False position method
“False Position” and “Regula Falsi” are two early, and still current, names for a very old method for solving an equation in one unknown.
Brief Background
To solve an equation means to write, or determine the numerical value of, one of its quantities in terms of the other quantities mentioned in the equation.
Many equations, including most of the more complicated ones, can be solved only by iterative numerical approximation. That consists of trial and error, in which various values of the unknown quantity, referred to here as “x”, are tried. That trial-and-error may be informed by a calculated estimate for the solution. The iterative numerical approximation methods for solving equations, which use a calculated estimate for the solution, for use in calculating the next, improved, solution-estimate, , differ only by how their calculated solution-estimates are made.
Basic Procedure. Terminology for This Section:
By moving all of an equation’s terms to one side, we can get an equation that says: f(x) = 0 …where f(x) is some function of the unknown variable “x”. That transforms the problem into one of finding the x-value at which f(x) = 0. That x-value is the equation’s solution.
In this section, the symbol “y” will be used interchangeably with f(x)…when that improves brevity, clarity, and reduces clutter.
Here, “y” means “y(x)” means “f(x)”. The expressions “y” and “f(x)” will both be used here, and they mean the same thing. The symbol “y” is familiar, as the often-used name for the vertical co-ordinate on a graph, often a function of “x”, the horizontal co-ordinate.
The Two-Point Bracketing Methods in General
Many methods for the calculated-estimate are used. The oldest and simplest class of such methods, and the class that contains the most reliable method (Bisection), are the two-point bracketing methods.
Those methods start with two x-values, initially found by trial-and-error, at which f(x) has opposite signs. In other words: Two x-values such that, for one of them, f(x) is positive, and for the other, f(x) is negative. In that way, those two f(x) values (i.e. y-values) can be said to “bracket” zero, because they’re on opposite sides of zero.
That bracketing, along with the fact that the solution-estimate-calculation method (to be discussed later) always chooses an x-value between the two current bracketing values, guarantees that the solution-estimates will converge toward the solution. …a guarantee not available with such other methods as Newton’s method or the Secant method.
When f(x) is evaluated at a certain x-value, call it x1, resulting in f(x1), that combination of x and y values is called a “data-point”, the data point (x1, y1).
The two-point bracketing methods use, for each iterative step, two such data points, from which to get a calculated estimate for the solution. f(x) is then evaluated for that estimated x, to get a new data point, from which to calculate a new, and closer, estimated solution.
Call any current pair of data points (x1, y1) and (x2, y2). A calculated-estimate method (none of which have been discussed here yet, but soon will be) is used to calculate, from those two data points, a third x-value, x3 at which to evaluate f(x). (to evaluate “y3”, in other words).
That evaluation of y3 provides a 3rd data point, (x3, y3).
That new data point will be used as one of the pair of data points for the next solution-estimate calculation. To preserve the bracketing, the data point used with it for that purpose will be the most recently-calculated one whose y value is opposite in sign to the newest y value.
That new pair of points becomes the new data-points pair (x1, y1), and (x2, y2) …which is again used to calculate a new estimated solution, x3. …at which f(x) is evaluated, for a new y3. …and so on.
Just to illustrate what happens, suppose that y3 has the same sign as y2. Then, by the rule stated above, the data point (x1, y1) –instead of (x2, y2)--is used with the new data point, (x3, y3), because that earlier data-point is the most recently calculated data point whose y is opposite in sign to that of the new data point.
The Bisection Method
The simplest solution-estimate calculation method is just to choose, as x3, the mean of x1 and x2.
That is:
x3 = 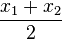
That’s enough to ensure that x3 is between x1 and x2, thereby guaranteeing convergence toward the solution.
So, those two x-values that enclose (bracket) the solution are always, after each iteration, twice as close together as they were after the previous iteration. Additionally, that procedure ensures that:
1. x3’s error (its distance from the solution) is less than half of the maximum of the errors of x1 and x2.
2. The average of the errors of each x1, x2 pair is half that of the previous x1, x2 pair.
No other method can guarantee those things. Bisection’s error is, on average, halved with each iteration. The method gains roughly a decimal place of accuracy, by each 3 iterations.
