Pseudo amino acid composition
Pseudo amino acid composition, or PseAA composition, or Chou's PseAAC, [1] was originally introduced by Kuo-Chen Chou in 2001 to represent protein samples for improving protein subcellular localization prediction and membrane protein type prediction.[2]
Background
To predict the subcellular localization of proteins and other attributes based on their sequence, two kinds of models are generally used to represent protein samples: (1) the sequential model, and (2) the non-sequential model or discrete model.
The most typical sequential representation for a protein sample is its entire amino acid (AA) sequence, which can contain its most complete information. This is an obvious advantage of the sequential model. To get the desired results, the sequence-similarity-search-based tools are usually utilized to conduct the prediction. However, this kind of approach fails when a query protein does not have significant homology to the known protein(s). Thus, various discrete models were proposed which do not rely on sequence-order.
The simplest discrete model is using the amino acid composition (AAC) to represent protein samples, formulated as follows. Given a protein sequence P with  amino acid residues, i.e.,
amino acid residues, i.e.,
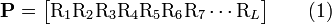
where R1 represents the 1st residue of the protein P, R2 the 2nd residue, and so forth, according to the amino acid composition (AAC) model, the protein P of Eq.1 can be expressed by
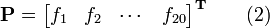
where 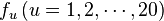 are the normalized occurrence frequencies of the 20 native amino acids in P, and T the transposing operator. Accordingly, the amino acid composition of a protein can be easily derived once the protein sequencing information is known.
are the normalized occurrence frequencies of the 20 native amino acids in P, and T the transposing operator. Accordingly, the amino acid composition of a protein can be easily derived once the protein sequencing information is known.
Owing to its simplicity, the amino acid composition (AAC) model was widely used in many earlier statistical methods for predicting protein attributes. However, all the sequence-order information is lost. This is its main shortcoming.
Concept
To avoid completely losing the sequence-order information, the concept of PseAA (pseudo amino acid) composition was proposed.[2] In contrast with the conventional amino acid composition that contains 20 components with each reflecting the occurrence frequency for one of the 20 native amino acids in a protein, the PseAA composition contains a set of greater than 20 discrete factors, where the first 20 represent the components of its conventional AA composition while the additional factors incorporate some sequence-order information via various modes.
The additional factors are a series of rank-different correlation factors along a protein chain, but they can also be any combinations of other factors so long as they can reflect some sorts of sequence-order effects one way or the other. Therefore, the essence of PseAA composition is that on one hand it covers the AA composition, but on the other hand it contains the information beyond the AA composition and hence can better reflect the feature of a protein sequence through a discrete model.
Meanwhile, various modes to formulate the PseAA composition have also been developed, as summarized in a review.[3]
Algorithm

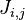 are given by Eq.6. Panel (a) reflects the correlation mode between all the most contiguous residues, panel (b) that between all the 2nd most contiguous residues, and panel (c) that between all the 3rd most contiguous residues.
are given by Eq.6. Panel (a) reflects the correlation mode between all the most contiguous residues, panel (b) that between all the 2nd most contiguous residues, and panel (c) that between all the 3rd most contiguous residues.According to the PseAA composition model, the protein P of Eq.1 can be formulated as
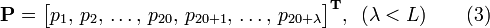
where the (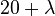 ) components are given by
) components are given by
![p_u = \begin{cases}
\dfrac {f_u} {\sum_{i=1}^{20}f_i \, + \, w\sum_{k=1}^{\lambda} \tau_k}, & (1 \le u \le 20)
\\[10pt]
\dfrac {w \tau_{u-20}} {\sum_{i=1}^{20} f_i \, + \, w\sum_{k=1}^{\lambda} \tau_k}, & (20+1 \le u \le 20+\lambda)
\end{cases}
\qquad \text{(4)}](../I/m/abd78b410c899d6ca89bbabbd783f425.png)
where  is the weight factor, and
is the weight factor, and 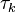 the
the  -th tier correlation factor that reflects the sequence order correlation between all the -th most contiguous residues as formulated by
-th tier correlation factor that reflects the sequence order correlation between all the -th most contiguous residues as formulated by
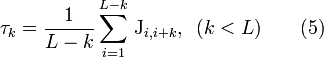
with
![\mathrm{J}_{i, i+k} = \frac{1}{\Gamma} \sum_{q=1}^{\Gamma} \left[\Phi_{q}\left(\mathrm{R}_{i+k}\right) - \Phi_{q}\left(\mathrm{R}_{i}\right ) \right]^2
\qquad \text{(6)}](../I/m/2c140f802f942b194b04c756623b83cf.png)
where 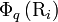 is the
is the  -th function of the amino acid
-th function of the amino acid 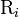 , and
, and 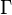 the total number of the functions considered. For example, in the original paper by Chou,[2]
the total number of the functions considered. For example, in the original paper by Chou,[2] 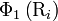 ,
, 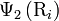 and
and 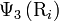 are respectively the hydrophobicity value, hydrophilicity value, and side chain mass of amino acid ; while
are respectively the hydrophobicity value, hydrophilicity value, and side chain mass of amino acid ; while 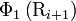 ,
, 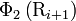 and
and 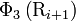 the corresponding values for the amino acid
the corresponding values for the amino acid 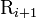 . Therefore, the total number of functions considered there is
. Therefore, the total number of functions considered there is 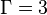 . It can be seen from Eq.3 that the first 20 components, i.e.
