Power law

In statistics, a power law is a functional relationship between two quantities, where a relative change in one quantity results in a proportional relative change in the other quantity, independent of the initial size of those quantities: one quantity varies as a power of another. For instance, considering the area of a square in terms of the length of its side, if the length is doubled, the area is multiplied by a factor of four.[1]
Empirical examples of power laws
The distributions of a wide variety of physical, biological, and man-made phenomena approximately follow a power law over a wide range of magnitudes: these include the sizes of earthquakes, craters on the moon and of solar flares,[2] the foraging pattern of various species,[3] the sizes of activity patterns of neuronal populations,[4] the frequencies of words in most languages, frequencies of family names, the species richness in clades of organisms,[5] the sizes of power outages, criminal charges per convict, and many other quantities.[6] Few empirical distributions fit a power law for all their values, but rather follow a power law in the tail. Acoustic attenuation follows frequency power-laws within wide frequency bands for many complex media. Allometric scaling laws for relationships between biological variables are among the best known power-law functions in nature.
Properties of power laws
Scale invariance
One attribute of power laws is their scale invariance. Given a relation 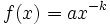 , scaling the argument
, scaling the argument  by a constant factor
by a constant factor  causes only a proportionate scaling of the function itself. That is,
causes only a proportionate scaling of the function itself. That is,
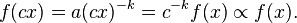
That is, scaling by a constant simply multiplies the original power-law relation by the constant 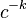 . Thus, it follows that all power laws with a particular scaling exponent are equivalent up to constant factors, since each is simply a scaled version of the others. This behavior is what produces the linear relationship when logarithms are taken of both
. Thus, it follows that all power laws with a particular scaling exponent are equivalent up to constant factors, since each is simply a scaled version of the others. This behavior is what produces the linear relationship when logarithms are taken of both 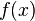 and , and the straight-line on the log-log plot is often called the signature of a power law. With real data, such straightness is a necessary, but not sufficient, condition for the data following a power-law relation. In fact, there are many ways to generate finite amounts of data that mimic this signature behavior, but, in their asymptotic limit, are not true power laws (e.g., if the generating process of some data follows a Log-normal distribution). Thus, accurately fitting and validating power-law models is an active area of research in statistics; see below.
and , and the straight-line on the log-log plot is often called the signature of a power law. With real data, such straightness is a necessary, but not sufficient, condition for the data following a power-law relation. In fact, there are many ways to generate finite amounts of data that mimic this signature behavior, but, in their asymptotic limit, are not true power laws (e.g., if the generating process of some data follows a Log-normal distribution). Thus, accurately fitting and validating power-law models is an active area of research in statistics; see below.
Lack of well-defined average value
A power-law 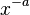 has a well-defined mean over
has a well-defined mean over ![x \in [1,\infty]](../I/m/ab19523b7a3ae7174981278341f55414.png) only if
only if 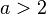 , and it has a finite variance only if
, and it has a finite variance only if 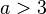 ; most identified power laws in nature have exponents such that the mean is well-defined but the variance is not, implying they are capable of black swan behavior.[7] This can be seen in the following thought experiment:[8] imagine a room with your friends and estimate the average monthly income in the room. Now imagine the world's richest person entering the room, with a monthly income of about 1 billion US$. What happens to the average income in the room? Income is distributed according to a power-law known as the Pareto distribution (for example, the net worth of Americans is distributed according to a power law with an exponent of 2).
; most identified power laws in nature have exponents such that the mean is well-defined but the variance is not, implying they are capable of black swan behavior.[7] This can be seen in the following thought experiment:[8] imagine a room with your friends and estimate the average monthly income in the room. Now imagine the world's richest person entering the room, with a monthly income of about 1 billion US$. What happens to the average income in the room? Income is distributed according to a power-law known as the Pareto distribution (for example, the net worth of Americans is distributed according to a power law with an exponent of 2).
On the one hand, this makes it incorrect to apply traditional statistics that are based on variance and standard deviation (such as regression analysis). On the other hand, this also allows for cost-efficient interventions.[8] For example, given that car exhaust is distributed according to a power-law among cars (very few cars contribute to most contamination) it would be sufficient to eliminate those very few cars from the road to reduce total exhaust substantially.[9]
The median does exist, however: for a power law x-a, with exponent a > 1, it takes the value 21/(a - 1)xmin, where xmin is the minimum value for which the power law holds[10]
Universality
The equivalence of power laws with a particular scaling exponent can have a deeper origin in the dynamical processes that generate the power-law relation. In physics, for example, phase transitions in thermodynamic systems are associated with the emergence of power-law distributions of certain quantities, whose exponents are referred to as the critical exponents of the system. Diverse systems with the same critical exponents—that is, which display identical scaling behaviour as they approach criticality—can be shown, via renormalization group theory, to share the same fundamental dynamics. For instance, the behavior of water and CO2 at their boiling points fall in the same universality class because they have identical critical exponents. In fact, almost all material phase transitions are described by a small set of universality classes. Similar observations have been made, though not as comprehensively, for various self-organized critical systems, where the critical point of the system is an attractor. Formally, this sharing of dynamics is referred to as universality, and systems with precisely the same critical exponents are said to belong to the same universality class.
