Robust statistics
Robust statistics are statistics with good performance for data drawn from a wide range of probability distributions, especially for distributions that are not normal. Robust statistical methods have been developed for many common problems, such as estimating location, scale and regression parameters. One motivation is to produce statistical methods that are not unduly affected by outliers. Another motivation is to provide methods with good performance when there are small departures from parametric distributions. For example, robust methods work well for mixtures of two normal distributions with different standard-deviations; under this model, non-robust methods like a t-test work badly.
Introduction
Robust statistics seeks to provide methods that emulate popular statistical methods, but which are not unduly affected by outliers or other small departures from model assumptions. In statistics, classical estimation methods rely heavily on assumptions which are often not met in practice. In particular, it is often assumed that the data errors are normally distributed, at least approximately, or that the central limit theorem can be relied on to produce normally distributed estimates. Unfortunately, when there are outliers in the data, classical estimators often have very poor performance, when judged using the breakdown point and the influence function, described below.
The practical effect of problems seen in the influence function can be studied empirically by examining the sampling distribution of proposed estimators under a mixture model, where one mixes in a small amount (1–5% is often sufficient) of contamination. For instance, one may use a mixture of 95% a normal distribution, and 5% a normal distribution with the same mean but significantly higher standard deviation (representing outliers).
Robust parametric statistics can proceed in two ways:
- by designing estimators so that a pre-selected behaviour of the influence function is achieved
- by replacing estimators that are optimal under the assumption of a normal distribution with estimators that are optimal for, or at least derived for, other distributions: for example using the t-distribution with low degrees of freedom (high kurtosis; degrees of freedom between 4 and 6 have often been found to be useful in practice ) or with a mixture of two or more distributions.
Robust estimates have been studied for the following problems:
- estimating location parameters
- estimating scale parameters
- estimating regression coefficients
- estimation of model-states in models expressed in state-space form, for which the standard method is equivalent to a Kalman filter.
Examples
- The median is a robust measure of central tendency, while the mean is not. The median has a breakdown point of 50%, while the mean has a breakdown point of 0% (a single large observation can throw it off).
- The median absolute deviation and interquartile range are robust measures of statistical dispersion, while the standard deviation and range are not.
Trimmed estimators and Winsorised estimators are general methods to make statistics more robust. L-estimators are a general class of simple statistics, often robust, while M-estimators are a general class of robust statistics, and are now the preferred solution, though they can be quite involved to calculate.
Definition
There are various definitions of a "robust statistic." Strictly speaking, a robust statistic is resistant to errors in the results, produced by deviations from assumptions[1] (e.g., of normality). This means that if the assumptions are only approximately met, the robust estimator will still have a reasonable efficiency, and reasonably small bias, as well as being asymptotically unbiased, meaning having a bias tending towards 0 as the sample size tends towards infinity.
One of the most important cases is distributional robustness.[1] Classical statistical procedures are typically sensitive to "longtailedness" (e.g., when the distribution of the data has longer tails than the assumed normal distribution). Thus, in the context of robust statistics, distributionally robust and outlier-resistant are effectively synonymous.[1] For one perspective on research in robust statistics up to 2000, see Portnoy and He (2000).
A related topic is that of resistant statistics, which are resistant to the effect of extreme scores.
Example: speed of light data
Gelman et al. in Bayesian Data Analysis (2004) consider a data set relating to speed of light measurements made by Simon Newcomb. The data sets for that book can be found via the Classic data sets page, and the book's website contains more information on the data.
Although the bulk of the data look to be more or less normally distributed, there are two obvious outliers. These outliers have a large effect on the mean, dragging it towards them, and away from the center of the bulk of the data. Thus, if the mean is intended as a measure of the location of the center of the data, it is, in a sense, biased when outliers are present.
Also, the distribution of the mean is known to be asymptotically normal due to the central limit theorem. However, outliers can make the distribution of the mean non-normal even for fairly large data sets. Besides this non-normality, the mean is also inefficient in the presence of outliers and less variable measures of location are available.
Estimation of location
The plot below shows a density plot of the speed of light data, together with a rug plot (panel (a)). Also shown is a normal Q–Q plot (panel (b)). The outliers are clearly visible in these plots.
Panels (c) and (d) of the plot show the bootstrap distribution of the mean (c) and the 10% trimmed mean (d). The trimmed mean is a simple robust estimator of location that deletes a certain percentage of observations (10% here) from each end of the data, then computes the mean in the usual way. The analysis was performed in R and 10,000 bootstrap samples were used for each of the raw and trimmed means.
The distribution of the mean is clearly much wider than that of the 10% trimmed mean (the plots are on the same scale). Also note that whereas the distribution of the trimmed mean appears to be close to normal, the distribution of the raw mean is quite skewed to the left. So, in this sample of 66 observations, only 2 outliers cause the central limit theorem to be inapplicable.

