Remez algorithm
The Remez algorithm or Remez exchange algorithm, published by Evgeny Yakovlevich Remez in 1934,[1] is an iterative algorithm used to find simple approximations to functions, specifically, approximations by functions in a Chebyshev space that are the best in the uniform norm L∞ sense.
A typical example of a Chebyshev space is the subspace of Chebyshev polynomials of order n in the space of real continuous functions on an interval, C[a, b]. The polynomial of best approximation within a given subspace is defined to be the one that minimizes the maximum absolute difference between the polynomial and the function. In this case, the form of the solution is precised by the equioscillation theorem.
Procedure
The Remez algorithm starts with the function f to be approximated and a set X of  sample points
sample points  in the approximation interval, usually the Chebyshev nodes linearly mapped to the interval. The steps are:
in the approximation interval, usually the Chebyshev nodes linearly mapped to the interval. The steps are:
- Solve the linear system of equations
 (where
(where  ),
),- for the unknowns
 and E.
and E.
- Use the
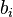 as coefficients to form a polynomial
as coefficients to form a polynomial  .
. - Find the set M of points of local maximum error
 .
. - If the errors at every
 are of equal magnitude and alternate in sign, then is the minimax approximation polynomial. If not, replace E with M and repeat the steps above.
are of equal magnitude and alternate in sign, then is the minimax approximation polynomial. If not, replace E with M and repeat the steps above.
The result is called the polynomial of best approximation, the Chebyshev approximation, or the minimax approximation.
A review of technicalities in implementing the Remez algorithm is given by W. Fraser.[2]
On the choice of initialization
The Chebyshev nodes are a common choice for the initial approximation because of their role in the theory of polynomial interpolation. For the initialization of the optimization problem for function f by the Lagrange interpolant Ln(f), it can be shown that this initial approximation is bounded by

with the norm or Lebesgue constant of the Lagrange interpolation operator Ln of the nodes (t1, ..., tn + 1) being

T being the zeros of the Chebyshev polynomials, and the Lebesgue functions being

Theodore A. Kilgore,[3] Carl de Boor, and Allan Pinkus[4] proved that there exists a unique ti for each Ln, although not known explicitly for (ordinary) polynomials. Similarly,  , and the optimality of a choice of nodes can be expressed as
, and the optimality of a choice of nodes can be expressed as 
For Chebyshev nodes, which provides a suboptimal, but analytically explicit choice, the asymptotic behavior is known as[5]

(γ being the Euler-Mascheroni constant) with
 for
for 
and upper bound[6]

Lev Brutman[7] obtained the bound for  , and
, and  being the zeros of the expanded Chebyshev polynomials:
being the zeros of the expanded Chebyshev polynomials:

Rüdiger Günttner[8] obtained from a sharper estimate for 

Detailed discussion
This section provides more information on the steps outlined above. In this section, the index i runs from 0 to n+1.
Step 1: Given  , solve the linear system of n+2 equations
, solve the linear system of n+2 equations
- (where
 ),
), - for the unknowns
 and E.
and E.
It should be clear that  in this equation makes sense only if the nodes
in this equation makes sense only if the nodes  are ordered, either strictly increasing or strictly decreasing. Then this linear system has a unique solution. (As is well known, not every linear system has a solution.) Also, the solution can be obtained with only
are ordered, either strictly increasing or strictly decreasing. Then this linear system has a unique solution. (As is well known, not every linear system has a solution.) Also, the solution can be obtained with only  arithmetic operations while a standard solver from the library would take
arithmetic operations while a standard solver from the library would take  operations. Here is the simple proof:
operations. Here is the simple proof:
Compute the standard n-th degree interpolant  to
to 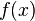 at the first n+1 nodes and also the standard n-th degree interpolant
at the first n+1 nodes and also the standard n-th degree interpolant
 to the ordinates
to the ordinates 

To this end, use each time Newton's interpolation formula with the divided
differences of order  and arithmetic operations.
and arithmetic operations.
The polynomial has its i-th zero between  and
and  , and thus no further zeroes between
, and thus no further zeroes between 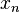 and
and  :
:  and
and  have the same sign
have the same sign  .
.
The linear combination
 is also a polynomial of degree n and
is also a polynomial of degree n and

This is the same as the equation above for  and for any choice of E.
The same equation for i = n+1 is
and for any choice of E.
The same equation for i = n+1 is
 and needs special reasoning: solved for the variable E, it is the definition of E:
and needs special reasoning: solved for the variable E, it is the definition of E:
As mentioned above, the two terms in the denominator have same sign:
E and thus  are always well-defined.
are always well-defined.
The error at the given n+2 ordered nodes is positive and negative in turn because

