Random graph
| Network science | ||||
|---|---|---|---|---|
| Network types | ||||
| Graphs | ||||
|
||||
| Models | ||||
|
||||
| ||||
|
||||

In mathematics, random graph is the general term to refer to probability distributions over graphs. Random graphs may be described simply by a probability distribution, or by a random process which generates them.[1] The theory of random graphs lies at the intersection between graph theory and probability theory. From a mathematical perspective, random graphs are used to answer questions about the properties of typical graphs. Its practical applications are found in all areas in which complex networks need to be modeled – a large number of random graph models are thus known, mirroring the diverse types of complex networks encountered in different areas. In a mathematical context, random graph refers almost exclusively to the Erdős–Rényi random graph model. In other contexts, any graph model may be referred to as a random graph.
Random graph models
A random graph is obtained by starting with a set of n isolated vertices and adding successive edges between them at random. The aim of the study in this field is to determine at what stage a particular property of the graph is likely to arise.[2] Different random graph models produce different probability distributions on graphs. Most commonly studied is the one proposed by Edgar Gilbert, denoted G(n,p), in which every possible edge occurs independently with probability 0 < p < 1. The probability of obtaining any one particular random graph with m edges is 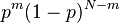 with the notation
with the notation 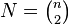 .[3]
.[3]
A closely related model, the Erdős–Rényi model denoted G(n,M), assigns equal probability to all graphs with exactly M edges. With 0 ≤ M ≤ N, G(n,M) has 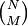 elements and every element occurs with probability
elements and every element occurs with probability 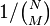 .[2] The latter model can be viewed as a snapshot at a particular time (M) of the random graph process
.[2] The latter model can be viewed as a snapshot at a particular time (M) of the random graph process 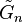 , which is a stochastic process that starts with n vertices and no edges, and at each step adds one new edge chosen uniformly from the set of missing edges.
, which is a stochastic process that starts with n vertices and no edges, and at each step adds one new edge chosen uniformly from the set of missing edges.
If instead we start with an infinite set of vertices, and again let every possible edge occur independently with probability 0 < p < 1, then we get an object G called an infinite random graph. Except in the trivial cases when p is 0 or 1, such a G almost surely has the following property:
Given any n + m elements, there is a vertex c in V that is adjacent to each of
and is not adjacent to any of
.
It turns out that if the vertex set is countable then there is, up to isomorphism, only a single graph with this property, namely the Rado graph. Thus any countably infinite random graph is almost surely the Rado graph, which for this reason is sometimes called simply the random graph. However, the analogous result is not true for uncountable graphs, of which there are many (nonisomorphic) graphs satisfying the above property.
Another model, which generalizes Gilbert's random graph model, is the random dot-product model. A random dot-product graph associates with each vertex a real vector. The probability of an edge uv between any vertices u and v is some function of the dot product u • v of their respective vectors.
The network probability matrix models random graphs through edge probabilities, which represent the probability  that a given edge
that a given edge 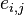 exists for a specified time period. This model is extensible to directed and undirected; weighted and unweighted; and static or dynamic graphs structure.
exists for a specified time period. This model is extensible to directed and undirected; weighted and unweighted; and static or dynamic graphs structure.
For M ≃ pN, where N is the maximal number of edges possible, the two most widely used models, G(n,M) and G(n,p), are almost interchangeable.[4]
Random regular graphs form a special case, with properties that may differ from random graphs in general.
Once we have a model of random graphs, every function on graphs, becomes a random variable. The study of this model is to determine if, or at least estimate the probability that, a property may occur.[3]
Terminology
The term 'almost every' in the context of random graphs refers to a sequence of spaces and probabilities, such that the error probabilities tend to zero.[3]
Properties of random graphs
The theory of random graphs studies typical properties of random graphs, those that hold with high probability for graphs drawn from a particular distribution. For example, we might ask for a given value of n and p what the probability is that G(n,p) is connected. In studying such questions, researchers often concentrate on the asymptotic behavior of random graphs—the values that various probabilities converge to as n grows very large. Percolation theory characterizes the connectedness of random graphs, especially infinitely large ones.
Percolation is related to the robustness of the graph (called also network). Given a random graph of n nodes and an average degree 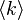 . Next we remove randomly a fraction 1−p of nodes and leave only a fraction p. There exists a critical percolation threshold
. Next we remove randomly a fraction 1−p of nodes and leave only a fraction p. There exists a critical percolation threshold 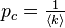 below which the network becomes fragmented while above pc a giant connected component exists.[1][4][5][6]
[7][8]
below which the network becomes fragmented while above pc a giant connected component exists.[1][4][5][6]
[7][8]
(threshold functions, evolution of G~)
Random graphs are widely used in the probabilistic method, where one tries to prove the existence of graphs with certain properties. The existence of a property on a random graph can often imply, via the Szemerédi regularity lemma, the existence of that property on almost all graphs.
