Research report no.3 (123p.), October (1992). - ↑ P. Del Moral, J.-Ch. Noyer, G. Rigal, and G. Salut. Particle filters in radar signal processing : detection, estimation and air targets recognition.
LAAS-CNRS, Toulouse, Research report no. 92495, December (1992). - ↑ P. Del Moral, G. Rigal, and G. Salut. Estimation and nonlinear optimal control : Particle resolution in filtering and estimation.
Studies on: Filtering, optimal control, and maximum likelihood estimation. Convention DRET no. 89.34.553.00.470.75.01. Research report no.4 (210p.), January (1993). - 1 2 Crisan, Dan; Gaines, Jessica; Lyons, Terry (1998). "Convergence of a branching particle method to the solution of the Zakai". SIAM Journal on Applied Mathematics 58 (5): 1568–1590. doi:10.1137/s0036139996307371.
- ↑ Crisan, Dan; Lyons, Terry (1997). "Nonlinear filtering and measure-valued processes". Probability Theory and Related Fields 109 (2): 217–244. doi:10.1007/s004400050131.
- ↑ Crisan, Dan; Lyons, Terry (1999). "A particle approximation of the solution of the Kushner–Stratonovitch equation". Probability Theory and Related Fields 115 (4): 549–578. doi:10.1007/s004400050249.
- 1 2 3 Crisan, Dan; Del Moral, Pierre; Lyons, Terry (1999). "Discrete filtering using branching and interacting particle systems" (PDF). Markov Processes and Related Fields 5 (3): 293–318.
- 1 2 3 4 Del Moral, Pierre; Guionnet, Alice (1999). "On the stability of Measure Valued Processes with Applications to filtering". C.R. Acad. Sci. Paris 39 (1): 429–434.
- 1 2 3 4 Del Moral, Pierre; Guionnet, Alice (2001). "On the stability of interacting processes with applications to filtering and genetic algorithms". Annales de l'Institut Henri Poincaré 37 (2): 155–194. Bibcode:2001AnIHP..37..155D. doi:10.1016/s0246-0203(00)01064-5.
- 1 2 Del Moral, P.; Guionnet, A. (1999). "Central limit theorem for nonlinear filtering and interacting particle systems". The Annals of Applied Probability 9 (2): 275–297. doi:10.1214/aoap/1029962742. ISSN 1050-5164.
- 1 2 Del Moral, Pierre; Miclo, Laurent (2001). "Genealogies and Increasing Propagation of Chaos For Feynman-Kac and Genetic Models". The Annals of Applied Probability 11 (4): 1166–1198. doi:10.1214/aoap/1015345399. ISSN 1050-5164.
- 1 2 Doucet, A.; De Freitas, N. and Murphy, K. and Russell, S. (2000). Rao–Blackwellised particle filtering for dynamic Bayesian networks. Proceedings of the Sixteenth conference on Uncertainty in artificial intelligence. pp. 176–183. CiteSeerX: 10
.1 . Cite uses deprecated parameter.1 .137 .5199 |coauthors=(help); - 1 2 Del Moral, Pierre; Miclo, Laurent (2001). "Genealogies and Increasing Propagations of Chaos for Feynman-Kac and Genetic Models". Annals of Applied Probability 11 (4): 1166–1198.
- 1 2 Del Moral, Pierre; Doucet, Arnaud; Singh, Sumeetpal, S. (2010). "A Backward Particle Interpretation of Feynman-Kac Formulae" (PDF). M2AN 44 (5): 947–976. doi:10.1051/m2an/2010048.
- ↑ Vergé, Christelle; Dubarry, Cyrille; Del Moral, Pierre; Moulines, Eric (2013). "On parallel implementation of Sequential Monte Carlo methods: the island particle model". Statistics and Computing 25: 243–260. doi:10.1007/s11222-013-9429-x.
- ↑ Chopin, Nicolas; Jacob, Pierre, E.; Papaspiliopoulos, Omiros. "SMC^2: an efficient algorithm for sequential analysis of state-space models". arXiv:1101.1528v3.
- ↑ Andrieu, Christophe; Doucet, Arnaud; Holenstein, Roman (2010). "Particle Markov chain Monte Carlo methods". Journal Royal Statistical Society B 72 (3): 269–342. doi:10.1111/j.1467-9868.2009.00736.x.
