Register allocation
In compiler optimization, register allocation is the process of assigning a large number of target program variables onto a small number of CPU registers. Register allocation can happen over a basic block (local register allocation), over a whole function/procedure (global register allocation), or across function boundaries traversed via call-graph (interprocedural register allocation). When done per function/procedure the calling convention may require insertion of save/restore around each call-site.
Introduction
In many programming languages, the programmer has the illusion of allocating arbitrarily many variables. However, during compilation, the compiler must decide how to allocate these variables to a small, finite set of registers. Not all variables are in use (or "live") at the same time, so some registers may be assigned to more than one variable. However, two variables in use at the same time cannot be assigned to the same register without corrupting its value. Variables which cannot be assigned to some register must be kept in RAM and loaded in/out for every read/write, a process called spilling. Accessing RAM is significantly slower than accessing registers and slows down the execution speed of the compiled program, so an optimizing compiler aims to assign as many variables to registers as possible. Register pressure is the term used when there are fewer hardware registers available than would have been optimal; higher pressure usually means that more spills and reloads are needed.
In addition, programs can be further optimized by assigning the same register to a source and destination of a move instruction whenever possible. This is especially important if the compiler is using other optimizations such as SSA analysis, which artificially generates additional move instructions in the intermediate code.
Spilling
In most register allocators, each variable is assigned to either a CPU register or to main memory. The advantage of using a register is speed. Computers have a limited number of registers, so not all variables can be assigned to registers. A "spilled variable" is a variable in main memory rather than in a CPU register. The operation of moving a variable from a register to memory is called spilling, while the reverse operation of moving a variable from memory to a register is called filling. For example, a 32-bit variable spilled to memory gets 32 bits of stack space allocated and all references to the variable are then to that memory. Such a variable has a much slower processing speed than a variable in a register. When deciding which variables to spill, multiple factors are considered: execution time, code space, data space.
Isomorphism to graph colorability
Through liveness analysis, compilers can determine which sets of variables are live at the same time, as well as variables which are involved in move instructions. Using this information, the compiler can construct a graph such that every vertex represents a unique variable in the program. Interference edges connect pairs of vertices which are live at the same time, and preference edges connect pairs of vertices which are involved in move instructions. Register allocation can then be reduced to the problem of K-coloring the resulting graph, where K is the number of registers available on the target architecture. No two vertices sharing an interference edge may be assigned the same color, and vertices sharing a preference edge should be assigned the same color if possible. Some of the vertices may be precolored to begin with, representing variables which must be kept in certain registers due to calling conventions or communication between modules. As graph coloring in general is NP-complete, so is register allocation. However, good algorithms exist which balance performance with quality of compiled code.
It may be the case that the graph coloring algorithm fails to find a coloring of the interference graph. In this case, some of the variables must be spilled to memory in order to enable the remaining variables to be allocated to registers. This may be accomplished by a recursive search that tries spilling one variable and then recursively either colors the remaining set of variables or continues spilling recursively until all remaining unspilled variables can be colored and assigned to registers.
Iterated Register Coalescing
Register allocators have several types, with Iterated Register Coalescing (IRC) being a more common one. IRC was invented by LAL George and Andrew Appel in 1996, building on earlier work by Gregory Chaitin. IRC works based on a few principles. First, if there are any non-move related vertices in the graph with degree less than K the graph can be simplified by removing those vertices, since once those vertices are added back in it is guaranteed that a color can be found for them (simplification). Second, two vertices sharing a preference edge whose adjacency sets combined have a degree less than K can be combined into a single vertex, by the same reasoning (coalescing). If neither of the two steps can simplify the graph, simplification can be run again on move-related vertices (freezing). Finally, if nothing else works, vertices can be marked for potential spilling and removed from the graph (spill). Since all of these steps reduce the degrees of vertices in the graph, vertices may transform from being high-degree (degree > K) to low-degree during the algorithm, enabling them to be simplified or coalesced. Thus, the stages of the algorithm are iterated to ensure aggressive simplification and coalescing. The pseudo-code is thus:
function IRC_color g K : repeat if ∃v s.t. ¬moveRelated(v) ∧ degree(v) < K then simplify v else if ∃e s.t. cardinality(neighbors(first e) ∪ neighbors(second e)) < K then coalesce e else if ∃v s.t. moveRelated(v) then deletePreferenceEdges v else if ∃v s.t. ¬precolored(v) then spill v else return loop
The coalescing done in IRC is conservative, because aggressive coalescing may introduce spills into the graph. However, additional coalescing heuristics such as George coalescing may coalesce more vertices while still ensuring that no additional spills are added. Work-lists are used in the algorithm to ensure that each iteration of IRC requires sub-quadratic time.