. It can be seen from Eq.3 that the first 20 components, i.e. 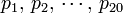 are associated with the conventional AA composition of protein, while the remaining components
are associated with the conventional AA composition of protein, while the remaining components 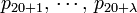 are the correlation factors that reflect the 1st tier, 2nd tier, …, and the
are the correlation factors that reflect the 1st tier, 2nd tier, …, and the 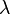 -th tier sequence order correlation patterns (Figure 1).
It is through these additional factors that some important sequence-order effects are incorporated.
-th tier sequence order correlation patterns (Figure 1).
It is through these additional factors that some important sequence-order effects are incorporated.
in Eq.3 is a parameter of integer and that choosing a different integer for will lead to a dimension-different PseAA composition.[4]
Using Eq.6 is just one of the modes for deriving the correlation factors or PseAA components. The others, such as the physicochemical distance mode[5] and amphiphilic pattern mode,[6] can also be used to derive different types of PseAA composition, as summarized in a review paper.[3]
Applications
Since PseAA composition was introduced, it has been widely used to predict various attributes of proteins, such as structural classes of proteins,[7][8] enzyme family classes and subfamily classes,[9] GABA(A) receptor proteins,[10] protein folding rates,[11] cyclin proteins,[12] supersecondary structure,[13] subcellular location of proteins,[14][15] subnuclear location of proteins,[16] apoptosis protein subcellular localization,[17] submitochondria localization,[18] protein quaternary structure,[19][20] bacterial secreted proteins,[21] conotoxin superfamily and family classification,[22] protease types,[23] GPCR types,[24][25] human papillomaviruses, [26] outer membrane proteins,[27] membrane protein types,[28] protein secondary structural contents,[29] metalloproteinase family [30] subcellular localization of mycobacterial proteins,[31] antibacterial peptides [32] lipase types,[33] allergenic proteins [34] DNA-binding proteins,[35] essential proteins,[36] cell wall lytic enzymes,[37] cofactors of oxidoreductases,[38] among many other protein attributes and protein-related features (see, e.g., the review paper by Gonzalez-Diaz et al.[39] as well as the relevant references cited therein).
Ever since the concept of PseAA composition was introduced, it has been widely utilized to predict various protein attributes. It has also been used to incorporate the protein domain or FunD (functional domain) information and GO (gene ontology) information for improving the prediction quality for the subcellular localization of proteins.[40] as well as their other attributes.
Meanwhile, the concept of PseAA composition has also stimulated the generation of pseudo-folding topological indices and pseudo-folding lattice network.[41][42][43]
Recently, two open accessible tools were established to generate various modes of Chou’s pseudo amino acid composition.[44][45]
References
- ↑ Lin, Sheng-Xiang; Lapointe, Jacques (2013). "Theoretical and experimental biology in one —A symposium in honour of Professor Kuo-Chen Chou’s 50th anniversary and Professor Richard Giegé’s 40th anniversary of their scientific careers". JBiSE 6: 435–442. doi:10.4236/jbise.2013.64054.
- 1 2 3 Chou KC (May 2001). "Prediction of protein cellular attributes using pseudo-amino acid composition". Proteins 43 (3): 246–55. doi:10.1002/prot.1035. PMID 11288174.
- 1 2 Chou K-C, Kuo-Chen (2009). "Pseudo amino acid composition and its applications in bioinformatics, proteomics and system biology.". Current Proteomics 6 (4): 262–274. doi:10.2174/157016409789973707.
- ↑ Chou KC, Shen HB (November 2007). "Recent progress in protein subcellular location prediction". Anal. Biochem. 370 (1): 1–16. doi:10.1016/j.ab.2007.07.006. PMID 17698024.
- ↑ Chou KC (November 2000). "Prediction of protein subcellular locations by incorporating quasi-sequence-order effect". Biochem. Biophys. Res. Commun. 278 (2): 477–83. doi:10.1006/bbrc.2000.3815. PMID 11097861.
- ↑ Chou KC (January 2005). "Using amphiphilic pseudo amino acid composition to predict enzyme subfamily classes". Bioinformatics 21 (1): 10–9. doi:10.1093/bioinformatics/bth466. PMID 15308540.
- ↑ Sahu SS, Panda G (December 2010). "A novel feature representation method based on Chou's pseudo amino acid composition for protein structural class prediction". Comput Biol Chem 34 (5-6): 320–7. doi:10.1016/j.compbiolchem.2010.09.002. PMID 21106461.
- ↑ Chen C, Zhou X, Tian Y, Zou X, Cai P (October 2006). "Predicting protein structural class with pseudo-amino acid composition and support vector machine fusion network". Anal. Biochem. 357 (1): 116–21. doi:10.1016/j.ab.2006.07.022. PMID 16920060.