Power-law functions
Scientific interest in power-law relations stems partly from the ease with which certain general classes of mechanisms generate them.[11] The demonstration of a power-law relation in some data can point to specific kinds of mechanisms that might underlie the natural phenomenon in question, and can indicate a deep connection with other, seemingly unrelated systems;[12] see also universality above. The ubiquity of power-law relations in physics is partly due to dimensional constraints, while in complex systems, power laws are often thought to be signatures of hierarchy or of specific stochastic processes. A few notable examples of power laws are the Gutenberg–Richter law for earthquake sizes, Pareto's law of income distribution, structural self-similarity of fractals, and scaling laws in biological systems. Research on the origins of power-law relations, and efforts to observe and validate them in the real world, is an active topic of research in many fields of science, including physics, computer science, linguistics, geophysics, neuroscience, sociology, economics and more.
However much of the recent interest in power laws comes from the study of probability distributions: The distributions of a wide variety of quantities seem to follow the power-law form, at least in their upper tail (large events). The behavior of these large events connects these quantities to the study of theory of large deviations (also called extreme value theory), which considers the frequency of extremely rare events like stock market crashes and large natural disasters. It is primarily in the study of statistical distributions that the name "power law" is used; in other areas, such as physics and engineering, a power-law functional form with a single term and a positive integer exponent is typically regarded as a polynomial function.
In empirical contexts, an approximation to a power-law 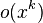 often includes a deviation term
often includes a deviation term  , which can represent uncertainty in the observed values (perhaps measurement or sampling errors) or provide a simple way for observations to deviate from the power-law function (perhaps for stochastic reasons):
, which can represent uncertainty in the observed values (perhaps measurement or sampling errors) or provide a simple way for observations to deviate from the power-law function (perhaps for stochastic reasons):
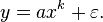
Mathematically, a strict power law cannot be a probability distribution, but a distribution that is a truncated power function is possible: 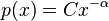 for
for  where the exponent
where the exponent  is greater than 1 (otherwise the tail has infinite area), the minimum value
is greater than 1 (otherwise the tail has infinite area), the minimum value  is needed otherwise the distribution has infinite area as x approaches 0, and the constant C is a scaling factor to ensure that the total area is 1, as required by a probability distribution. More often one uses an asymptotic power law – one that is only true in the limit; see power-law probability distributions below for details. Typically the exponent falls in the range
is needed otherwise the distribution has infinite area as x approaches 0, and the constant C is a scaling factor to ensure that the total area is 1, as required by a probability distribution. More often one uses an asymptotic power law – one that is only true in the limit; see power-law probability distributions below for details. Typically the exponent falls in the range 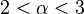 , though not always.[6]
, though not always.[6]
Examples of power-law functions
More than a hundred power-law distributions have been identified in physics (e.g. sandpile avalanches and earthquakes), biology (e.g. species extinction and body mass), and the social sciences (e.g. city sizes and income).[13] Among them are:
- The frequency-dependency of acoustic attenuation in complex media
- The Stevens' power law of psychophysics
- The Stefan–Boltzmann law
- The input-voltage–output-current curves of field-effect transistors and vacuum tubes approximate a square-law relationship, a factor in "tube sound".
- Square-cube law (ratio of surface area to volume)
- Kleiber's law relating animal metabolism to size, and allometric laws in general
- A 3/2-power law can be found in the plate characteristic curves of triodes.
- The inverse-square laws of Newtonian gravity and electrostatics, as evidenced by the gravitational potential and Electrostatic potential, respectively.
- Self-organized criticality with a critical point as an attractor
- Exponential growth and random observation (or killing)[14]
- Progress through exponential growth and exponential diffusion of innovations[15]
- Highly optimized tolerance
- Model of van der Waals force
- Force and potential in simple harmonic motion
- Kepler's third law
- The initial mass function of stars
- The M-sigma relation
- Gamma correction relating light intensity with voltage
- The two-thirds power law, relating speed to curvature in the human motor system.