The theorem of de La Vallée Poussin states that under this condition no polynomial of degree n exists with error less than E. Indeed, if such a polynomial existed, call it  , then the difference
, then the difference
 would still be positive/negative at the n+2 nodes
would still be positive/negative at the n+2 nodes  and therefore have at least n+1 zeros which is impossible for a polynomial of degree n.
Thus, this E is a lower bound for the minimum error which can be achieved with polynomials of degree n.
and therefore have at least n+1 zeros which is impossible for a polynomial of degree n.
Thus, this E is a lower bound for the minimum error which can be achieved with polynomials of degree n.
Step 2 changes the notation from
 to
to 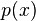 .
.
Step 3 improves upon the input nodes and their errors  as follows.
as follows.
In each P-region, the current node is replaced with the local maximizer  and in each N-region is replaced with the local minimizer. (Expect
and in each N-region is replaced with the local minimizer. (Expect  at A, the near , and
at A, the near , and  at B.) No high precision is required here,
the standard line search with a couple of quadratic fits should suffice. (See [9])
at B.) No high precision is required here,
the standard line search with a couple of quadratic fits should suffice. (See [9])
Let  . Each amplitude
. Each amplitude  is greater than or equal to E. The Theorem of de La Vallée Poussin and its proof also
apply to
is greater than or equal to E. The Theorem of de La Vallée Poussin and its proof also
apply to  with
with  as the new
lower bound for the best error possible with polynomials of degree n.
as the new
lower bound for the best error possible with polynomials of degree n.
Moreover,  comes in handy as an obvious upper bound for that best possible error.
comes in handy as an obvious upper bound for that best possible error.
Step 4: With  and
and  as lower and upper bound for the best possible approximation error, one has a reliable stopping criterion: repeat the steps until
as lower and upper bound for the best possible approximation error, one has a reliable stopping criterion: repeat the steps until  is sufficiently small or no longer decreases. These bounds indicate the progress.
is sufficiently small or no longer decreases. These bounds indicate the progress.
Variants
Sometimes more than one sample point is replaced at the same time with the locations of nearby maximum absolute differences.
Sometimes relative error is used to measure the difference between the approximation and the function, especially if the approximation will be used to compute the function on a computer which uses floating point arithmetic.
See also
Notes
- ↑ E. Ya. Remez, "Sur la détermination des polynômes d'approximation de degré donnée", Comm. Soc. Math. Kharkov 10, 41 (1934);
"Sur un procédé convergent d'approximations successives pour déterminer les polynômes d'approximation, Compt. Rend. Acad. Sc. 198, 2063 (1934);
"Sur le calcul effectiv des polynômes d'approximation des Tschebyscheff", Compt. Rend. Acade. Sc. 199, 337 (1934). - ↑ Fraser, W. (1965). "A Survey of Methods of Computing Minimax and Near-Minimax Polynomial Approximations for Functions of a Single Independent Variable". J. ACM 12: 295. doi:10.1145/321281.321282.
- ↑ Kilgore, T. A. (1978). "A characterization of the Lagrange interpolating projection with minimal Tchebycheff norm". J. Approx. Theory 24: 273. doi:10.1016/0021-9045(78)90013-8.
- ↑ de Boor, C.; Pinkus, A. (1978). "Proof of the conjectures of Bernstein and Erdös concerning the optimal nodes for polynomial interpolation". Journal of Approximation Theory 24: 289. doi:10.1016/0021-9045(78)90014-X.
- ↑ Luttmann, F. W.; Rivlin, T. J. (1965). "Some numerical experiments in the theory of polynomial interpolation". IBM J. Res. Develop. 9: 187. doi:10.1147/rd.93.0187.
- ↑ T. Rivlin, "The Lebesgue constants for polynomial interpolation", in Proceedings of the Int. Conf. on Functional Analysis and Its Application, edited by H. G. Garnier et al. (Springer-Verlag, Berlin, 1974), p. 422; The Chebyshev polynomials (Wiley-Interscience, New York, 1974).
- ↑ Brutman, L. (1978). "On the Lebesgue Function for Polynomial Interpolation". SIAM J. Numer. Anal. 15: 694. doi:10.1137/0715046.
- ↑ Günttner, R. (1980). "Evaluation of Lebesgue Constants". SIAM J. Numer. Anal. 17: 512. doi:10.1137/0717043.
- ↑ David G. Luenberger: Introduction to Linear and Nonlinear Programming, Addison-Wesley Publishing Company 1973.
External links
- Intro to DSP
- Aarts, Ronald M.; Bond, Charles; Mendelsohn, Phil; and Weisstein, Eric W., "Remez Algorithm", MathWorld.