Robust statistical methods, of which the trimmed mean is a simple example, seek to outperform classical statistical methods in the presence of outliers, or, more generally, when underlying parametric assumptions are not quite correct.
Whilst the trimmed mean performs well relative to the mean in this example, better robust estimates are available. In fact, the mean, median and trimmed mean are all special cases of M-estimators. Details appear in the sections below.
Estimation of scale
The outliers in the speed of light data have more than just an adverse effect on the mean; the usual estimate of scale is the standard deviation, and this quantity is even more badly affected by outliers because the squares of the deviations from the mean go into the calculation, so the outliers' effects are exacerbated.
The plots below show the bootstrap distributions of the standard deviation, median absolute deviation (MAD) and Qn estimator of scale (Rousseeuw and Croux, 1993). The plots are based on 10000 bootstrap samples for each estimator, with some Gaussian noise added to the resampled data (smoothed bootstrap). Panel (a) shows the distribution of the standard deviation, (b) of the MAD and (c) of Qn.

The distribution of standard deviation is erratic and wide, a result of the outliers. The MAD is better behaved, and Qn is a little bit more efficient than MAD. This simple example demonstrates that when outliers are present, the standard deviation cannot be recommended as an estimate of scale.
Manual screening for outliers
Traditionally, statisticians would manually screen data for outliers, and remove them, usually checking the source of the data to see if the outliers were erroneously recorded. Indeed, in the speed of light example above, it is easy to see and remove the two outliers prior to proceeding with any further analysis. However, in modern times, data sets often consist of large numbers of variables being measured on large numbers of experimental units. Therefore, manual screening for outliers is often impractical.
Outliers can often interact in such a way that they mask each other. As a simple example, consider a small univariate data set containing one modest and one large outlier. The estimated standard deviation will be grossly inflated by the large outlier. The result is that the modest outlier looks relatively normal. As soon as the large outlier is removed, the estimated standard deviation shrinks, and the modest outlier now looks unusual.
This problem of masking gets worse as the complexity of the data increases. For example, in regression problems, diagnostic plots are used to identify outliers. However, it is common that once a few outliers have been removed, others become visible. The problem is even worse in higher dimensions.
Robust methods provide automatic ways of detecting, downweighting (or removing), and flagging outliers, largely removing the need for manual screening. Care must be taken; initial data showing the ozone hole first appearing over Antarctica were rejected as outliers by non-human screening[2]
Variety of applications
Although this article deals with general principles for univariate statistical methods, robust methods also exist for regression problems, generalized linear models, and parameter estimation of various distributions.
Measures of robustness
The basic tools used to describe and measure robustness are, the breakdown point, the influence function and the sensitivity curve.
Breakdown point
Intuitively, the breakdown point of an estimator is the proportion of incorrect observations (e.g. arbitrarily large observations) an estimator can handle before giving an incorrect (e.g., arbitrarily large) result. For example, given  independent random variables
independent random variables  and the corresponding realizations
and the corresponding realizations  , we can use
, we can use  to estimate the mean. Such an estimator has a breakdown point of 0 because we can make
to estimate the mean. Such an estimator has a breakdown point of 0 because we can make 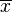 arbitrarily large just by changing any of .
arbitrarily large just by changing any of .
The higher the breakdown point of an estimator, the more robust it is. Intuitively, we can understand that a breakdown point cannot exceed 50% because if more than half of the observations are contaminated, it is not possible to distinguish between the underlying distribution and the contaminating distribution. Therefore, the maximum breakdown point is 0.5 and there are estimators which achieve such a breakdown point. For example, the median has a breakdown point of 0.5. The X% trimmed mean has breakdown point of X%, for the chosen level of X. Huber (1981) and Maronna et al. (2006) contain more details. The level and the power breakdown points of tests are investigated in He et al. (1990).
Statistics with high breakdown points are sometimes called resistant statistics.[3]
Example: speed of light data
In the speed of light example, removing the two lowest observations causes the mean to change from 26.2 to 27.75, a change of 1.55. The estimate of scale produced by the Qn method is 6.3. We can divide this by the square root of the sample size to get a robust standard error, and we find this quantity to be 0.78. Thus, the change in the mean resulting from removing two outliers is approximately twice the robust standard error.
The 10% trimmed mean for the speed of light data is 27.43. Removing the two lowest observations and recomputing gives 27.67. Clearly, the trimmed mean is less affected by the outliers and has a higher breakdown point.
Notice that if we replace the lowest observation, -44, by -1000, the mean becomes 11.73, whereas the 10% trimmed mean is still 27.43. In many areas of applied statistics, it is common for data to be log-transformed to make them near symmetrical. Very small values become large negative when log-transformed, and zeroes become negatively infinite. Therefore, this example is of practical interest.
Empirical influence function

