Referring expression generation
Referring expression generation(REG) is the subtask of Natural language generation (NLG) that received most scholarly attention. While NLG is concerned with the conversion of non-linguistic information into natural language, REG focuses only on the creation of referring expressions (noun phrases) that identify specific entities called targets.
This task can be split into two sections. The content selection part determines which set of properties distinguish the intended target and the linguistic realization part defines how these properties are translated into natural language. A variety of algorithms have been developed in the NLG community to generate different types of referring expressions.
Types of referring expressions
A referring expression (RE), in linguistics, is any noun phrase, or surrogate for a noun phrase, whose function in discourse is to identify some individual object (thing, being, event...) The technical terminology for identify differs a great deal from one school of linguistics to another. The most widespread term is probably refer, and a thing identified is a referent, as for example in the work of John Lyons. In linguistics, the study of reference relations belongs to pragmatics, the study of language use, though it is also a matter of great interest to philosophers, especially those wishing to understand the nature of knowledge, perception and cognition more generally.
Various devices can be used for reference: determiners, pronouns, proper names... Reference relations can be of different kinds; referents can be in a "real" or imaginary world, in discourse itself, and they may be singular, plural, or collective.
Pronouns
The simplest type of referring expressions are pronoun such as he and it. The linguistics and natural language processing communities have developed various models for predicting anaphor referents, such as centering theory,[1] and ideally referring-expression generation would be based on such models. However most NLG systems use much simpler algorithms, for example using a pronoun if the referent was mentioned in the previous sentence (or sentential clause), and no other entity of the same gender was mentioned in this sentence.
Definite Noun Phrases
There has been a considerable amount of research on generating definite noun phrases, such as the big red book. Much of this builds on the model proposed by Dale and Reiter.[2] This has been extended in various ways, for example Krahmer et al. [3] present a graph-theoretic model of definite NP generation with many nice properties. In recent years a shared-task event has compared different algorithms for definite NP generation, using the TUNA corpus.
Spatial and Temporal Reference
Recently there has been more research on generating referring expressions for time and space. Such references tend to be imprecise (what is the exact meaning of tonight?), and also to be interpreted in different ways by different people.[4] Hence it may be necessary to explicitly reason about false positive vs false negative tradeoffs, and even calculate the utility of different possible referring expressions in a particular task context [5]
Criteria for good expressions
Ideally, a good referring expression should satisfy a number of criteria:
- Referential success: It should unambiguously identify the referent to the reader.
- Ease of comprehension: The reader should be able to quickly read and understand it.
- Computational complexity: The generation algorithm should be fast
- No false inferences: The expression should not confuse or mislead the reader by suggesting false implicatures or other pragmatic inferences. For example, a reader may be confused if he is told Sit by the brown wooden table in a context where there is only one table.[2]
History
Pre-2000 era
REG goes back to the early days of NLG. One of the first approaches was done by Winograd[6] in 1972 who developed an "incremental" REG algorithm for his SHRDLU program. Afterwards researchers started to model the human abilities to create referring expressions in the 1980s. This new approach to the topic was influenced by the researchers Appelt and Kronfeld who created the programs KAMP and BERTRAND[7][8][9] and considered referring expressions as parts of bigger speech acts.
Some of their most interesting findings were the fact that referring expressions can be used to add information beyond the identification of the referent[8] as well as the influence of communicative context and the Gricean maxims on referring expressions.[7] Furthermore its skepticism concerning the naturalness of minimal descriptions made Appelt and Kronfeld's research a foundation of later work on REG.