- The Taylor's law relating mean population size and variance of populations sizes in ecology
- Behaviour near second-order phase transitions involving critical exponents
- Proposed form of experience curve effects
- The differential energy spectrum of cosmic-ray nuclei
- Fractals
- Pareto distribution and the Pareto principle also called the "80–20 rule"
- Zipf's law in corpus analysis and population distributions amongst others, where frequency of an item or event is inversely proportional to its frequency rank (i.e. the second most frequent item/event occurs half as often the most frequent item, the third most frequent item/event occurs one third as often as the most frequent item, and so on).
- The safe operating area relating to maximum simultaneous current and voltage in power semiconductors.
- Supercritical state of matter and supercritical fluids, such as supercritical exponents of heat capacity and viscosity.[16]
- Zeta distribution (discrete)
- Yule–Simon distribution (discrete)
- Student's t-distribution (continuous), of which the Cauchy distribution is a special case
- Lotka's law
- The scale-free network model
- Pink noise
- Neuronal avalanches[4]
- The law of stream numbers, and the law of stream lengths (Horton's laws describing river systems)
- Populations of cities (Gibrat's law)
- Bibliograms, and frequencies of words in a text (Zipf's law)
- 90–9–1 principle on wikis (also referred to as the 1% Rule)
- Richardson's Law for the severity of violent conflicts (wars and terrorism){Lewis Fry Richardson, The Statistics of Deadly Quarrels, 1950}
- Gutenberg–Richter law of earthquake magnitudes
Variants
Broken power law
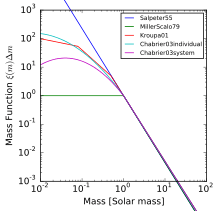
A broken power law is a piecewise function, consisting of two or more power laws, combined with a threshold. For example, with two power laws:[17]
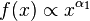 for
for 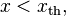
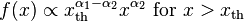 .
.
Power law with exponential cutoff
A power law with an exponential cutoff is simply a power law multiplied by an exponential function:[18]
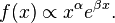
Curved power law
Power-law probability distributions
In a looser sense, a power-law probability distribution is a distribution whose density function (or mass function in the discrete case) has the form
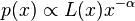
where  , and
, and 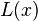 is a slowly varying function, which is any function that satisfies
is a slowly varying function, which is any function that satisfies 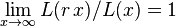 for any positive factor
for any positive factor  . This property of follows directly from the requirement that
. This property of follows directly from the requirement that 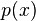 be asymptotically scale invariant; thus, the form of only controls the shape and finite extent of the lower tail. For instance, if is the constant function, then we have a power law that holds for all values of . In many cases, it is convenient to assume a lower bound
be asymptotically scale invariant; thus, the form of only controls the shape and finite extent of the lower tail. For instance, if is the constant function, then we have a power law that holds for all values of . In many cases, it is convenient to assume a lower bound 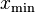 from which the law holds. Combining these two cases, and where is a continuous variable, the power law has the form
from which the law holds. Combining these two cases, and where is a continuous variable, the power law has the form
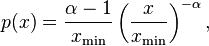
where the pre-factor to 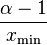 is the normalizing constant. We can now consider several properties of this distribution. For instance, its moments are given by
is the normalizing constant. We can now consider several properties of this distribution. For instance, its moments are given by
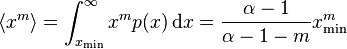
which is only well defined for 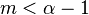 . That is, all moments
. That is, all moments 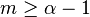 diverge: when
diverge: when  , the average and all higher-order moments are infinite; when , the mean exists, but the variance and higher-order moments are infinite, etc. For finite-size samples drawn from such distribution, this behavior implies that the central moment estimators (like the mean and the variance) for diverging moments will never converge – as more data is accumulated, they continue to grow. These power-law probability distributions are also called Pareto-type distributions, distributions with Pareto tails, or distributions with regularly varying tails.
, the average and all higher-order moments are infinite; when , the mean exists, but the variance and higher-order moments are infinite, etc. For finite-size samples drawn from such distribution, this behavior implies that the central moment estimators (like the mean and the variance) for diverging moments will never converge – as more data is accumulated, they continue to grow. These power-law probability distributions are also called Pareto-type distributions, distributions with Pareto tails, or distributions with regularly varying tails.