The Regula Falsi (False Position) Method
One can try for a better convergence-rate, at the risk of a worse one, or none at all.
Most numerical equation-solving methods usually converge faster than Bisection. The price for that is that some of them (e.g. Newton’s method and Secant) can fail to converge at all, and all of them can sometimes converge very much more slowly than Bisection—sometimes prohibitively slowly. None can guarantee Bisection’s reliable and steady guaranteed convergence rate. Regula Falsi, like Bisection, always converges, usually considerably faster than Bisection--but sometimes very much more slowly than Bisection.
When numerically solving an equation manually, by calculator, or when a computer program run has to solve equations so many times that the speed of convergence becomes important, then it could be preferable to first try a usually-faster method, going to Bisection only if the faster method fails to converge, or fails to converge at a useful rate.
The fact that Regula Falsi always converges, and has versions that do well at avoiding slowdowns, makes it a good choice when speed is needed, and when Newton’s method doesn’t converge, or when the evaluation of the derivative is too time-consuming for Newton’s to be useful.
Regula Falsi’s Calculated Solution-Estimate Method:
Regula Falsi assumes that f(x) is linear—even though these methods are needed only when f(x) is not linear, and usually work well anyway.
The ratio of the change in x, to the resulting change in y is:
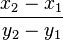
Because y, most recently, is y2, and we want y to be 0, then the change that we want in y is:
0 – y2
Of course that’s equal to –y2.
So, given that desired change in y, and given the expected ratio of change in x to change in y, then the best (linearly-gotten) estimate for the right x-value--the best estimate for the solution--is:
The latest value of x plus the product of the desired change in y and the expected ratio of change in x to change in y:
x3 = 
That formula for x3 is adequate, but can be put in a more practical form:
Multiply, put over a common denominator, and collect terms, and the result is:
x3 =
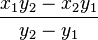
Not only is this form more simple and symmetrical, but it has a computational advantage:
As a solution is approached, x1 and x2 will be very close together, and nearly always of the same sign. Such a subtraction can lose significant digits.
Because y2 and y1 are always of opposite sign the “subtraction” in the numerator of the improved formula is effectively an addition (as is the subtraction in the denominator too).
Discussion in Historical Context
The false position method or regula falsi method is a term for problem-solving methods in arithmetic, algebra, and calculus. In simple terms, these methods begin by attempting to evaluate a problem using test ("false") values for the variables, and then adjust the values accordingly.
Two basic types of false position method can be distinguished, simple false position and double false position. Simple false position is aimed at solving problems involving direct proportion. Such problems can be written algebraically in the form: determine x such that

if a and b are known. Double false position is aimed at solving more difficult problems that can be written algebraically in the form: determine x such that

if it is known that

Double false position is mathematically equivalent to linear interpolation; for an affine linear function,
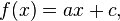
it provides the exact solution, while for a nonlinear function f it provides an approximation that can be successively improved by iteration.
Arithmetic and algebra
In problems involving arithmetic or algebra, the false position method or regula falsi is used to refer to basic trial and error methods of solving problems by substituting test values for the unknown quantities. This is sometimes also referred to as "guess and check". Versions of this method predate the advent of algebra and the use of equations.
