QPACE2

QPACE 2 (QCD Parallel Computing Engine) is a massively parallel and scalable supercomputer. It was designed for applications in lattice quantum chromodynamics but is also suitable for a wider range of applications..
Overview
QPACE 2 is a follow-up to the QPACE supercomputer[1] and the iDataCool hot-water cooling project.[2] It is a combined effort of the particle physics group at the University of Regensburg and the Italian company Eurotech. The academic design team consisted of about 10 junior and senior physicists. Details of the project are described in.[3]
QPACE 2 uses Intel Xeon Phi processors (a.k.a. KNC), interconnected by a combination of PCI Express (abbreviated PCIe) and FDR InfiniBand. The main features of the QPACE 2 prototype installed at the University of Regensburg are
- scalability
- high packaging density
- warm-water cooling (no chillers are needed)
- high energy efficiency
- cost-effective design
The prototype is a one-rack installation that consists of 64 nodes with 15,872 physical cores in total and a peak performance of 310 TFlop/s. It was deployed in the summer of 2015[4] and is being used for simulations of lattice quantum chromodynamics. In November 2015, QPACE 2 was ranked #500 on the Top500 list of the most powerful supercomputers[5] and #15 on the Green 500 list of the most energy-efficient supercomputers of the world.[6]
QPACE 2 was funded by the German Research Foundation (DFG) in the framework of SFB/TRR-55 and by Eurotech.
Architecture
Many current supercomputers are hybrid architectures that use accelerator cards with a PCIe interface to boost the compute performance. In general, server processors support only a limited number of accelerators due to the limited number of PCIe lanes (typically 40 for the Intel Haswell architecture). The common approach to integrate multiple accelerators cards into the host system is to arrange multiple server processors, typically two or four, as distributed shared memory systems. This approach allows for a higher number of accelerators per compute node due to the higher number of PCIe lanes. However, it also comes with several disadvantages:
- The server processors, their interconnects (QPI for Intel processors) and memory chips significantly increase the foot-print of the host system.
- Expenses for the multiprocessor design are typically high.
- Server processors significantly contribute to the overall power signature of hybrid computer architectures and need appropriate cooling capacities.
- The server processor interconnect can hinder efficient intra-node communication and impose limitations on the performance of inter-node communication via the external network.
- The compute performance of server processors is typically an order of magnitude lower than that of accelerator cards, thus their contribution to the overall performance can be rather small.
- The instruction set architectures and hardware resources of server processors and accelerators differ significantly. Therefore, it is not always feasible for code to be developed for and to be executed on both architectures.
The QPACE 2 architecture addresses these disadvantages by a node design in which a single low-power Intel Haswell E3 host CPU accommodates four Xeon Phi 7120X accelerator cards for computational power and one dual-port FDR InfiniBand network interface card for external communication. To achieve this, the components within a node are interconnected by a PCIe switch with 96 lanes.
The QPACE 2 rack contains 64 compute nodes (and thus 256 Xeon Phi accelerators in total). 32 nodes each are on the front- and backside of the rack. The power subsystem consists of 48 power supplies that deliver an aggregate peak power of 96 kW. QPACE 2 relies on a warm-water cooling solution to achieve this packaging and power density.
Compute node
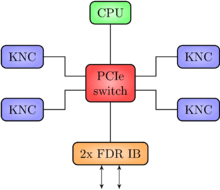
The QPACE 2 node consists of commodity hardware interconnected by PCIe. The midplane hosts a 96-lane PCIe switch (PEX8796 by Avago, formerly PLX Technology), provides six 16-lane PCIe Gen3 slots, and delivers power to all slots. One slot is used for the CPU card, which is a PCIe form factor card containing one Intel Haswell E3-1230L v3 server processor with 16 GB DDR3 memory as well as a microcontroller to monitor and control the node. Four slots are used for Xeon Phi 7120X cards with 16 GB GDDR5 each, and one slot for a dual-port FDR InfiniBand network interface card (Connect-IB by Mellanox).
The midplane and the CPU card were designed for the QPACE 2 project but can be reused for other projects or products.
The low-power Intel E3-1230L v3 server CPU is energy-efficient, but weak in computational power compared to other server processors available around 2015 (and in particular weaker than most accelerator cards). The CPU does not contribute significantly to the compute power of the node. It is merely running the operating system and system-relevant drivers. Technically, the CPU serves as a root complex for the PCIe fabric. The PCIe switch extends the host CPU's limited number of PCIe lanes to a total of 80 lanes, therefore enabling a multitude of components (4x Xeon Phi and 1x InfiniBand, each x16 PCIe) to be connected to the CPU as PCIe endpoints. This architecture also allows the Xeon Phis to do peer-to-peer communication via PCIe and to directly access the external network without having to go through the host CPU.
Each QPACE 2 node comprises 248 physical cores (host CPU: 4, Xeon Phi: 61 each). Host processor and accelerators support multithreading. The number of logical cores per node is 984.
The design of the node is not limited to the components used in QPACE 2. In principle, any cards supporting PCIe, e.g., accelerators such as GPUs and other network technologies than InfiniBand, can be used as long as form factor and power specifications are met.
Networks

The intra-node communication proceeds via the PCIe switch without host CPU involvement. The inter-node communication is based on FDR InfiniBand. The topology of the InfiniBand network is a two-dimensional hyper-crossbar. This means that a two-dimensional mesh of InfiniBand switches is built, and the two InfiniBand ports of a node are connected to one switch in each of the dimensions. The hyper-crossbar topology was first introduced by the Japanese CP-PACS collaboration of particle physicists.[7]
The InfiniBand network is also used for I/O to a Lustre file system.
The CPU card provides two Gigabit Ethernet interfaces that are used to control the nodes and to boot the operating system.
Cooling

The nodes of the QPACE 2 supercomputer are cooled by water using an innovative concept based on roll-bond technology.[8] Water flows through a roll-bond plate made of aluminum which is thermally coupled to the hot components via aluminum or copper interposers and thermal grease or thermal interface material. All components of the node are cooled in this way. The performance of the cooling concept allows for free cooling year-round.
The power consumption of a node was measured to be up to 1400 Watt in synthetic benchmarks. Around 1000 Watt are needed for typical computations in lattice quantum chromodynamics.
System software
The diskless nodes are operated using a standard Linux distribution (CentOS 7), which is booted over the Ethernet network. The Xeon Phis are running the freely available Intel Manycore Platform Software Stack (MPSS). The InfiniBand communication is based on the OFED stack, which is freely available as well.
See also
References
- ↑ H. Baier et al., PoS LAT2009 (2009) 001, (arXiv.org:0911.2174)
- ↑ N. Meyer et al., Lecture Notes in Computer Science 7905 (2013) 383, (arXiv.org:1309.4887)
- ↑ P. Arts et al., PoS LAT2014 (2014) 021, (arXiv.org:1502.04025)
- ↑ Eurotech press release
- ↑ The Top500 list, November 2015, http://top500.org/system/178607
- ↑ The Green500 list, November 2015, http://green500.org/lists/green201511&green500from=1&green500to=100
- ↑ Y. Iwasaki, Nucl. Phys. Proc. Suppl. 34 (1994) 78, (arxiv.org:hep-lat/9401030)
- ↑ J. Beddoes and M. Bibby, Principles of Metal Manufacturing Processes, Elsevier Science (1999)