Another kind of power-law distribution, which does not satisfy the general form above, is the power law with an exponential cutoff
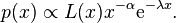
In this distribution, the exponential decay term 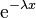 eventually overwhelms the power-law behavior at very large values of . This distribution does not scale and is thus not asymptotically a power law; however, it does approximately scale over a finite region before the cutoff. (Note that the pure form above is a subset of this family, with
eventually overwhelms the power-law behavior at very large values of . This distribution does not scale and is thus not asymptotically a power law; however, it does approximately scale over a finite region before the cutoff. (Note that the pure form above is a subset of this family, with 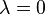 .) This distribution is a common alternative to the asymptotic power-law distribution because it naturally captures finite-size effects. For instance, although the Gutenberg–Richter law is commonly cited as an example of a power-law distribution, the distribution of earthquake magnitudes cannot scale as a power law in the limit
.) This distribution is a common alternative to the asymptotic power-law distribution because it naturally captures finite-size effects. For instance, although the Gutenberg–Richter law is commonly cited as an example of a power-law distribution, the distribution of earthquake magnitudes cannot scale as a power law in the limit 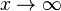 because there is a finite amount of energy in the Earth's crust and thus there must be some maximum size to an earthquake. As the scaling behavior approaches this size, it must taper off.
because there is a finite amount of energy in the Earth's crust and thus there must be some maximum size to an earthquake. As the scaling behavior approaches this size, it must taper off.
The Tweedie distributions are a family of statistical models characterized by closure under additive and reproductive convolution as well as under scale transformation. Consequently these models all express a power-law relationship between the variance and the mean. These models have a fundamental role as foci of mathematical convergence similar to the role that the normal distribution has as a focus in the central limit theorem. This convergence effect explains why the variance-to-mean power law manifests so widely in natural processes, as with Taylor's law in ecology and with fluctuation scaling[20] in physics. It can also be shown that this variance-to-mean power law, when demonstrated by the method of expanding bins, implies the presence of 1/f noise and that 1/f noise can arise as a consequence of this Tweedie convergence effect.[21]
Graphical methods for identification
Although more sophisticated and robust methods have been proposed, the most frequently used graphical methods of identifying power-law probability distributions using random samples are Pareto quantile-quantile plots (or Pareto Q-Q plots), mean residual life plots[22][23] and log-log plots. Another, more robust graphical method uses bundles of residual quantile functions.[24] (Please keep in mind that power-law distributions are also called Pareto-type distributions.) It is assumed here that a random sample is obtained from a probability distribution, and that we want to know if the tail of the distribution follows a power law (in other words, we want to know if the distribution has a "Pareto tail"). Here, the random sample is called "the data".
Pareto Q-Q plots compare the quantiles of the log-transformed data to the corresponding quantiles of an exponential distribution with mean 1 (or to the quantiles of a standard Pareto distribution) by plotting the former versus the latter. If the resultant scatterplot suggests that the plotted points " asymptotically converge" to a straight line, then a power-law distribution should be suspected. A limitation of Pareto Q-Q plots is that they behave poorly when the tail index (also called Pareto index) is close to 0, because Pareto Q-Q plots are not designed to identify distributions with slowly varying tails.[24]
On the other hand, in its version for identifying power-law probability distributions, the mean residual life plot consists of first log-transforming the data, and then plotting the average of those log-transformed data that are higher than the i-th order statistic versus the i-th order statistic, for i = 1, ..., n, where n is the size of the random sample. If the resultant scatterplot suggests that the plotted points tend to "stabilize" about a horizontal straight line, then a power-law distribution should be suspected. Since the mean residual life plot is very sensitive to outliers (it is not robust), it usually produces plots that are difficult to interpret; for this reason, such plots are usually called Hill horror plots [25]
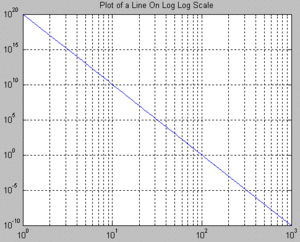
Log-log plots are an alternative way of graphically examining the tail of a distribution using a random sample. This method consists of plotting the logarithm of an estimator of the probability that a particular number of the distribution occurs versus the logarithm of that particular number. Usually, this estimator is the proportion of times that the number occurs in the data set. If the points in the plot tend to "converge" to a straight line for large numbers in the x axis, then the researcher concludes that the distribution has a power-law tail. Examples of the application of these types of plot have been published.[26] A disadvantage of these plots is that, in order for them to provide reliable results, they require huge amounts of data. In addition, they are appropriate only for discrete (or grouped) data.