The empirical influence function is a measure of the dependence of the estimator on the value of one of the points in the sample. It is a model-free measure in the sense that it simply relies on calculating the estimator again with a different sample. On the right is Tukey's biweight function, which, as we will later see, is an example of what a "good" (in a sense defined later on) empirical influence function should look like.
In mathematical terms, an influence function is defined as a vector in the space of the estimator, which is in turn defined for a sample which is a subset of the population:
 is a probability space,
is a probability space, is a measure space (state space),
is a measure space (state space),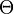 is a parameter space of dimension
is a parameter space of dimension  ,
,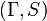 is a measure space,
is a measure space,
For example,
- is any probability space,
 ,
,
 ,
,
The definition of an empirical influence function is:
Let  and
and 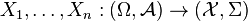 are i.i.d. and
are i.i.d. and  is a sample from these variables.
is a sample from these variables.  is an estimator. Let
is an estimator. Let  . The empirical influence function
. The empirical influence function  at observation
at observation  is defined by:
is defined by:

Note that  .
.
What this actually means is that we are replacing the i-th value in the sample by an arbitrary value and looking at the output of the estimator. Alternatively, the EIF is defined as the (scaled by n+1 instead of n) effect on the estimator of adding the point  to the sample.[4]
to the sample.[4]
Influence function and sensitivity curve
Instead of relying solely on the data, we could use the distribution of the random variables. The approach is quite different from that of the previous paragraph. What we are now trying to do is to see what happens to an estimator when we change the distribution of the data slightly: it assumes a distribution, and measures sensitivity to change in this distribution. By contrast, the empirical influence assumes a sample set, and measures sensitivity to change in the samples.[5]
Let 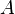 be a convex subset of the set of all finite signed measures on
be a convex subset of the set of all finite signed measures on 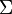 . We want to estimate the parameter
. We want to estimate the parameter  of a distribution
of a distribution 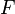 in . Let the functional
in . Let the functional 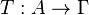 be the asymptotic value of some estimator sequence
be the asymptotic value of some estimator sequence  . We will suppose that this functional is Fisher consistent, i.e.
. We will suppose that this functional is Fisher consistent, i.e. 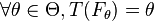 . This means that at the model , the estimator sequence asymptotically measures the correct quantity.
. This means that at the model , the estimator sequence asymptotically measures the correct quantity.
Let  be some distribution in . What happens when the data doesn't follow the model exactly but another, slightly different, "going towards" ?
be some distribution in . What happens when the data doesn't follow the model exactly but another, slightly different, "going towards" ?
We're looking at:  ,
,
which is the one-sided directional derivative of  at , in the direction of
at , in the direction of  .
.
Let  .
. 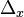 is the probability measure which gives mass 1 to
is the probability measure which gives mass 1 to  . We choose
. We choose 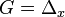 . The influence function is then defined by:
. The influence function is then defined by:

It describes the effect of an infinitesimal contamination at the point on the estimate we are seeking, standardized by the mass  of the contamination (the asymptotic bias caused by contamination in the observations). For a robust estimator, we want a bounded influence function, that is, one which does not go to infinity as x becomes arbitrarily large.
of the contamination (the asymptotic bias caused by contamination in the observations). For a robust estimator, we want a bounded influence function, that is, one which does not go to infinity as x becomes arbitrarily large.
Desirable properties
Properties of an influence function which bestow it with desirable performance are:
- Finite rejection point
 ,
, - Small gross-error sensitivity
 ,
, - Small local-shift sensitivity
 .
.
Rejection point

Gross-error sensitivity

Local-shift sensitivity

This value, which looks a lot like a Lipschitz constant, represents the effect of shifting an observation slightly from to a neighbouring point 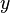 , i.e., add an observation at and remove one at .
, i.e., add an observation at and remove one at .
M-estimators
(The mathematical context of this paragraph is given in the section on empirical influence functions.)
Historically, several approaches to robust estimation were proposed, including R-estimators and L-estimators. However, M-estimators now appear to dominate the field as a result of their generality, high breakdown point, and their efficiency. See Huber (1981).
M-estimators are a generalization of maximum likelihood estimators (MLEs). What we try to do with MLE's is to maximize  or, equivalently, minimize
or, equivalently, minimize  . In 1964, Huber proposed to generalize this to the minimization of
. In 1964, Huber proposed to generalize this to the minimization of 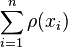 , where
, where  is some function. MLE are therefore a special case of M-estimators (hence the name: "Maximum likelihood type" estimators).
is some function. MLE are therefore a special case of M-estimators (hence the name: "Maximum likelihood type" estimators).
Minimizing can often be done by differentiating and solving  , where
, where 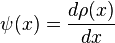 (if has a derivative).
(if has a derivative).
Several choices of and 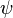 have been proposed. The two figures below show four functions and their corresponding functions.
have been proposed. The two figures below show four functions and their corresponding functions.

For squared errors,  increases at an accelerating rate, whilst for absolute errors, it increases at a constant rate. When Winsorizing is used, a mixture of these two effects is introduced: for small values of x, increases at the squared rate, but once the chosen threshold is reached (1.5 in this example), the rate of increase becomes constant. This Winsorised estimator is also known as the Huber loss function.
increases at an accelerating rate, whilst for absolute errors, it increases at a constant rate. When Winsorizing is used, a mixture of these two effects is introduced: for small values of x, increases at the squared rate, but once the chosen threshold is reached (1.5 in this example), the rate of increase becomes constant. This Winsorised estimator is also known as the Huber loss function.
Tukey's biweight (also known as bisquare) function behaves in a similar way to the squared error function at first, but for larger errors, the function tapers off.