The search for simple, well-defined problems changed the direction of research in the early 1990s. This new approach was led by Dale and Reiter who stressed the identification of the referent as the central goal.[10][11][12][13] Like Appelt[7] they discuss the connection between the Gricean maxims and referring expressions in their culminant paper[2] in which they also propose a formal Problem Definition. Furthermore Reiter and Dale discuss the Full Brevity and Greedy Heuristics algorithms as well as their Incremental Algorithm(IA) which became one of the most important algorithms in REG. [note 1]
Later developments
After 2000 the research began to lift some of the simplifying assumptions, that had been made in early REG research in order to create more simple algorithms. Different research groups concentrated on different limitations creating several expanded algorithms. Often these extend the IA in a single perspective for example in relation to:
- Reference to Sets like "the t-shirt wearers" or "the green apples and the banana on the left"[14][15][16][17]
- Relational Descriptions like "the cup on the table" or "the woman who has three children"[18][19][20][21][22]
- Context Dependency, Vagueness and Gradeability include statements like "the older man" or "the car on the left" which are often unclear without a context[23][24][5]
- Salience and Generation of Pronouns are highly discourse dependent making for example "she" a reference to "the (most salient) female person"[25][26][27][28][29][30][31]
Many simplifying assumptions are still in place or have just begun to be worked on. Also a combination of the different extensions has yet to be done and is called a "non-trivial enterprise" by Krahmer and van Deemter.[32]
Another important change after 2000 was the increasing use of empirical studies in order to evaluate algorithms. This development took place due to the emergence of transparent corpora. Although there are still discussions about what the best evaluation metrics are, the use of experimental evaluation has already led to a better comparability of algorithms, a discussion about the goals of REG and more task-oriented research.
Furthermore research has extended its range to related topics such as the choice of Knowledge Representation(KR) Frameworks. In this area the main question, which KR framework is most suitable for the use in REG remains open. The answer to this question depends on how well descriptions can be expressed or found. A lot of the potential of KR frameworks has been left unused so far.
Some of the different approaches are the usage of:
- Graph Search which treats relations between targets in the same way as properties.[3][20][22][33][34]
- Constraint Satisfaction which allows for a separation between problem specification and the implementation.[18][35]
- Modern Knowledge Representation which offers logical inference in for example Description Logic or Conceptual Graphs.[36][37][38]
Problem Definition
Dale and Reiter (1995) think about referring expressions as distinguishing descriptions.
They define:
- The referent as the entity that should be described
- The context set as set of salient entities
- The contrast set or potential distractors as all elements of the context set except the referent
- A property as a reference to a single attribute-value pair
Each entity in the domain can be characterised as a set of attribute-value pairs for example 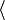 type, dog
type, dog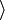 , gender, female or age, 10 years.
, gender, female or age, 10 years.
The problem then is defined as follows:
Let  be the intended referent, and
be the intended referent, and 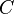 be the contrast set. Then, a set
be the contrast set. Then, a set  of attribute–value pairs will represent a distinguishing description if the following two conditions hold:
of attribute–value pairs will represent a distinguishing description if the following two conditions hold:
- Every attribute–value pair in applies to : that is, every element of specifies an attribute–value that possesses.
- For every member
 of , there is at least one element
of , there is at least one element 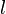 of that does not apply to : that is, there is an in that specifies an attribute–value that does not possess. is said to rule out .
of that does not apply to : that is, there is an in that specifies an attribute–value that does not possess. is said to rule out .
In other words to generate a referring expression one is looking for a set of properties that apply to the referent but not to the distractors. [2]
The problem could be easily solved by conjoining all the properties of the referent which often leads to long descriptions violating the second Gricean Maxim of Quantity. Another approach would be to find the shortest distinguishing description like the Full Brevity algorithm does. Yet in practice it is most common to instead include the condition that referring expressions produced by an algorithm should be as similar to human-produced ones as possible although this is often not explicitly mentioned. [note 1]
Basic Algorithms
Full Brevity
The Full Brevity algorithm always finds a minimal distinguishing description meaning there is no shorter distinguishing description in regard to properties used.
Therefore it iterates over 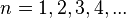 and checks every description of a length of
and checks every description of a length of  properties until a distinguishing description is found.
properties until a distinguishing description is found.