- ↑ Del Moral, Pierre; Patras, Frédéric; Kohn, Robert (2014). "On Feynman-Kac and particle Markov chain Monte Carlo models". arXiv:1404.5733.
- ↑ Singer, R.A. (July 1970). "Estimating Optimal Tracking Filter Performance for Manned Maneuvering Targets". IEEE Transactions on Aerospace and Electronic Systems. AES-6 (4): 473–483. doi:10.1109/TAES.1970.310128. ISSN 0018-9251.
- ↑ Del Moral, Pierre; Jacod, Jean; Protter, Philip (2001-07-01). "The Monte-Carlo method for filtering with discrete-time observations". Probability Theory and Related Fields 120 (3): 346–368. doi:10.1007/PL00008786. ISSN 0178-8051.
- ↑ Del Moral, Pierre; Doucet, Arnaud; Jasra, Ajay (2011). "An adaptive sequential Monte Carlo method for approximate Bayesian computation". Statistics and Computing 22 (5): 1009–1020. doi:10.1007/s11222-011-9271-y. ISSN 0960-3174.
- ↑ Martin, James S.; Jasra, Ajay; Singh, Sumeetpal S.; Whiteley, Nick; Del Moral, Pierre; McCoy, Emma (May 4, 2014). "Approximate Bayesian Computation for Smoothing". Stochastic Analysis and Applications 32 (3): 397–420. doi:10.1080/07362994.2013.879262. ISSN 0736-2994.
- ↑ Del Moral, Pierre; Rio, Emmanuel (2011). "Concentration inequalities for mean field particle models". The Annals of Applied Probability 21 (3): 1017–1052. doi:10.1214/10-AAP716. ISSN 1050-5164.
- ↑ Del Moral, Pierre; Hu, Peng; Wu, Liming (2012). On the Concentration Properties of Interacting Particle Processes. Hanover, MA, USA: Now Publishers Inc. ISBN 1601985126.
- ↑ Zand, G.; Taherkhani, M.; Safabakhsh, R. (2015). "Exponential Natural Particle Filter". arXiv:1511.06603.
- ↑ Pitt, M.K.; Shephard, N. (1999). "Filtering Via Simulation: Auxiliary Particle Filters". Journal of the American Statistical Association (American Statistical Association) 94 (446): 590–591. doi:10.2307/2670179. JSTOR 2670179. Retrieved 2008-05-06.
- ↑ Liu, J.; Wang, W.; Ma, F. (2011). "A Regularized Auxiliary Particle Filtering Approach for System State Estimation and Battery Life Prediction". Smart Materials and Structures 20 (7): 1–9. doi:10.1088/0964-1726/20/7/075021.
- ↑ Canton-Ferrer, C.; Casas, J.R.; Pardàs, M. (2011). "Human Motion Capture Using Scalable Body Models". Computer Vision and Image Understanding (Elsevier) 115 (10): 1363–1374. doi:10.1016/j.cviu.2011.06.001.
- ↑ Blanco, J.L.; Gonzalez, J.; Fernandez-Madrigal, J.A. (2008). An Optimal Filtering Algorithm for Non-Parametric Observation Models in Robot Localization. IEEE International Conference on Robotics and Automation (ICRA'08). pp. 461–466. CiteSeerX: 10
.1 ..1 .190 .7092 - ↑ Blanco, J.L.; Gonzalez, J.; Fernandez-Madrigal, J.A. (2010). "Optimal Filtering for Non-Parametric Observation Models: Applications to Localization and SLAM" (PDF). The International Journal of Robotics Research (IJRR) 29 (14): 1726–1742. doi:10.1177/0278364910364165.
Bibliography
- Del Moral, Pierre (1996). "Non Linear Filtering: Interacting Particle Solution" (PDF). Markov Processes and Related Fields 2 (4): 555–580.
- Del Moral, Pierre (2004). Feynman-Kac formulae. Genealogical and interacting particle approximations. Springer. p. 575.
Series: Probability and Applications
- Del Moral, Pierre (2013). Mean field simulation for Monte Carlo integration. Chapman & Hall/CRC Press. p. 626.
Monographs on Statistics & Applied Probability
- Cappe, O.; Moulines, E.; Ryden, T. (2005). Inference in Hidden Markov Models. Springer.
