Random walk closeness centrality
Random walk closeness centrality is a measure of centrality in a network, which describes the average speed with which randomly walking processes reach a node from other nodes of the network. The concept was first proposed by Noh and Rieger (2004).[1]
Intuition
Consider a network with a finite number of nodes and a random walk process that starts in a certain node and proceeds from node to node along the edges. From each node, it chooses randomly the edge to be followed. In an unweighted network, the probability of choosing a certain edge is equal across all available edges, while in a weighted network it is proportional to the edge weights. A node is considered to be close to other nodes, if the random walk process initiated from any node of the network arrives to this particular node in relatively few steps on average.
Definition
Consider a weighted network – either directed or undirected – with n nodes denoted by j=1, …, n; and a random walk process on this network with a transition matrix M. The 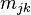 element of M describes the probability of the random walker that has reached node i, proceeds directly to node j. These probabilities are defined in the following way.
element of M describes the probability of the random walker that has reached node i, proceeds directly to node j. These probabilities are defined in the following way.
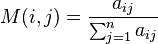
where  is the (i,j)th element of the weighting matrix A of the network. When there is no edge between two nodes, the corresponding element of the A matrix is zero.
is the (i,j)th element of the weighting matrix A of the network. When there is no edge between two nodes, the corresponding element of the A matrix is zero.
The random walk closeness centrality of a node i is the inverse of the average mean first passage time to that node:
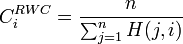
Mean first passage time
The mean first passage time from node i to node j is the expected number of steps it takes for the process to reach node j from node i for the first time:
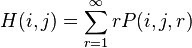
where P(i,j,r) denotes the probability that it takes exactly r steps to reach j from i for the first time.
To calculate these probabilities of reaching a node for the first time in r steps, it is useful to regard the target node as an absorbing one, and introduce a transformation of M by deleting its j-th row and column and denoting it by 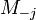 . As the probability of a process starting at i and being in k after r-1 steps is simply given by the (i,k)th element of
. As the probability of a process starting at i and being in k after r-1 steps is simply given by the (i,k)th element of 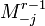 , P(i,j,r) can be expressed as
, P(i,j,r) can be expressed as
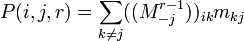
Substituting this into the expression for mean first passage time yields
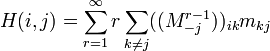
Using the formula for the summation of geometric series for matrices yields
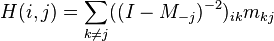
where I is the n-1 dimensional identity matrix.
For computational convenience, this expression can be vectorized as
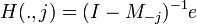
where 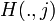 is the vector for first passage times for a walk ending at node j, and e is an n-1 dimensional vector of ones.
is the vector for first passage times for a walk ending at node j, and e is an n-1 dimensional vector of ones.
Mean first passage time is not symmetric, even for undirected graphs.
Random walk closeness centrality in model networks
According to simulations performed by Noh and Rieger (2004), the distribution of random walk closeness centrality in a Barabási-Albert model is mainly determined by the degree distribution. In such a network, the random walk closeness centrality of a node is roughly proportional to, but does not increase monotonically with its degree.
Applications for real networks
Random walk closeness centrality is more relevant measure than the simple closeness centrality in case of applications where the concept of shortest paths is not meaningful or is very restrictive for a reasonable assessment of the nature of the system. This is the case for example when the analyzed process evolves in the network without any specific intention to reach a certain point, or without the ability of finding the shortest path to reach its target. One example for a random walk in a network is the way a certain coin circulates in an economy: it is passed from one person to another through transactions, without any intention of reaching a specific individual. Another example where the concept of shortest paths is not very useful is a densely connected network. Furthermore, as shortest paths are not influenced by self-loops, random walk closeness centrality is more a more adequate measure than closeness centrality when analyzing networks where self-loops are important.
An important application on the field of economics is the analysis of the input-output model of an economy, which is represented by a densely connected weighted network with important self-loops.[2]
The concept is widely used in natural sciences as well. One biological application is the analysis of protein-protein interactions.[3]
Random walk betweenness centrality
A related concept, proposed by Newman,[4] is random walk betweenness centrality. Just as random walk closeness centrality is a random walk counterpart of closeness centrality, random walk betweenness centrality is, similarly, the random walk counterpart of betweenness centrality. Unlike the usual betweenness centrality measure, it does not only count shortest paths passing through the given node, but all possible paths crossing it.
Formally, the random walk betweenness centrality of a node is
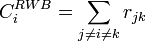
where the 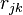 element of matrix R contains the probability of a random walk starting at node j with absorbing node k, passing through node i.
element of matrix R contains the probability of a random walk starting at node j with absorbing node k, passing through node i.
Calculating random walk betweenness in large networks is computationally very intensive.[5]
See also
References
- ↑ J.-D. Noh and H. Rieger. Random walks on complex networks. Phys. Rev. Lett. 92, 118701
- ↑ Blöchl F, Theis FJ, Vega-Redondo F, and Fisher E: Vertex Centralities in Input-Output Networks Reveal the Structure of Modern Economies, Physical Review E, 83(4):046127, 2011.
- ↑ Aidong, Zhang: Protein Interaction Networks: Computational Analysis (Cambridge University Press) 2007
- ↑ Newman, M.E. J.: A measure of betweenness centrality based on random walks. Social Networks, Volume 27, Issue 1, January 2005, Pages 39–54
- ↑ Kang, U., Papadimitriou, S., Sun, J., and Tong, H.: Centralities in Large Networks: Algorithms and Observations. SIAM International Conference on Data Mining 2011, Mesa, Arizona, USA.