Two problems arise from this way of creating referring expressions. Firstly the algorithm has a high complexity meaning it is NP-hard which makes it impractical to use.[39] Secondly human speakers produce descriptions that are not minimal in many situations.[40][41][42][43] [note 1]
Greedy Heuristics
The Greedy Heuristics algorithm [10][11] approximates the Full Brevity algorithm by iteratively adding the most distinguishing property to the description. The most distinguishing property means the property that rules out most of the remaining distractors. The Greedy Heuristics algorithm is more efficient than the Full Brevity algorithm. [note 1]
Dale and Reiter(1995)[2] present the following algorithm for the Greedy Heuristic:
Let be the set of properties to be realised in our description; let  be the set of properties known to be true of our intended referent (we assume that is non-empty); and let be the set of distractors (the contrast set). The initial conditions are thus as follows:
be the set of properties known to be true of our intended referent (we assume that is non-empty); and let be the set of distractors (the contrast set). The initial conditions are thus as follows:
all distractors
;
all properties true of
;
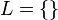
In order to describe the intended referent with respect to the contrast set , we do the
following:
1. Check Success: ifthen return
then fail else goto Step 2. 2. Choose Property: for each
do:
Chosen property is
, where
is the smallest set. goto Step 3. 3. Extend Description (wrt the chosen
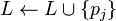

goto Step 1.
Incremental Algorithm
The Incremental Algorithm(IA) by Dale and Reiter[2] was the most influential algorithm before 2000. It is based on the idea of a preferential order of attributes or properties that speakers go by. So in order to run the Incremental Algorithm, first a preference order of attributes has to be given. Now the algorithm follows that order and adds those properties to the description which rule out any remaining distractors. Furthermore Dale and Reiter[2] stress the attribute type which is always included in their descriptions even if it does not rule out any distractors.
Also the type values are part of a subsumption hierarchy including some basic level values. For example in the pet domain chihuahua is subsumed by dog and dog by animal. Because dog is defined as a basic level dog would be preferred by the algorithms, if chihuahua does not rule out any distractors.
The Incremental Algorithm is easy to implement and also computationally efficient running in polynomial time. The description generated by the IA can contain redundant properties that are superfluous because of later added properties. The creators do not consider this as a weakness, but rather as making the expressions less "psycholinguistically implausible".[2]
The following algorithm is a simplified version of Dale and Reiter’s Incremental Algorithm[2] by Krahmer and van Deemter[32] that takes as input the referent r, the D containing a collection of domain objects and a domain-specific ordered list Pref of preferred attributes. In the notation L is the description, C the context set of distractors and the function RulesOut(⟨Ai, V⟩) returns the set of objects which have a value different to V for attribute Ai.
IncrementalAlgorithm ({r}, D, Pref){
L ← ∅
C ← D - {r}
for each Ai in list Pref do
V = Value(r, Ai)
if C ∩ RulesOut(⟨Ai, V⟩) ≠ ∅
then L ← L ∪ {⟨Ai, V⟩}
C ← C - RulesOut(⟨Ai, V⟩)
endif
if C ≠ ∅
then return L
endif
return failure }
Evaluation of REG systems
Before 2000 evaluation of REG systems has been of theoretical nature like the one done by Dale and Reiter.[2] More recently, empirical studies have become popular which are mostly based on the assumption that the generated expressions should be similar to human-produced ones. Corpus-based evaluation began quite late in REG due to a lack of suitable data sets. Still corpus-based evaluation is the most dominant method at the moment though there is also evaluation by human judgement. [note 1]
Corpus-based Evaluation
First the distinction between text corpora and experimental corpora has to be made. Text corpora like the GNOME corpus [1] can contain texts from all kind of domains. In REG they are used to evaluate the realization part of algorithms. The content selection part of REG on the other hand requires a corpus that contains the properties of all domain objects as well as the properties used in references. Typically those fully "semantically transparent"[44] created in experiments using simple and controlled settings.
These experimental corpora once again can be separated into General-Purpose Corpora that were collected for another purpose but have been analysed for referring expressions and Dedicated Corpora that focus specifically on referring expressions. Examples of General-Purpose Corpora are the Pear Stories,[45] the Map Task corpus[46] or the Coconut corpus[47] while the Bishop corpus,[48] the Drawer corpus[49] and the TUNA corpus[50] count to the Dedicated Corpora. The TUNA corpus which contains web-collected data on the two domains furniture and people has been used in three shared REG challenges already. [note 1]
Evaluation Metrics
To measure the correspondence between corpora and the results of REG algorithms several Metrics have been developed.