Another graphical method for the identification of power-law probability distributions using random samples has been proposed.[24] This methodology consists of plotting a bundle for the log-transformed sample. Originally proposed as a tool to explore the existence of moments and the moment generation function using random samples, the bundle methodology is based on residual quantile functions (RQFs), also called residual percentile functions,[27][28][29][30][31][32][33] which provide a full characterization of the tail behavior of many well-known probability distributions, including power-law distributions, distributions with other types of heavy tails, and even non-heavy-tailed distributions. Bundle plots do not have the disadvantages of Pareto Q-Q plots, mean residual life plots and log-log plots mentioned above (they are robust to outliers, allow visually identifying power laws with small values of , and do not demand the collection of much data). In addition, other types of tail behavior can be identified using bundle plots.
Plotting power-law distributions
In general, power-law distributions are plotted on doubly logarithmic axes, which emphasizes the upper tail region. The most convenient way to do this is via the (complementary) cumulative distribution (cdf), 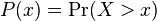 ,
,
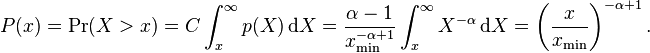
Note that the cdf is also a power-law function, but with a smaller scaling exponent. For data, an equivalent form of the cdf is the rank-frequency approach, in which we first sort the  observed values in ascending order, and plot them against the vector
observed values in ascending order, and plot them against the vector ![\left[1,\frac{n-1}{n},\frac{n-2}{n},\dots,\frac{1}{n}\right]](../I/m/bc687c349e1bc9bd909b7e3a33a4aa33.png) .
.
Although it can be convenient to log-bin the data, or otherwise smooth the probability density (mass) function directly, these methods introduce an implicit bias in the representation of the data, and thus should be avoided. The cdf, on the other hand, introduces no bias in the data and preserves the linear signature on doubly logarithmic axes.
Estimating the exponent from empirical data
There are many ways of estimating the value of the scaling exponent for a power-law tail, however not all of them yield unbiased and consistent answers. Some of the most reliable techniques are often based on the method of maximum likelihood. Alternative methods are often based on making a linear regression on either the log-log probability, the log-log cumulative distribution function, or on log-binned data, but these approaches should be avoided as they can all lead to highly biased estimates of the scaling exponent.[6]
Maximum likelihood
For real-valued, independent and identically distributed data, we fit a power-law distribution of the form
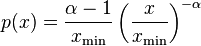
to the data 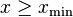 , where the coefficient is included to ensure that the distribution is normalized. Given a choice for
, where the coefficient is included to ensure that the distribution is normalized. Given a choice for 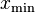 , the log likelihood function becomes:
, the log likelihood function becomes:
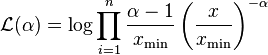
The maximum of this likelihood is found by differentiating with respect to parameter , setting the result equal to zero. Upon rearrangement, this yields the estimator equation:
![\hat{\alpha} = 1 + n \left[ \sum_{i=1}^n \ln \frac{x_i}{x_\min} \right]^{-1}](../I/m/fe09ec9f979040234cd0535462e8a9d2.png)
where  are the data points
are the data points 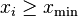 .[2][34] This estimator exhibits a small finite sample-size bias of order
.[2][34] This estimator exhibits a small finite sample-size bias of order 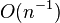 , which is small when n > 100. Further, the standard error of the estimate is
, which is small when n > 100. Further, the standard error of the estimate is 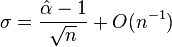 . This estimator is equivalent to the popular Hill estimator from quantitative finance and extreme value theory.
. This estimator is equivalent to the popular Hill estimator from quantitative finance and extreme value theory.
For a set of n integer-valued data points , again where each 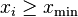 , the maximum likelihood exponent is the solution to the transcendental equation
, the maximum likelihood exponent is the solution to the transcendental equation
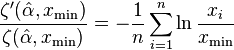
where 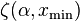 is the incomplete zeta function. The uncertainty in this estimate follows the same formula as for the continuous equation. However, the two equations for
is the incomplete zeta function. The uncertainty in this estimate follows the same formula as for the continuous equation. However, the two equations for 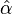 are not equivalent, and the continuous version should not be applied to discrete data, nor vice versa.
are not equivalent, and the continuous version should not be applied to discrete data, nor vice versa.
Further, both of these estimators require the choice of . For functions with a non-trivial function, choosing too small produces a significant bias in 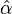 , while choosing it too large increases the uncertainty in , and reduces the statistical power of our model. In general, the best choice of depends strongly on the particular form of the lower tail, represented by above.
, while choosing it too large increases the uncertainty in , and reduces the statistical power of our model. In general, the best choice of depends strongly on the particular form of the lower tail, represented by above.
More about these methods, and the conditions under which they can be used, can be found in .[6] Further, this comprehensive review article provides usable code (Matlab, R and C++) for estimation and testing routines for power-law distributions.