For simple false position, the method of solving what we would now write as ax = b begins by using a test input value x′, and finding the corresponding output value b′ by multiplication: ax′ = b′. The correct answer is then found by proportional adjustment, x = x′ · b ÷ b′. This technique is found in cuneiform tablets from ancient Babylonian mathematics, and possibly in papyri from ancient Egyptian mathematics.[1]
Likewise, double false position arose in late antiquity as a purely arithmetical algorithm. It was used mostly to solve what are now called affine linear problems by using a pair of test inputs and the corresponding pair of outputs. This algorithm would be memorized and carried out by rote. In the ancient Chinese mathematical text called The Nine Chapters on the Mathematical Art (九章算術),[2] dated from 200 BC to AD 100, most of Chapter 7 was devoted to the algorithm. There, the procedure was justified by concrete arithmetical arguments, then applied creatively to a wide variety of story problems, including one involving what we would call secant lines on a quadratic polynomial. A more typical example is this "joint purchase" problem:
Now an item is purchased jointly; everyone contributes 8 [coins], the excess is 3; everyone contributes 7, the deficit is 4. Tell: The number of people, the item price, what is each? Answer: 7 people, item price 53.[3]
Between the 9th and 10th centuries, the Egyptian Muslim mathematician Abu Kamil wrote a now-lost treatise on the use of double false position, known as the Book of the Two Errors (Kitāb al-khaṭāʾayn). The oldest surviving writing on double false position from the Middle East is that of Qusta ibn Luqa (10th century), a Christian Arab mathematician from Baalbek, Lebanon. He justified the technique by a formal, Euclidean-style geometric proof. Within the tradition of medieval Muslim mathematics, double false position was known as hisāb al-khaṭāʾayn ("reckoning by two errors"). It was used for centuries, especially in the Maghreb, to solve practical problems such as commercial and juridical questions (estate partitions according to rules of Quranic inheritance), as well as purely recreational problems. The algorithm was often memorized with the aid of mnemonics, such as a verse attributed to Ibn al-Yasamin and balance-scale diagrams explained by al-Hassar and Ibn al-Banna, all three being mathematicians of Moroccan origin.[4]
Leonardo of Pisa (Fibonacci) devoted Chapter 13 of his book Liber Abaci (AD 1202) to explaining and demonstrating the uses of double false position, terming the method regulis elchatayn after the al-khaṭāʾayn method that he had learned from Arab sources.[4]
Numerical analysis
In numerical analysis, double false position became a root-finding algorithm that combines features from the bisection method and the secant method.
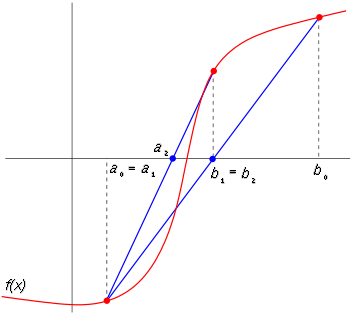
Like the bisection method, the false position method starts with two points a0 and b0 such that f(a0) and f(b0) are of opposite signs, which implies by the intermediate value theorem that the function f has a root in the interval [a0, b0], assuming continuity of the function f. The method proceeds by producing a sequence of shrinking intervals [ak, bk] that all contain a root of f.
At iteration number k, the number

is computed. As explained below, ck is the root of the secant line through (ak, f(ak)) and (bk, f(bk)). If f(ak) and f(ck) have the same sign, then we set ak+1 = ck and bk+1 = bk, otherwise we set ak+1 = ak and bk+1 = ck. This process is repeated until the root is approximated sufficiently well.
The above formula is also used in the secant method, but the secant method always retains the last two computed points, while the false position method retains two points which certainly bracket a root. On the other hand, the only difference between the false position method and the bisection method is that the latter uses ck = (ak + bk) / 2.
Finding the root of the secant
Given ak and bk, we construct the line through the points (ak, f(ak)) and (bk, f(bk)), as demonstrated in the picture immediately above. Note that this line is a secant or chord of the graph of the function f. In point-slope form, it can be defined as

We now choose ck to be the root of this line (substituting for x), and setting  and see that
and see that
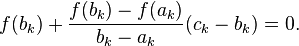
Solving this equation gives the above equation for ck.
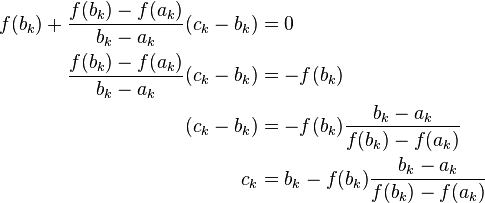
Analysis
If the initial end-points a0 and b0 are chosen such that f(a0) and f(b0) are of opposite signs, then at each step, one of the end-points will get closer to a root of f. If the second derivative of f is of constant sign (so there is no inflection point) in the interval, then one endpoint (the one where f also has the same sign) will remain fixed for all subsequent iterations while the converging endpoint becomes updated. As a result, unlike the bisection method, the width of the bracket does not tend to zero (unless the zero is at an inflection point around which sign(f)=-sign(f″)). As a consequence, the linear approximation to f(x), which is used to pick the false position, does not improve in its quality.