To measure the content selection part the Dice coefficient[51] or the MASI (Measuring Agreement on Set-valued Items)[52] metric are used. These measure the overlap of properties in two descriptions. In an evaluation the scores are usually averaged over references made by different human participants in the corpus. Also sometimes a measure called Perfect Recall Percentage (PRP)[50] or Accuracy[53] is used which calculates the percentage of perfect matches between an algorithm-produced and a human-produced reference.
For the linguistic realization part of REG the overlap between strings has been measured using metrics like BLEU[54] or NIST.[55] A problem that occurs with string-based metrics is that for example "The small monkey" is measured closer to "The small donkey" than to "The little monkey".
A more time consuming way to evaluate REG algorithms is by letting humans judge the Adequacy (How clear is the description?) and Fluency (Is the description given in good and clear English?) of the generated expression. Also Belz and Gatt[56] evaluated referring expressions using an experimental setup. The participants get a generated description and then have to click on the target. Here the extrinsic metrics reading time, identification time and error rate could be evaluated. [note 1]
Notes
References
- 1 2 M Poesio, R Stevenson, B di Eugenio, J Hitzeman (2004). Centering: A Parametric Theory and Its Instantiations. Computational Linguistics 30:309-363
- 1 2 3 4 5 6 7 8 9 10 R Dale, E Reiter (1995). Computational interpretations of the Gricean maxims in the generation of referring expressions. Cognitive Science, 18:233–263.
- 1 2 E Krahmer, S van Erk, A Verleg (2003). Graph-Based Generation of Referring Expressions. Computational Linguistics 23:53-72
- ↑ E Reiter, S Sripada, J Hunter, J Yu, and I Davy (2005). Choosing Words in Computer-Generated Weather Forecasts. Artificial Intelligence 167:137-169.
- 1 2 R Turner, Y Sripada, E Reiter (2009) Generating Approximate Geographic Descriptions. Proceedings of the 12th European Workshop on Natural Language Generation (ENLG), pages 42–49, Athens.
- ↑ T Winograd (1972). Understanding Natural Language. Academic Press, New York. Section 8.3.3, Naming Objects and Events
- 1 2 3 D Appelt (1985). Planning English referring expressions. Artificial Intelligence, 26:1–33.
- 1 2 D Appelt, A Kronfeld (1987). A computational model of referring. In Proceedings of the 10th International Joint Conference on Artificial Intelligence (IJCAI), pages 640–647, Milan.
- ↑ A Kronfeld (1990). Reference and Computation: An Essay in Applied Philosophy of Language. Cambridge University Press, Cambridge.
- 1 2 R Dale (1989). Cooking up referring expressions. In Proceedings of the 27th Annual Meeting of the Association for Computational Linguistics (ACL), pages 68–75.
- 1 2 R Dale (1992). Generating Referring Expressions: Constructing Descriptions in a Domain of Objects and Processes. TheMIT Press, Cambridge, MA.
- ↑ E Reiter (1990). The computational complexity of avoiding conversational implicatures. In Proceedings of the 28th Annual Meeting of the Association for Computational Linguistics (ACL), pages 97–104, Pittsburgh, PA.
- ↑ E Reiter, R Dale (1992). A fast algorithm for the generation of referring expressions. In Proceedings of the 14th International Conference on Computational Linguistics (COLING), pages 232–238, Nantes.
- ↑ H Horacek (2004). On referring to sets of objects naturally. Proceedings of the 3rd International Conference on Natural Language Generation (INLG), pages 70–79, Brockenhurst.
- ↑ A Gatt, K van Deemter (2007). Lexical choice and conceptual perspective in the generation of plural referring expressions. Journal of Logic, Language and Information, 16:423–443.