Kolmogorov–Smirnov estimation
Another method for the estimation of the power-law exponent, which does not assume independent and identically distributed (iid) data, uses the minimization of the Kolmogorov–Smirnov statistic,  , between the cumulative distribution functions of the data and the power law:
, between the cumulative distribution functions of the data and the power law:
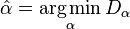
with
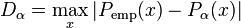
where 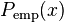 and
and 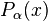 denote the cdfs of the data and the power law with exponent , respectively. As this method does not assume iid data, it provides an alternative way to determine the power-law exponent for data sets in which the temporal correlation can not be ignored.[4]
denote the cdfs of the data and the power law with exponent , respectively. As this method does not assume iid data, it provides an alternative way to determine the power-law exponent for data sets in which the temporal correlation can not be ignored.[4]
Two-point fitting method
This criterion can be applied for the estimation of power-law exponent in the case of scale free distributions and provides a more convergent estimate than the maximum likelihood method.[35] It has been applied to study probability distributions of fracture apertures.[35] In some contexts the probability distribution is described, not by the cumulative distribution function, by the cumulative frequency of a property X, defined as the number of elements per meter (or area unit, second etc.) for which X > x applies, where x is a variable real number. As an example,[35] the cumulative distribution of the fracture aperture, X, for a sample of N elements is defined as 'the number of fractures per meter having aperture greater than x . Use of cumulative frequency has some advantages, e.g. it allows one to put on the same diagram data gathered from sample lines of different lengths at different scales (e.g. from outcrop and from microscope).
R function
The following function estimates the exponent in R, plotting the log-log data and the fitted line.
pwrdist <- function(u,...) {
# u is vector of event counts, e.g. how many
# crimes was a given perpetrator charged for by the police
fx <- table(u)
i <- as.numeric(names(fx))
y <- rep(0,max(i))
y[i] <- fx
m0 <- glm(y~log(1:max(i)),family=quasipoisson())
print(summary(m0))
sub <- paste("s=",round(m0$coef[2],2),"lambda=",sum(u),"/",length(u))
plot(i,fx,log="xy",xlab="x",sub=sub,ylab="counts",...)
grid()
lines(1:max(i),(fitted(m0)),type="l")
return(m0)
}
Validating power laws
Although power-law relations are attractive for many theoretical reasons, demonstrating that data does indeed follow a power-law relation requires more than simply fitting a particular model to the data.[15] This is important for understanding the mechanism that gives rise to the distribution: superficially similar distributions may arise for significantly different reasons, and different models yield different predictions, such as extrapolation.
For example log-normal distributions are often mistaken for power-law distributions:[36] a data set drawn from a lognormal distribution will be approximately linear for large values (corresponding to the upper tail of the lognormal being close to a power law), but for small values the lognormal will drop off significantly (bowing down), corresponding to the lower tail of the lognormal being small (there are very few small values, rather than many small values in a power law).
For example, Gibrat's law about proportional growth processes produce distributions that are lognormal, although their log-log plots look linear over a limited range. An explanation of this is that although the logarithm of the lognormal density function is quadratic in log(x), yielding a "bowed" shape in a log-log plot, if the quadratic term is small relative to the linear term then the result can appear almost linear, and the lognormal behavior is only visible when the quadratic term dominates, which may require significantly more data. Therefore a log-log plot that is slightly "bowed" downwards can reflect a log-normal distribution – not a power law.
In general, many alternative functional forms can appear to follow a power-law form for some extent.[37] Also, researchers usually have to face the problem of deciding whether or not a real-world probability distribution follows a power law. As a solution to this problem, Diaz[24] proposed a graphical methodology based on random samples that allow visually discerning between different types of tail behavior. This methodology uses bundles of residual quantile functions, also called percentile residual life functions, which characterize many different types of distribution tails, including both heavy and non-heavy tails.
One method to validate a power-law relation tests many orthogonal predictions of a particular generative mechanism against data. Simply fitting a power-law relation to a particular kind of data is not considered a rational approach. As such, the validation of power-law claims remains a very active field of research in many areas of modern science.[6]
See also
References
Notes
- ↑ Yaneer Bar-Yam. "Concepts: Power Law". New England Complex Systems Institute. Retrieved 18 August 2015.
- 1 2 Newman, M. E. J. (2005). "Power laws, Pareto distributions and Zipf's law". Contemporary Physics 46 (5): 323–351. arXiv:cond-mat/0412004. Bibcode:2005ConPh..46..323N. doi:10.1080/00107510500052444.