- Liu, J.S.,; Chen, R. (1998). "Sequential Monte Carlo methods for dynamic systems" (PDF). Journal of the American Statistical Association (Taylor & Francis Group) 93 (443): 1032–1044. doi:10.1080/01621459.1998.10473765.
- Liu, J.S. (2001). Monte Carlo strategies in Scientific Computing. Springer.
- Kong, A.; Liu, J.S.; Wong, W.H. (1994). "Sequential imputations and Bayesian missing data problems" (PDF). Journal of the American Statistical Association (Taylor & Francis Group) 89 (425): 278–288. doi:10.1080/01621459.1994.10476469.
- Liu, J.S.; Chen, R. (1995). "Blind deconvolution via sequential imputations" (PDF). Journal of the American Statistical Association (Taylor & Francis Group) 90 (430): 567–576. doi:10.2307/2291068.
- Ristic, B.; Arulampalam, S.; Gordon, N. (2004). Beyond the Kalman Filter: Particle Filters for Tracking Applications. Artech House.
- Doucet, A.; Johansen, A.M. (December 2008). "A tutorial on particle filtering and smoothing: fifteen years later" (PDF). Technical report (Department of Statistics, University of British Columbia).
- Doucet, A.; Godsill, S.; Andrieu, C. (2000). "On sequential Monte Carlo sampling methods for Bayesian filtering". Statistics and Computing 10 (3): 197–208. doi:10.1023/A:1008935410038.
- Arulampalam, M.S.; Maskell, S.; Gordon, N.; Clapp, T. (2002). "A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking". IEEE Transactions on Signal Processing 50 (2): 174–188. doi:10.1109/78.978374.
- Cappe, O.; Godsill, S.; Moulines, E. (2007). "An overview of existing methods and recent advances in sequential Monte Carlo". Proceedings of IEEE 95 (5): 899–924. doi:10.1109/JPROC.2007.893250.
- Kitagawa, G. (1996). "Monte carlo filter and smoother for non-Gaussian nonlinear state space models". Journal of Computational and Graphical Statistics 5 (1): 1–25. doi:10.2307/1390750. JSTOR 1390750.
- Kotecha, J.H.; Djuric, P. (2003). "Gaussian Particle filtering". IEEE Transactions Signal Processing 51 (10).
- Haug, A.J. (2005). "A Tutorial on Bayesian Estimation and Tracking Techniques Applicable to Nonlinear and Non-Gaussian Processes" (PDF). The MITRE Corporation, USA, Tech. Rep., Feb. Retrieved 2008-05-06.
- Pitt, M.K.; Shephard, N. (1999). "Filtering Via Simulation: Auxiliary Particle Filters". Journal of the American Statistical Association (Journal of the American Statistical Association, Vol. 94, No. 446) 94 (446): 590–591. doi:10.2307/2670179. JSTOR 2670179. Retrieved 2008-05-06.
- Gordon, N. J.; Salmond, D. J.; Smith, A. F. M. (1993). "Novel approach to nonlinear/non-Gaussian Bayesian state estimation". IEE Proceedings F on Radar and Signal Processing 140 (2): 107–113. doi:10.1049/ip-f-2.1993.0015. Retrieved 2009-09-19.
- Chen, Z. (2003). "Bayesian Filtering: From Kalman Filters to Particle Filters, and Beyond". CiteSeerX: 10
.1 ..1 .107 .7415
- Vaswani, N.; Rathi, Y. Yezzi, A., Tannenbaum, A. (2007). "Tracking deforming objects using particle filtering for geometric active contours". IEEE Trans. on Pattern Analysis and Machine Intelligence 29 (8): 1470–1475. doi:10.1109/tpami.2007.1081. Cite uses deprecated parameter
|coauthors=(help)
External links
- Feynman–Kac models and interacting particle algorithms (a.k.a. Particle Filtering) Theoretical aspects and a list of application domains of particle filters
- Sequential Monte Carlo Methods (Particle Filtering) homepage on University of Cambridge
- Dieter Fox's MCL Animations
- Rob Hess' free software
- SMCTC: A Template Class for Implementing SMC algorithms in C++
- Java applet on particle filtering
- vSMC : Vectorized Sequential Monte Carlo
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||