Quadratic probing
Quadratic probing is an open addressing scheme in computer programming for resolving collisions in hash tables—when an incoming data's hash value indicates it should be stored in an already-occupied slot or bucket. Quadratic probing operates by taking the original hash index and adding successive values of an arbitrary quadratic polynomial until an open slot is found.
For a given hash value, the indices generated by linear probing are as follows:
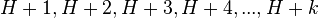
This method results in primary clustering, and as the cluster grows larger, the search for those items hashing within the cluster becomes less efficient.
An example sequence using quadratic probing is:
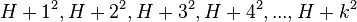
Quadratic probing can be a more efficient algorithm in a closed hash table, since it better avoids the clustering problem that can occur with linear probing, although it is not immune. It also provides good memory caching because it preserves some locality of reference; however, linear probing has greater locality and, thus, better cache performance.
Quadratic probing is used in the Berkeley Fast File System to allocate free blocks. The allocation routine chooses a new cylinder-group when the current is nearly full using quadratic probing, because of the speed it shows in finding unused cylinder-groups.
Quadratic function
Let h(k) be a hash function that maps an element k to an integer in [0,m-1], where m is the size of the table. Let the ith probe position for a value k be given by the function
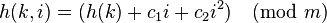
where c2 ≠ 0. If c2 = 0, then h(k,i) degrades to a linear probe. For a given hash table, the values of c1 and c2 remain constant.
Examples:
- If
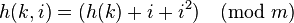 , then the probe sequence will be
, then the probe sequence will be 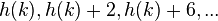
- For m = 2n, a good choice for the constants are c1 = c2 = 1/2, as the values of h(k,i) for i in [0,m-1] are all distinct. This leads to a probe sequence of
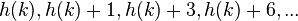 where the values increase by 1, 2, 3, ...
where the values increase by 1, 2, 3, ... - For prime m > 2, most choices of c1 and c2 will make h(k,i) distinct for i in [0, (m-1)/2]. Such choices include c1 = c2 = 1/2, c1 = c2 = 1, and c1 = 0, c2 = 1. Because there are only about m/2 distinct probes for a given element, it is difficult to guarantee that insertions will succeed when the load factor is > 1/2.
Quadratic probing insertion
The problem, here, is to insert a key at an available key space in a given Hash Table using quadratic probing.[1]
Algorithm to insert key in hash table
1. Get the key k
2. Set counter j = 0
3. Compute hash function h[k] = k % SIZE
4. If hashtable[h[k]] is empty
(4.1) Insert key k at hashtable[h[k]]
(4.2) Stop
Else
(4.3) The key space at hashtable[h[k]] is occupied, so we need to find the next available key space
(4.4) Increment j
(4.5) Compute new hash function h[k] = ( k + j * j ) % SIZE
(4.6) Repeat Step 4 till j is equal to the SIZE of hash table
5. The hash table is full
6. Stop
C function for key insertion
int quadratic_probing_insert(int *hashtable, int key, int *empty)
{
/* hashtable[] is an integer hash table; empty[] is another array which indicates whether the key space is occupied;
If an empty key space is found, the function returns the index of the bucket where the key is inserted, otherwise it
returns (-1) if no empty key space is found */
int i, index;
for (i = 0; i < SIZE; i++) {
index = (index + i*i) % SIZE;
if (empty[index]) {
hashtable[index] = key;
empty[index] = 0;
return index;
}
}
return -1;
}
Quadratic probing search
Algorithm to search element in hash table
1. Get the key k to be searched
2. Set counter j = 0
3. Compute hash function h[k] = k % SIZE
4. If the key space at hashtable[h[k]] is occupied
(4.1) Compare the element at hashtable[h[k]] with the key k.
(4.2) If they are equal
(4.2.1) The key is found at the bucket h[k]
(4.2.2) Stop
Else
(4.3) The element might be placed at the next location given by the quadratic function
(4.4) Increment j
(4.5) Compute new hash function h[k] = ( k + j * j ) % SIZE
(4.6) Repeat Step 4 till j is greater than SIZE of hash table
5. The key was not found in the hash table
6. Stop <lel>
C function for key searching
int quadratic_probing_search(int *hashtable, int key, int *empty)
{
/* If the key is found in the hash table, the function returns the index of the hashtable where the key is inserted, otherwise it
returns (-1) if the key is not found */
int i, index;
for (i = 0; i < SIZE; i++) {
index = (key + i*i) % SIZE;
if (!empty[index] && hashtable[index] == key)
return index;
}
return -1;
}
Limitations
[2] For linear probing it is a bad idea to let the hash table get nearly full, because performance is degraded as the hash table gets filled.
In the case of quadratic probing, the situation is even more drastic. With the exception of the triangular number case for a power-of-two-sized hash table, there is no guarantee of finding an empty cell once the table gets more than half full, or even before the table gets half full if the table size is not prime. This is because at most half of the table can be used as alternative locations to resolve collisions.
If the hash table size is b (a prime greater than 3), it can be proven that the first 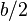 alternative locations including the initial location h(k) are all distinct and unique.
Suppose, we assume two of the alternative locations to be given by
alternative locations including the initial location h(k) are all distinct and unique.
Suppose, we assume two of the alternative locations to be given by 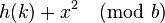 and
and 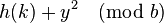 , where 0 ≤ x, y ≤ (b / 2).
If these two locations point to the same key space, but x ≠ y. Then the following would have to be true,
, where 0 ≤ x, y ≤ (b / 2).
If these two locations point to the same key space, but x ≠ y. Then the following would have to be true,
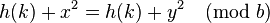
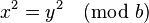
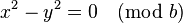
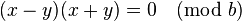
As b (table size) is a prime greater than 3, either (x - y) or (x + y) has to be equal to zero. Since x and y are unique, (x - y) cannot be zero. Also, since 0 ≤ x, y ≤ (b / 2), (x + y) cannot be zero.
Thus, by contradiction, it can be said that the first (b / 2) alternative locations after h(k) are unique. So an empty key space can always be found as long as at most (b / 2) locations are filled, i.e., the hash table is not more than half full.
Alternating sign
If the sign of the offset is alternated (e.g. +1, -4, +9, -16 etc.), and if the number of buckets is a prime number p congruent to 3 modulo 4 (i.e. one of 3, 7, 11, 19, 23, 31 and so on), then the first p offsets will be unique modulo p.
In other words, a permutation of 0 through p-1 is obtained, and, consequently, a free bucket will always be found as long as there exists at least one.
The insertion algorithm only receives a minor modification (but do note that SIZE has to be a suitable prime number as explained above):
1. Get the key k
2. Set counter j = 0
3. Compute hash function h[k] = k % SIZE
4. If hashtable[h[k]] is empty
(4.1) Insert key k at hashtable[h[k]]
(4.2) Stop
Else
(4.3) The key space at hashtable[h[k]] is occupied, so we need to find the next available key space
(4.4) Increment j
(4.5) Compute new hash function h[k]. If j is odd, then
h[k] = ( k + j * j ) % SIZE, else h[k] = ( k - j * j ) % SIZE
(4.6) Repeat Step 4 till j is equal to the SIZE of hash table
5. The hash table is full
6. Stop
The search algorithm is modified likewise.