- ↑ Humphries NE, Queiroz N, Dyer JR, Pade NG, Musyl MK, Schaefer KM, Fuller DW, Brunnschweiler JM, Doyle TK, Houghton JD, Hays GC, Jones CS, Noble LR, Wearmouth VJ, Southall EJ, Sims DW (2010). "Environmental context explains Lévy and Brownian movement patterns of marine predators". Nature 465 (7301): 1066–1069. Bibcode:2010Natur.465.1066H. doi:10.1038/nature09116. PMID 20531470.
- 1 2 3 Klaus A, Yu S, Plenz D (2011). Zochowski, Michal, ed. "Statistical Analyses Support Power Law Distributions Found in Neuronal Avalanches". PLoS ONE 6 (5): e19779. Bibcode:2011PLoSO...619779K. doi:10.1371/journal.pone.0019779. PMC 3102672. PMID 21720544.
- ↑ Albert, J. S.; Reis, R. E., eds. (2011). Historical Biogeography of Neotropical Freshwater Fishes. Berkeley: University of California Press.
- 1 2 3 4 5 Clauset, Shalizi & Newman 2009.
- ↑ "[cond-mat/0412004] Power laws, Pareto distributions and Zipf's law". arxiv.org.
- 1 2 9na CEPAL Charlas Sobre Sistemas Complejos Sociales (CCSSCS): Leyes de potencias, http://www.youtube.com/watch?v=4uDSEs86xCI
- ↑ Malcolm Gladwell (2006), Million-Dollar Murray; http://gladwell.com/million-dollar-murray/
- ↑ Newman, Mark EJ. "Power laws, Pareto distributions and Zipf's law." Contemporary physics 46.5 (2005): 323-351.
- ↑ Sornette 2006.
- ↑ Simon 1955.
- ↑ Andriani, P., & McKelvey, B. (2007). Beyond Gaussian averages: redirecting international business and management research toward extreme events and power laws. Journal of International Business Studies, 38(7), 1212–1230. doi:10.1057/palgrave.jibs.8400324
- ↑ Reed W.J.; Hughes B.D. From gene families and genera to incomes and internet file sizes: Why power laws are so common in nature. Phys Rev E 2002, 66, 067103; http://www.math.uvic.ca/faculty/reed/PhysRevPowerLawTwoCol.pdf
- 1 2 "Hilbert, M. (2013), Scale-free power-laws as interaction between progress and diffusion.", Martin Hilbert (2013), Complexity (journal), doi: 10.1002/cplx.21485; free access to the article through this link: martinhilbert.net/Powerlaw_ProgressDiffusion_Hilbert.pdf
- ↑ Bolmatov, D.; Brazhkin, V. V.; Trachenko, K. (2013). "Thermodynamic behaviour of supercritical matter". Nature Communications 4. arXiv:1303.3153v3. doi:10.1038/ncomms3331.
- ↑ "Afterglow Light Curves and Broken Power Laws: A Statistical Study". Retrieved 2013-07-07.
- ↑ "POWER-LAW DISTRIBUTIONS IN EMPIRICAL DATA" (PDF). Retrieved 2013-07-07.
- ↑ "Curved-power law". Retrieved 2013-07-07.
- ↑ Kendal WS & Jørgensen B (2011) Taylor's power law and fluctuation scaling explained by a central-limit-like convergence. Phys. Rev. E 83,066115
- ↑ Kendal WS & Jørgensen BR (2011) Tweedie convergence: a mathematical basis for Taylor's power law, 1/f noise and multifractality. Phys. Rev E 84, 066120
- ↑ Beirlant, J., Teugels, J. L., Vynckier, P. (1996a) Practical Analysis of Extreme Values, Leuven: Leuven University Press
- ↑ Coles, S. (2001) An introduction to statistical modeling of extreme values. Springer-Verlag, London.
- 1 2 3 4 Diaz, F. J. (1999). "Identifying Tail Behavior by Means of Residual Quantile Functions". Journal of Computational and Graphical Statistics 8 (3): 493–509. doi:10.2307/1390871.
- ↑ Resnick, S. I. (1997) "Heavy Tail Modeling and Teletraffic Data", The Annals of Statistics, 25, 1805–1869.
- ↑ Jeong, H; Tombor, B. Albert; Oltvai, Z.N.; Barabasi, A.-L. (2000). "The large-scale organization of metabolic networks". Nature 407 (6804): 651–654. arXiv:cond-mat/0010278. Bibcode:2000Natur.407..651J. doi:10.1038/35036627. PMID 11034217.
- ↑ Arnold, B. C., Brockett, P. L. (1983) "When does the βth percentile residual life function determine the distribution?", Operations Research 31 (2), 391–396.