Properties of M-estimators
Notice that M-estimators do not necessarily relate to a probability density function. Therefore, off-the-shelf approaches to inference that arise from likelihood theory can not, in general, be used.
It can be shown that M-estimators are asymptotically normally distributed, so that as long as their standard errors can be computed, an approximate approach to inference is available.
Since M-estimators are normal only asymptotically, for small sample sizes it might be appropriate to use an alternative approach to inference, such as the bootstrap. However, M-estimates are not necessarily unique (i.e., there might be more than one solution that satisfies the equations). Also, it is possible that any particular bootstrap sample can contain more outliers than the estimator's breakdown point. Therefore, some care is needed when designing bootstrap schemes.
Of course, as we saw with the speed of light example, the mean is only normally distributed asymptotically and when outliers are present the approximation can be very poor even for quite large samples. However, classical statistical tests, including those based on the mean, are typically bounded above by the nominal size of the test. The same is not true of M-estimators and the type I error rate can be substantially above the nominal level.
These considerations do not "invalidate" M-estimation in any way. They merely make clear that some care is needed in their use, as is true of any other method of estimation.
Influence function of an M-estimator
It can be shown that the influence function of an M-estimator is proportional to (see Huber, 1981 (and 2004), page 45), which means we can derive the properties of such an estimator (such as its rejection point, gross-error sensitivity or local-shift sensitivity) when we know its function.
 with the
with the  given by:
given by:
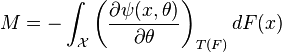 .
.
Choice of ψ and ρ
In many practical situations, the choice of the function is not critical to gaining a good robust estimate, and many choices will give similar results that offer great improvements, in terms of efficiency and bias, over classical estimates in the presence of outliers (Huber, 1981).
Theoretically, functions are to be preferred, and Tukey's biweight (also known as bisquare) function is a popular choice. Maronna et al. (2006) recommend the biweight function with efficiency at the normal set to 85%.
Robust parametric approaches
M-estimators do not necessarily relate to a density function and so are not fully parametric. Fully parametric approaches to robust modeling and inference, both Bayesian and likelihood approaches, usually deal with heavy tailed distributions such as Student's t-distribution.
For the t-distribution with 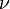 degrees of freedom, it can be shown that
degrees of freedom, it can be shown that
 .
.
For  , the t-distribution is equivalent to the Cauchy distribution. Notice that the degrees of freedom is sometimes known as the kurtosis parameter. It is the parameter that controls how heavy the tails are. In principle, can be estimated from the data in the same way as any other parameter. In practice, it is common for there to be multiple local maxima when is allowed to vary. As such, it is common to fix at a value around 4 or 6. The figure below displays the -function for 4 different values of .
, the t-distribution is equivalent to the Cauchy distribution. Notice that the degrees of freedom is sometimes known as the kurtosis parameter. It is the parameter that controls how heavy the tails are. In principle, can be estimated from the data in the same way as any other parameter. In practice, it is common for there to be multiple local maxima when is allowed to vary. As such, it is common to fix at a value around 4 or 6. The figure below displays the -function for 4 different values of .

Example: speed of light data
For the speed of light data, allowing the kurtosis parameter to vary and maximizing the likelihood, we get