Recent developments
Graph coloring allocators produce efficient code, but their allocation time is high. In cases of static compilation, allocation time is not a significant concern. In cases of dynamic compilation, such as just-in-time (JIT) compilers, fast register allocation is important. An efficient technique proposed by Poletto and Sarkar is linear scan allocation. This technique requires only a single pass over the list of variable live ranges. Ranges with short lifetimes are assigned to registers, whereas those with long lifetimes tend to be spilled, or reside in memory. The results are on average only 12% less efficient than graph coloring allocators.
The linear scan algorithm follows:
- Perform dataflow analysis to gather liveness information. Keep track of all variables’ live intervals, the interval when a variable is live, in a list sorted in order of increasing start point (note that this ordering is free if the list is built when computing liveness.) We consider variables and their intervals to be interchangeable in this algorithm.
- Iterate through liveness start points and allocate a register from the available register pool to each live variable.
- At each step maintain a list of active intervals sorted by the end point of the live intervals. (Note that insertion sort into a balanced binary tree can be used to maintain this list at linear cost.) Remove any expired intervals from the active list and free the expired interval’s register to the available register pool.
- In the case where the active list is size R we cannot allocate a register. In this case add the current interval to the active pool without allocating a register. Spill the interval from the active list with the furthest end point. Assign the register from the spilled interval to the current interval or, if the current interval is the one spilled, do not change register assignments.
Cooper and Dasgupta recently developed a "lossy" Chaitin-Briggs graph coloring algorithm suitable for use in a JIT.[1] The "lossy" moniker refers to the imprecision the algorithm introduces into the interference graph. This optimization reduces the costly graph building step of Chaitin-Briggs making it suitable for runtime compilation. Experiments indicate that this lossy register allocator outperforms linear scan on the majority of tests used.
"Optimal" register allocation algorithms based on Integer Programming have been developed by Goodwin and Wilken for regular architectures. These algorithms have been extended to irregular architectures by Kong and Wilken.
While the worst case execution time is exponential, the experimental results show that the actual time is typically of order 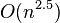 of the number of constraints
of the number of constraints  .[2]
.[2]
The possibility of doing register allocation on SSA-form programs is a focus of recent research.[3] The interference graphs of SSA-form programs are chordal, and as such, they can be colored in polynomial time. To clarify the sources of NP-completeness, recent research has examined register allocation in a broader context.[4][5]
See also
- Strahler number, the minimum number of registers needed to evaluate an expression tree.[6]
References
- ↑ Cooper, Dasgupta, "Tailoring Graph-coloring Register Allocation For Runtime Compilation", http://llvm.org/pubs/2006-04-04-CGO-GraphColoring.html
- ↑ Kong, Wilken, "Precise Register Allocation for Irregular Architectures", http://www.ece.ucdavis.edu/cerl/cerl_arch/irreg.pdf
- ↑ Brisk, Hack, Palsberg, Pereira, Rastello, "SSA-Based Register Allocation", ESWEEK Tutorial http://thedude.cc.gt.atl.ga.us/tutorials/1/
- ↑ Bouchez, Florent; Darte, Alain; Guillon, Christophe; Rastello, Fabrice (2007), "Register Allocation: What Does the NP-Completeness Proof of Chaitin et al. Really Prove? Or Revisiting Register Allocation: Why and How", Languages and Compilers for Parallel Computing, Lecture Notes in Computer Science 4382: 283–298
- ↑ Bouchez, Florent; Darte, Alain; Rastello, Fabrice (March 2006), Register Allocation: What does Chaitin’s NP-completeness Proof Really Prove? (PDF), Laboratoire de l’Informatique du Parallelisme, 2006-13; also http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.130.7256 Proceedings of the 19th International Workshop on Languages and Compilers for Parallel Computing, 2006, pages 2–4.
- ↑ Flajolet, P.; Raoult, J. C.; Vuillemin, J. (1979), "The number of registers required for evaluating arithmetic expressions", Theoretical Computer Science 9 (1): 99–125, doi:10.1016/0304-3975(79)90009-4.
| ||||||||||
| ||||||||||||||||||||||||||||||||||||||