- ↑ I H Khan, K van Deemter, G Ritchie (2008). Generation of referring expressions: Managing structural ambiguities. Proceedings of the 22th International Conference on Computational Linguistics (COLING), pages 433–440, Manchester.
- ↑ M Stone (2000). On identifying sets. Proceedings of the 1st International Conference on Natural Language Generation (INLG), pages 116–123, Mitzpe Ramon.
- 1 2 R Dale, N Haddock (1991). Generating referring expressions involving relations. Proceedings of the 5th Conference of the European Chapter of the Association of Computational Linguists (EACL), pages 161–166, Berlin.
- ↑ E Krahmer, M Theune (2002). Efficient context-sensitive generation of descriptions in context. In K van Deemter, R Kibble, editors, Information Sharing: Givenness and Newness in Language Processing. CSLI Publications, Stanford, CA, pages 223–264.
- 1 2 J Viethen, R Dale (2008). The use of spatial relations in referring expressions. Proceedings of the 5th International Natural Language Generation Conference (INLG), pages 59–67, Salt Fork, OH.
- ↑ Y Ren, K van Deemter, J Pan (2010). Charting the potential of Description Logic for the generation of referring expressions. Proceedings of the 6th International Natural Language Generation Conference (INLG), pages 115–124, Dublin.
- 1 2 E Krahmer, M Goudbeek, M Theune (2014). Referring Expression Generation in Interaction: A Graph-based perspective. A Stent, S Bangalore (eds.), Natural Language Generation in Interactive Systems. Cambridge University Press.
- ↑ K van Deemter (2006). Generating referring expressions that involve gradable properties. Computational Linguistics, 32(2):195–222.
- ↑ H Horacek (2005). Generating referential descriptions under conditions of uncertainty. Proceedings of the 10th European Workshop on Natural Language Generation (ENLG), pages 58–67, Aberdeen.
- ↑ R Passonneau (1996). Using centering to relax Gricean informational constraints on discourse anaphoric noun phrases. Language and Speech, 39:229–264.
- ↑ P W Jordan (2000). Intentional Influences on Object Redescriptions in Dialogue: Evidence from an Empirical Study. Ph.D. thesis, University of Pittsburgh.
- ↑ E Hajičová (1993). Issues of Sentence Structure and Discourse Patterns—Theoretical and Computational Linguistics, Vol. 2. Charles University, Prague.
- ↑ B J Grosz, A K Joshi, S Weinstein (1995). Centering: A framework for modeling the local coherence of discourse. Computational Linguistics, 21:203–225.
- ↑ D DeVault, C Rich, C L Sidner (2004). Natural language generation and discourse context: Computing distractor sets from the focus stack. Proceedings of the 17th International Meeting of the Florida Artificial Intelligence Research Society (FLAIRS), Miami Beach, FL.
- ↑ A Siddharthan, A Copestake (2004). Generating referring expressions in open domains. Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL), pages 407–414, Barcelona.
- ↑ I Paraboni, K van Deemter, J Masthoff (2007). Generating referring expressions: Making referents easy to identity. Computational Linguistics, 33:229–254.
- 1 2 E Krahmer, K van Deemter (2012). Computational Generation of Referring Expressions: A Survey. Computational Linguistics 38:173-218
- ↑ E Krahmer, M Theune, J Viethen, I Hendrickx (2008). Graph: The costs of redundancy in referring expressions. Proceedings of the International Conference on Natural Language Generation (INLG), pages 227–229, Salt Fork, OH.
- ↑ K van Deemter, E Krahmer (2007). Graphs and Booleans: On the generation of referring expressions. In H Bunt, R Muskens, editors, Computing Meaning, Volume 3. Studies in Linguistics and Philosophy. Springer Publishers, Berlin, pages 397–422.
- ↑ C Gardent (2002). Generating minimal definite descriptions. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), pages 96–103, Philadelphia, PA.
- ↑ M Croitoru, K van Deemter (2007). A conceptual graph approach to the generation of referring expressions. Proceedings of the 20th International Joint Conference on Artificial Intelligence (IJCAI), pages 2456–2461, Hyderabad.