One example of this phenomenon is the function
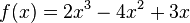
on the initial bracket [−1,1]. The left end, −1, is never replaced (after the first three iterations, f″ is negative on the interval) and thus the width of the bracket never falls below 1. Hence, the right endpoint approaches 0 at a linear rate (the number of accurate digits grows linearly, with a rate of convergence of 2/3).
For discontinuous functions, this method can only be expected to find a point where the function changes sign (for example at x=0 for 1/x or the sign function). In addition to sign changes, it is also possible for the method to converge to a point where the limit of the function is zero, even if the function is undefined (or has another value) at that point (for example at x=0 for the function given by f(x)=abs(x)-x² when x≠0 and by f(0)=5, starting with the interval [-0.5, 3.0]). It is mathematically possible with discontinuous functions for the method to fail to converge to a zero limit or sign change, but this is not a problem in practice since it would require an infinite sequence of coincidences for both endpoints to get stuck converging to discontinuities where the sign does not change (for example at x=±1 in f(x)=1/(x-1)²+1/(x+1)²). The method of bisection avoids this hypothetical convergence problem.
Improvements in regula falsi
The Illinois version:
Though Regula Falsi always converges, usually considerably faster than Bisection, there are situations that can slow its convergence--sometimes to a prohibitive degree. That problem isn't unique to Regula Falsi: Other than Bisection, all of the numerical equation-solving methods can have a slow-convergence or no-convergence problem under some conditions. Sometimes, Newton's Method and the Secant Method diverge instead of converging--and often do so under the conditions that slow Regula Falsi's convergence.
But, though Regula Falsi is one of the best methods, and--even in its original un-improved version--would often be the best choice (e.g. when Newton's isn't used because the derivative is prohibitively time-consuming to evaluate, or when Newton's and Successive-Substitutions have failed to converge)...A number of improvements to Regula Falsi have been proposed, in order to avoid slowdowns under those relatively unusual unfavorable situations.
The failure mode is easy to detect (the same end-point is retained twice in a row) and easily remedied by next picking a modified false position, such as
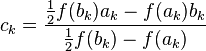
or

down-weighting one of the endpoint values to force the next ck to occur on that side of the function. The factor of 2 above looks like a hack, but it guarantees superlinear convergence (asymptotically, the algorithm will perform two regular steps after any modified step, and has order of convergence 1.442). There are other ways to pick the rescaling which give even better superlinear convergence rates.[5]
The above adjustment to regula falsi is sometimes called the Illinois algorithm.[6][7] Ford (1995) summarizes and analyzes this and other similar superlinear variants of the method of false position.[5]
Put simply:
When the new y-value has the same sign as the previous one, meaning that the data point before the previous one will be retained, the Illinois version halves the y-value of the retained data point.
The Anderson-Bjőrk version:
If points (x1, y1) and (x2, y2) have resulted in the new point (x3, y3), and if y3 has the same sign as y2, then retain the point (x1, y1), to use with the newest point, for the next Regula Falsi step.
So far, that's the same as ordinary Regula Falsi and Illinois.
But, where Illinois would multiply y1 by 1/2, Anderson-Bjőrk multiplies it by m, where m has the following value:
m = 1 - y3/y2 ...if that's greater than 0
else: m = 1/2
Anderson-Bjőrk was the clear winner in Galdino's numerical tests ("A Family of Regula Falsi Methods", Galdino, accessible via google), for simple roots.
For multiple roots, no method was much faster than Bisection. In fact, the only methods that were as fast as Bisection were three new methods introduced by Galdino. But even they were only a little faster than Bisection.
Broad choice of method
Bisection:
When solving one equation, or just a few, using a computer, there's no reason to not just use Bisection. Though Bisection isn't as fast as the other methods--when they're at their best and don't have a problem--Bisection nevertheless is guaranteed to converge at a useful rate, roughly halving the error with each iteration. ...gaining roughly a decimal place of accuracy with each 3 iterations.
For manual calculation, by calculator, one tends to want to use faster methods, and they usually, but not always, converge faster than Bisection. But a computer, even using Bisection, will solve an equation, to the desired accuracy, so rapidly that there's no need to try to save time by using a less reliable method--and every method is less reliable than Bisection.
