Score (statistics)
In statistics, the score, score function, efficient score[1] or informant[2] indicates how sensitively a likelihood function 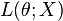 depends on its parameter
depends on its parameter  . Explicitly, the score for is the gradient of the log-likelihood with respect to .
. Explicitly, the score for is the gradient of the log-likelihood with respect to .
The score plays an important role in several aspects of inference. For example:
- in formulating a test statistic for a locally most powerful test;[3]
- in approximating the error in a maximum likelihood estimate;[4]
- in demonstrating the asymptotic sufficiency of a maximum likelihood estimate;[4]
- in the formulation of confidence intervals;[5]
- in demonstrations of the Cramér–Rao inequality.[6]
The score function also plays an important role in computational statistics, as it can play a part in the computation of maximum likelihood estimates.
Definition
The score or efficient score [1] is the gradient (the vector of partial derivatives), with respect to some parameter , of the logarithm (commonly the natural logarithm) of the likelihood function (the log-likelihood).
If the observation is 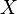 and its likelihood is , then the score
and its likelihood is , then the score 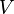 can be found through the chain rule:
can be found through the chain rule:
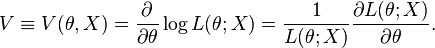
Thus the score indicates the sensitivity of (its derivative normalized by its value). Note that is a function of and the observation , so that, in general, it is not a statistic. However in certain applications, such as the score test, the score is evaluated at a specific value of (such as a null-hypothesis value, or at the maximum likelihood estimate of ), in which case the result is a statistic.
In older literature, the term "linear score" may be used to refer to the score with respect to infinitesimal translation of a given density. This convention arises from a time when the primary parameter of interest was the mean or median of a distribution. In this case, the likelihood of an observation is given by a density of the form 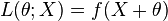 . The "linear score" is then defined as
. The "linear score" is then defined as
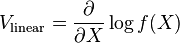
Properties
Mean
Under some regularity conditions, the expected value of with respect to the observation  , given , written
, given , written 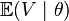 , is zero.
To see this rewrite the likelihood function L as a probability density function
, is zero.
To see this rewrite the likelihood function L as a probability density function 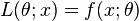 . Then:
. Then:
![\begin{align}
\mathbb{E}(V\mid\theta)
& =\int_{-\infty}^{+\infty}
f(x; \theta) \frac{\partial}{\partial\theta} \log L(\theta;X)
\,dx
=\int_{-\infty}^{+\infty}
\frac{\partial}{\partial\theta} \log L(\theta;X) f(x; \theta) \, dx \\[6pt]
& = \int_{-\infty}^{+\infty}
\frac{1}{f(x; \theta)}\frac{\partial f(x; \theta)}{\partial \theta}f(x; \theta)\, dx
=\int_{-\infty}^{+\infty} \frac{\partial f(x; \theta)}{\partial \theta} \, dx
\end{align}](../I/m/6ecbf8161e62854f6c6cf4d3829d90f3.png)
If certain differentiability conditions are met (see Leibniz integral rule), the integral may be rewritten as

It is worth restating the above result in words: the expected value of the score is zero. Thus, if one were to repeatedly sample from some distribution, and repeatedly calculate the score, then the mean value of the scores would tend to zero as the number of repeat samples approached infinity.
Variance
The variance of the score is known as the Fisher information and is written  . Because the expectation of the score is zero, this may be written as
. Because the expectation of the score is zero, this may be written as
![\mathcal{I}(\theta)
=
\mathbb{E}
\left\{\left.
\left[
\frac{\partial}{\partial\theta} \log L(\theta;X)
\right]^2
\right|\theta\right\}.](../I/m/6bcb6c7b6985d43301bc22a3437899ac.png)
Note that the Fisher information, as defined above, is not a function of any particular observation, as the random variable has been averaged out.
This concept of information is useful when comparing two methods of observation of some random process.
Examples
Bernoulli process
Consider a Bernoulli process, with A successes and B failures; the probability of success is θ.
Then the likelihood L is
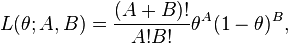
so the score V is

We can now verify that the expectation of the score is zero. Noting that the expectation of A is nθ and the expectation of B is n(1 − θ) [recall that A and B are random variables], we can see that the expectation of V is
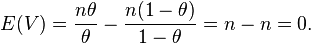
We can also check the variance of . We know that A + B = n (so B = n − A) and the variance of A is nθ(1 − θ) so the variance of V is
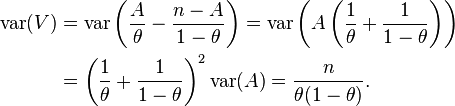
Binary outcome model
For models with binary outcomes (Y = 1 or 0), the model can be scored with the logarithm of predictions
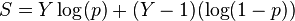
where p is the probability in the model to be estimated and S is the score.[7]
Applications
Scoring algorithm
The scoring algorithm is an iterative method for numerically determining the maximum likelihood estimator.
Score test
See also
Notes
- 1 2 Cox & Hinkley (1974), p 107
- ↑ Chentsov, N.N. (2001), "Informant", in Hazewinkel, Michiel, Encyclopedia of Mathematics, Springer, ISBN 978-1-55608-010-4
- ↑ Cox & Hinkley (1974), p 113
- 1 2 Cox & Hinkley (1974), p 295
- ↑ Cox & Hinkley (1974), p 222–3
- ↑ Cox & Hinkley (1974), p 254
- ↑ Steyerberg, E. W.; Vickers, A. J.; Cook, N. R.; Gerds, T.; Gonen, M.; Obuchowski, N.; Pencina, M. J.; Kattan, M. W. (2010). "Assessing the performance of prediction models. A framework for traditional and novel measures". Epidemiology 21 (1): 128–138. doi:10.1097/EDE.0b013e3181c30fb2.
References
- Cox, D. R.; Hinkley, D. V. (1974). Theoretical Statistics. Chapman & Hall. ISBN 0-412-12420-3.
- Schervish, Mark J. (1995). Theory of Statistics. New York: Springer. Section 2.3.1. ISBN 0-387-94546-6.