In random regular graphs, G(n,r-reg) are the set of r-regular graphs with r = r(n) such that n and m are the natural numbers, 3 ≤ r < n, and rn = 2m is even.[2]
The degree sequence of a graph G in Gn depends only on the number of edges in the sets[2]
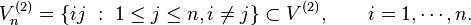
If edges, M in a random graph, GM is large enough to ensure that almost every GM has minimum degree at least 1, then almost every GM is connected and, if n is even, almost every GM has a perfect matching. In particular, the moment the last isolated vertex vanishes in almost every random graph, the graph becomes connected.[2]
Almost every graph process on an even number of vertices with the edge raising the minimum degree to 1 or a random graph with slightly more than (n/4)log(n) edges and with probability close to 1 ensures that the graph has a complete matching, with exception of at most one vertex.
For some constant c, almost every labelled graph with n vertices and at least cnlog(n) edges is Hamiltonian. With the probability tending to 1, the particular edge that increases the minimum degree to 2 makes the graph Hamiltonian.
Coloring of Random Graphs
Given a random graph G of order n with the vertex V(G) = {1, ..., n}, by the greedy algorithm on the number of colors, the vertices can be colored with colors 1, 2, ... (vertex 1 is colored 1, vertex 2 is colored 1 if it is not adjacent to vertex 1, otherwise it is colored 2, etc.).[2] The number of proper colorings of random graphs given a number of q colors, called its chromatic polynomial, remains unknown so far. The scaling of zeros of the chromatic polynomial of random graphs with parameters n and the number of edges m or the connection probability p has been studied empirically using an algorithm based on symbolic pattern matching. [9]
Random trees
A random tree is a tree or arborescence that is formed by a stochastic process. In a large range of random graphs of order n and size M(n) the distribution of the number of tree components of order k is asymptotically Poisson. Types of random trees include uniform spanning tree, random minimal spanning tree, random binary tree, treap, rapidly exploring random tree, Brownian tree, and random forest.
Conditionally uniform random graphs
Conditionally uniform random graphs assign equal probability to all the graphs having a specified properties. They can be seen as a generalization of the Erdős–Rényi model G(n,M), when the conditioning information is not necessarily the number of edges M, but whatever other arbitrary network property. In this case very few analytical results are available and simulation is required to obtain empirical distributions of average properties. Recently, a general and exact methodology for random graph simulation has been proposed by Stefano Nasini and Jordi Castro. [10]
History
Random graphs were first defined by Paul Erdős and Alfréd Rényi in their 1959 paper "On Random Graphs"[8] and independently by Gilbert in his paper "Random graphs".[5]
See also
- Bose–Einstein condensation: a network theory approach
- Cavity method
- Complex networks
- Dual-phase evolution
- Erdős–Rényi model
- Exponential random graph model
- Graph theory
- Network science
- Percolation
- Semilinear response
- Stochastic block model
References
- 1 2 Béla Bollobás, Random Graphs, 2nd Edition, 2001, Cambridge University Press
- 1 2 3 4 5 6 Béla Bollobás, Random Graphs, 1985, Academic Press Inc., London Ltd.
- 1 2 3 Béla Bollobás, Probabilistic Combinatorics and Its Applications, 1991, Providence, RI: American Mathematical Society.
- 1 2 Bollobas, B. and Riordan, O.M. "Mathematical results on scale-free random graphs" in "Handbook of Graphs and Networks" (S. Bornholdt and H.G. Schuster (eds)), Wiley VCH, Weinheim, 1st ed., 2003
- 1 2 Gilbert, E. N. (1959), "Random graphs", Annals of Mathematical Statistics 30: 1141–1144, doi:10.1214/aoms/1177706098.
- ↑ Newman, M. E. J. (2010). Networks: An Introduction. Oxford.
- ↑ Reuven Cohen and Shlomo Havlin (2010). Complex Networks: Structure, Robustness and Function. Cambridge University Press.
- 1 2 Erdős, P. Rényi, A (1959) "On Random Graphs I" in Publ. Math. Debrecen 6, p. 290–297
- ↑ Frank Van Bussel, Christoph Ehrlich, Denny Fliegner, Sebastian Stolzenberg and Marc Timme, Chromatic Polynomials of Random Graphs, J. Phys. A: Math. Theor. 43, 175002 (2010) | doi:10.1088/1751-8113/43/17/175002
- ↑ Stefano Nasini and Jordi Castro, (2015) "Mathematical programming approaches for classes of random network problems", in European Journal of Operational research