Fixing  and maximizing the likelihood gives
and maximizing the likelihood gives

Related concepts
A pivotal quantity is a function of data, whose underlying population distribution is a member of a parametric family, that is not dependent on the values of the parameters. An ancillary statistic is such a function that is also a statistic, meaning that it is computed in terms of the data alone. Such functions are robust to parameters in the sense that they are independent of the values of the parameters, but not robust to the model in the sense that they assume an underlying model (parametric family), and in fact such functions are often very sensitive to violations of the model assumptions. Thus test statistics, frequently constructed in terms of these to not be sensitive to assumptions about parameters, are still very sensitive to model assumptions.
Replacing outliers and missing values
If there are relatively few missing points, there are some models which can be used to estimate values to complete the series, such as replacing missing values with the mean or median of the data. Simple linear regression can also be used to estimate missing values (MacDonald and Zucchini, 1997; Harvey, 1989). In addition, outliers can sometimes be accommodated in the data through the use of trimmed means, other scale estimators apart from standard deviation (e.g., MAD) and Winsorization (McBean and Rovers, 1998). In calculations of a trimmed mean, a fixed percentage of data is dropped from each end of an ordered data, thus eliminating the outliers. The mean is then calculated using the remaining data. Winsorizing involves accommodating an outlier by replacing it with the next highest or next smallest value as appropriate (Rustum & Adeloye, 2007).[6]
However, using these types of models to predict missing values or outliers in a long time series is difficult and often unreliable, particularly if the number of values to be in-filled is relatively high in comparison with total record length. The accuracy of the estimate depends on how good and representative the model is and how long the period of missing values extends (Rosen and Lennox, 2001). The in a case of a dynamic process, so any variable is dependent, not just on the historical time series of the same variable but also on several other variables or parameters of the process. In other words, the problem is an exercise in multivariate analysis rather than the univariate approach of most of the traditional methods of estimating missing values and outliers; a multivariate model will therefore be more representative than a univariate one for predicting missing values. The kohonin self organising map (KSOM) offers a simple and robust multivariate model for data analysis, thus providing good possibilities to estimate missing values, taking into account its relationship or correlation with other pertinent variables in the data record (Rustum & Adeloye 2007).
Standard Kalman filters are not robust to outliers. To this end Ting, Theodorou and Schaal have recently shown that a modification of Masreliez's theorem can deal with outliers.[7]
One common approach to handle outliers in data analysis is to perform outlier detection first, followed by an efficient estimation method (e.g., the least squares). While this approach is often useful, one must keep in mind two challenges. First, an outlier detection method that relies on a non-robust initial fit can suffer from the effect of masking, that is, a group of outliers can mask each other and escape detection (Rousseeuw and Leroy, 2007). Second, if a high breakdown initial fit is used for outlier detection, the follow-up analysis might inherit some of the inefficiencies of the initial estimator (He and Portnoy, 1992).
See also
References
- 1 2 3 Robust Statistics, Peter J. Huber, Wiley, 1981 (republished in paperback, 2004), page 1.
- ↑ When was the ozone hole discovered, Weather Undergroundhttp://www.wunderground.com/climate/holefaq.asp
- ↑ Resistant statistics, David B. Stephenson
- ↑ See Ollina and Koivunen http://cc.oulu.fi/~esollila/papers/ssp03fin.pdf
- ↑ Mises, R. V. (1947). On the asymptotic distribution of differentiable statistical functions. The annals of mathematical statistics, 309-348.
- ↑ Rustum R., and A. J. Adeloye (2007); Replacing outliers and missing values from activated sludge data using Kohonen Self Organizing Map, Journal of Environmental Engineering, 133 (9), 909-916.
- ↑ Jo-anne Ting, Evangelos Theodorou and Stefan Schaal; "A Kalman filter for robust outlier detection", International Conference on Intelligent Robots and Systems - IROS , pp. 1514-1519 (2007).
- Robust Statistics - The Approach Based on Influence Functions, Frank R. Hampel, Elvezio M. Ronchetti, Peter J. Rousseeuw and Werner A. Stahel, Wiley, 1986 (republished in paperback, 2005)
- Robust Statistics, Peter J. Huber, Wiley, 1981 (republished in paperback, 2004)
- Robust Regression and Outlier Detection, Peter J. Rousseeuw and Annick M. Leroy, Wiley, 1987 (republished in paperback, 2003)
- Hettmansperger, T. P.; McKean, J. W. (1998). Robust nonparametric statistical methods. Kendall's Library of Statistics 5 (First ed.). New York: John Wiley & Sons, Inc. pp. xiv+467 pp. ISBN 0-340-54937-8. MR 1604954
- Robust Statistics - Theory and Methods, Ricardo Maronna, R. Douglas Martin and Victor Yohai, Wiley, 2006
- Rousseeuw, P.J. and Croux, C. "Alternatives to the Median Absolute Deviation," Journal of the American Statistical Association 88 (1993), 1273
- Press, WH; Teukolsky, SA; Vetterling, WT; Flannery, BP (2007), "Section 15.7. Robust Estimation", Numerical Recipes: The Art of Scientific Computing (3rd ed.), New York: Cambridge University Press, ISBN 978-0-521-88068-8
- He, X. and Portnoy, S. "Reweighted LS Estimators Converge at the same Rate as the Initial Estimator," Annals of Statistics Vol. 20, No. 4 (1992), 2161–2167
- He, X., Simpson, D.G. and Portnoy, S. "Breakdown Robustness of Tests," Journal of the American Statistical Association Vol. 85, No. 40, (1990), 446-452
- Portnoy S. and He, X. "A Robust Journey in the New Millennium," Journal of the American Statistical Association Vol. 95, No. 452 (Dec., 2000), 1331–1335
- Stephen M. Stigler. "The Changing History of Robustness," The American Statistician November 1, 2010, 64(4): 277-281. doi:10.1198/tast.2010.10159
- Wilcox, R. "Introduction to Robust Estimation & Hypothesis Testing," Academic Press, 201
External links
- Brian Ripley's robust statistics course notes.
- Nick Fieller's course notes on Statistical Modelling and Computation contain material on robust regression.
- David Olive's site contains course notes on robust statistics and some data sets.
- Online experiments using R and JSXGraph