- ↑ C Gardent, K Striegnitz (2007). Generating bridging definite descriptions. In H Bunt, Reinhard Muskens, editors, Computing Meaning, Volume 3. Studies in Linguistics and Philosophy. Springer Publishers, pages 369–396, Berlin, DB.
- ↑ C Areces, A Koller, K Striegnitz (2008). Referring expressions as formulas of Description Logic. Proceedings of the 5th International Natural Language Generation Conference (INLG), pages 42–49, Salt Fork, OH.
- ↑ M R Garey, D S. Johnson (1979). Computers and Intractability: A Guide to the Theory of NP–Completeness. W. H. Freeman, New York.
- ↑ D R Olson (1970). Language and thought: Aspects of a cognitive theory of semantics. Psychological Review, 77:257–273.
- ↑ S Sonnenschein (1984). The effect of redundant communication on listeners: Why different types may have different effects. Journal of Psycholinguistic Research, 13:147–166.
- ↑ T Pechmann (1989). Incremental speech production and referential overspecification. Linguistics, 27:98–110.
- ↑ P E Engelhardt, K G.D Bailey, F Ferreira (2006). Do speakers and listeners observe the Gricean Maxim of Quantity?. Journal of Memory and Language, 54:554–573.
- ↑ K van Deemter, I van der Sluis, A Gatt (2006). Building a semantically transparent corpus for the generation of referring expressions. In Proceedings of the 4th International Conference on Natural Language Generation (INLG), pages 130–132, Sydney.
- ↑ W W Chafe (1980). The Pear Stories: Cognitive, Cultural, and Linguistic Aspects of Narrative Production. Ablex, Norwood, NJ.
- ↑ A A Anderson, M Bader, E Gurman Bard, E Boyle, G Doherty, S Garrod, S Isard, J Kowtko, J McAllister, J Miller, C Sotillo, H Thompson, R Weinert (1991). The HCRC map task corpus. Language and Speech, 34:351–366.
- ↑ B Di Eugenio, P W Jordan, R H Thomason, J D Moore (2000). The agreement process: an empirical investigation of human–human computer-mediated collaborative dialogs. International Journal of Human–Computer Studies, 53:1017–1076.
- ↑ P Gorniak, D Roy (2004). Grounded semantic composition for visual scenes. Journal of Artificial Intelligence Research, 21:429–470.
- ↑ J Viethen, R Dale (2006). Algorithms for generating referring expressions: Do they do what people do?. Proceedings of the 4th International Conference on Natural Language Generation (INLG), pages 63–70, Sydney.
- 1 2 A Gatt, I van der Sluis, K van Deemter (2007). Evaluating algorithms for the generation of referring expressions using a balanced corpus. Proceedings of the 11th European Workshop on Natural Language Generation (ENLG), pages 49–56, Schloss Dagstuhl.
- ↑ L R Dice (1945). Measures of the amount of ecologic association between species. Ecology, 26:297–302.
- ↑ R Passonneau (2006). Measuring agreement on set-valued items (MASI) for semantic and pragmatic annotation. Proceedings of the 5th International Conference on Language Resources and Evaluation (LREC), pages 831–836, Genoa.
- ↑ A Gatt, A Belz, E Kow (2008). The TUNA challenge 2008: Overview and evaluation results. Proceedings of the 5th International Conference on Natural Language Generation (INLG), pages 198–206, Salt Fork, OH.
- ↑ K Papineni, S Roukos, T Ward, W Zhu (2002). BLEU: A method for automatic evaluation of machine translation. Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), pages 311–318, Philadelphia, PA.
- ↑ G Doddington (2002). Automatic evaluation of machine translation quality using n-gram co-occurrence statistics. Proceedings of the 2nd International Conference on Human Language Technology Research (HLT), pages 138–145, San Diego, CA.
- ↑ A Belz, A Gatt (2008). Intrinsic vs. extrinsic evaluation measures for referring expression generation. Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics (ACL), Columbus, OH.