An exception would be if the computer program had to solve equations very many times during its run. Then the time saved by the faster methods could be significant.
Then, a program could start with Newton's method, and, if Newton's isn't converging, switch to Regula Falsi, maybe in one of its improved versions, such as Illinois or Anderson-Bjőrk. ...and then, if even that isn't converging as well as Bisection would, switch to Bisection, which always converges at a useful, if not spectacular, rate.
Newton's Method when close to convergence:
When the magnitude of y has become very small, and x is changing very little, then, most likely, Newton's Method won't run into any trouble, and will converge. So, under those favorable conditions, one could switch to Newton's method if one wanted the error to be very small and wanted very fast convergence.
Example code
This example programme, written in the C programming language, has been written for clarity instead of efficiency. It was designed to solve the same problem as solved by the Newton's method and secant method code: to find the positive number x where cos(x) = x3. This problem is transformed into a root-finding problem of the form f(x) = cos(x) - x3 = 0.
#include <stdio.h>
#include <math.h>
double f(double x)
{
return cos(x) - x*x*x;
}
/* s,t: endpoints of an interval where we search
e: half of upper bound for relative error
m: maximal number of iterations */
double FalsiMethod(double s, double t, double e, int m)
{
double r,fr;
int n, side=0;
/* starting values at endpoints of interval */
double fs = f(s);
double ft = f(t);
for (n = 0; n < m; n++)
{
r = (fs*t - ft*s) / (fs - ft);
if (fabs(t-s) < e*fabs(t+s)) break;
fr = f(r);
if (fr * ft > 0)
{
/* fr and ft have same sign, copy r to t */
t = r; ft = fr;
if (side==-1) fs /= 2;
side = -1;
}
else if (fs * fr > 0)
{
/* fr and fs have same sign, copy r to s */
s = r; fs = fr;
if (side==+1) ft /= 2;
side = +1;
}
else
{
/* fr * f_ very small (looks like zero) */
break;
}
}
return r;
}
int main(void)
{
printf("%0.15f\n", FalsiMethod(0, 1, 5E-15, 100));
return 0;
}
After running this code, the final answer is approximately 0.865474033101614
See also
- Ridders' method, another root-finding method based on the false position method
- Brent's method
- Secant method
References
- ↑ Jean-Luc Chabert, ed., A History of Algorithms: From the Pebble to the Microchip (Berlin: Springer, 1999), pp. 86-91.
- ↑ Joseph Needham (1 January 1959). Science and Civilisation in China: Volume 3, Mathematics and the Sciences of the Heavens and the Earth. Cambridge University Press. pp. 147–. ISBN 978-0-521-05801-8.
- ↑ Shen Kangshen, John N. Crossley and Anthony W.-C. Lun, 1999. The Nine Chapters on the Mathematical Art: Companion and Commentary. Oxford: Oxford University Press, p. 358.
- 1 2 Schwartz, R. K. (2004). Issues in the Origin and Development of Hisab al-Khata’ayn (Calculation by Double False Position). Eighth North African Meeting on the History of Arab Mathematics. Radès, Tunisia. Available online at: http://facstaff.uindy.edu/~oaks/Biblio/COMHISMA8paper.doc and http://www.ub.edu/islamsci/Schwartz.pdf
- 1 2 Ford, J. A. (1995), Improved Algorithms of Illinois-type for the Numerical Solution of Nonlinear Equations, Technical Report, University of Essex Press, CSM-257
- ↑ Dahlquist, Germund; Björck, Åke (2003) [1974]. Numerical Methods. Dover. pp. 231–232. ISBN 978-0486428079.
- ↑ Dowell, M.; Jarratt, P. (1971). "A modified regula falsi method for computing the root of an equation". BIT 11 (2): 168–174. doi:10.1007/BF01934364.
Further reading
- Richard L. Burden, J. Douglas Faires (2000). Numerical Analysis, 7th ed. Brooks/Cole. ISBN 0-534-38216-9.
- L.E. Sigler (2002). Fibonacci's Liber Abaci, Leonardo Pisano's Book of Calculation. Springer-Verlag, New York. ISBN 0-387-40737-5.
External links
| ||||||||||||||||||||||