- ↑ Joe, H., Proschan, F. (1984) "Percentile residual life functions", Operations Research 32 (3), 668–678.
- ↑ Joe, H. (1985), "Characterizations of life distributions from percentile residual lifetimes", Ann. Inst. Statist. Math. 37, Part A, 165–172.
- ↑ Csorgo, S., Viharos, L. (1992) "Confidence bands for percentile residual lifetimes", Journal of Statistical Planning and Inference 30, 327–337.
- ↑ Schmittlein, D. C., Morrison, D. G. (1981), "The median residual lifetime: A characterization theorem and an application", Operations Research 29 (2), 392–399.
- ↑ Morrison, D. G., Schmittlein, D. C. (1980) "Jobs, strikes, and wars: Probability models for duration", Organizational Behavior and Human Performance 25, 224–251.
- ↑ Gerchak, Y. (1984) "Decreasing failure rates and related issues in the social sciences", Operations Research 32 (3), 537–546.
- ↑ Hall, P. (1982). "On Some Simple Estimates of an Exponent of Regular Variation". Journal of the Royal Statistical Society, Series B 44 (1): 37–42. JSTOR 2984706.
- 1 2 3 Guerriero, V. (2012). "Power Law Distribution: Method of Multi-scale Inferential Statistics". Journal of Modern Mathematics Frontier (JMMF) 1: 21–28.
- ↑ Mitzenmacher 2004.
- ↑ Laherrère & Sornette 1998.
Bibliography
- Bak, Per (1997) How nature works, Oxford University Press ISBN 0 19 850164 1
- Clauset, A.; Shalizi, C. R.; Newman, M. E. J. (2009). "Power-Law Distributions in Empirical Data". SIAM Review 51 (4): 661–703. arXiv:0706.1062. Bibcode:2009SIAMR..51..661C. doi:10.1137/070710111.
- Laherrère, J.; Sornette, D. (1998). "Stretched exponential distributions in nature and economy: "fat tails" with characteristic scales". The European Physical Journal B 2 (4): 525–539. arXiv:cond-mat/9801293. Bibcode:1998EPJB....2..525L. doi:10.1007/s100510050276.
- Mitzenmacher, M. (2004). "A Brief History of Generative Models for Power Law and Lognormal Distributions" (PDF). Internet Mathematics 1 (2): 226–251. doi:10.1080/15427951.2004.10129088.
- Alexander Saichev, Yannick Malevergne and Didier Sornette (2009) Theory of Zipf's law and beyond, Lecture Notes in Economics and Mathematical Systems, Volume 632, Springer (November 2009), ISBN 978-3-642-02945-5
- Simon, H. A. (1955). "On a Class of Skew Distribution Functions". Biometrika 42 (3/4): 425–440. doi:10.2307/2333389. JSTOR 2333389.
- Sornette, Didier (2006). Critical Phenomena in Natural Sciences: Chaos, Fractals, Self-organization and Disorder: Concepts and Tools. Springer Series in Synergetics (2nd ed.). Heidelberg: Springer. ISBN 978-3-540-30882-9.
- Mark Buchanan (2000) Ubiquity, Wiedenfield & Nicholson ISBN 0-297-64376-2
- Stumpf, M.P.H. and Porter, M.A. "Critical Truths about Power Laws" Science 2012, 335, 665-6
External links
- Zipf's law
- Zipf, Power-laws, and Pareto – a ranking tutorial
- Gutenberg–Richter Law
- Stream Morphometry and Horton's Laws
- Clay Shirky on Institutions & Collaboration: Power law in relation to the internet-based social networks
- Clay Shirky on Power Laws, Weblogs, and Inequality
- "How the Finance Gurus Get Risk All Wrong" by Benoit Mandelbrot & Nassim Nicholas Taleb. Fortune, July 11, 2005.
- "Million-dollar Murray": power-law distributions in homelessness and other social problems; by Malcolm Gladwell. The New Yorker, February 13, 2006.
- Benoit Mandelbrot & Richard Hudson: The Misbehaviour of Markets (2004)
- Philip Ball: Critical Mass: How one thing leads to another (2005)
- Tyranny of the Power Law from The Econophysics Blog
- So You Think You Have a Power Law – Well Isn't That Special? from Three-Toed Sloth, the blog of Cosma Shalizi, Professor of Statistics at Carnegie-Mellon University.
- Simple MATLAB script which bins data to illustrate power-law distributions (if any) in the data.
- The Erdős Webgraph Server visualizes the distribution of the degrees of the webgraph on the download page.