- ↑ Zhou XB, Chen C, Li ZC, Zou XY (October 2007). "Using Chou's amphiphilic pseudo-amino acid composition and support vector machine for prediction of enzyme subfamily classes". J. Theor. Biol. 248 (3): 546–51. doi:10.1016/j.jtbi.2007.06.001. PMID 17628605.
- ↑ Mohabatkar H, Mohammad Beigi M, Esmaeili A (July 2011). "Prediction of GABA(A) receptor proteins using the concept of Chou's pseudo-amino acid composition and support vector machine". J. Theor. Biol. 281 (1): 18–23. doi:10.1016/j.jtbi.2011.04.017. PMID 21536049.
- ↑ Guo J, Rao N, Liu G, Yang Y, Wang G (June 2011). "Predicting protein folding rates using the concept of Chou's pseudo amino acid composition". J Comput Chem 32 (8): 1612–7. doi:10.1002/jcc.21740. PMID 21328402.
- ↑ Mohabatkar H (October 2010). "Prediction of cyclin proteins using Chou's pseudo amino acid composition". Protein Pept. Lett. 17 (10): 1207–14. doi:10.2174/092986610792231564. PMID 20450487.
- ↑ Zou D, He Z, He J, Xia Y (January 2011). "Supersecondary structure prediction using Chou's pseudo amino acid composition". J Comput Chem 32 (2): 271–8. doi:10.1002/jcc.21616. PMID 20652881.
- ↑ Zhang SW, Zhang YL, Yang HF, Zhao CH, Pan Q (May 2008). "Using the concept of Chou's pseudo amino acid composition to predict protein subcellular localization: an approach by incorporating evolutionary information and von Neumann entropies". Amino Acids 34 (4): 565–72. doi:10.1007/s00726-007-0010-9. PMID 18074191.
- ↑ Mei, S. (June 2012). "Predicting plant protein subcellular multi-localization by Chou's PseAAC formulation based multi-label homolog knowledge transfer learning". Journal of Theoretical Biology 310: 80–87. doi:10.1016/j.jtbi.2012.06.028. PMID 22750634.
- ↑ Mundra P, Kumar M, Kumar KK, Jayaraman VK, Kulkarni BD (October 2007). "Using pseudo amino acid composition to predict protein subnuclear localization: Approached with PSSM". Pattern Recognition Letters 28 (13): 1610–1615. doi:10.1016/j.patrec.2007.04.001.
- ↑ Chen YL, Li QZ (September 2007). "Prediction of apoptosis protein subcellular location using improved hybrid approach and pseudo-amino acid composition". J. Theor. Biol. 248 (2): 377–81. doi:10.1016/j.jtbi.2007.05.019. PMID 17572445.
- ↑ Nanni L, Lumini A (May 2008). "Genetic programming for creating Chou's pseudo amino acid based features for submitochondria localization". Amino Acids 34 (4): 653–60. doi:10.1007/s00726-007-0018-1. PMID 18175047.
- ↑ Zhang SW, Chen W, Yang F, Pan Q (October 2008). "Using Chou's pseudo amino acid composition to predict protein quaternary structure: a sequence-segmented PseAAC approach". Amino Acids 35 (3): 591–8. doi:10.1007/s00726-008-0086-x. PMID 18427713.
- ↑ Sun, X. Y., Shi, S. P., Qiu, J. D., Suo, S. B., Huang, S. Y. & Liang, R. P. (2012). "Identifying protein quaternary structural attributes by incorporating physicochemical properties into the general form of Chou's PseAAC via discrete wavelet transform". Molecular BioSystems 8: 3178–84. doi:10.1039/c2mb25280e. PMID 22990717.
- ↑ Nanni, L., Lumini, A., Gupta, D. & Garg, A. (August 2012). "Identifying Bacterial Virulent Proteins by Fusing a Set of Classifiers Based on Variants of Chou's Pseudo Amino Acid Composition and on Evolutionary Information". IEEE/ACM Trans Comput Biol Bioinform 9: 467–475. doi:10.1109/TCBB.2011.117. PMID 21860064.
- ↑ Mondal S, Bhavna R, Mohan Babu R, Ramakumar S (November 2006). "Pseudo amino acid composition and multi-class support vector machines approach for conotoxin superfamily classification". J. Theor. Biol. 243 (2): 252–60. doi:10.1016/j.jtbi.2006.06.014. PMID 16890961.
- ↑ Zhou GP, Cai YD (May 2006). "Predicting protease types by hybridizing gene ontology and pseudo amino acid composition". Proteins 63 (3): 681–4. doi:10.1002/prot.20898. PMID 16456852.
- ↑ Qiu JD, Huang JH, Liang RP, Lu XQ (July 2009). "Prediction of G-protein-coupled receptor classes based on the concept of Chou's pseudo amino acid composition: an approach from discrete wavelet transform". Anal. Biochem. 390 (1): 68–73. doi:10.1016/j.ab.2009.04.009. PMID 19364489.
- ↑ Zia Ur, R. & Khan, A. (2012). "Identifying GPCRs and their Types with Chou's Pseudo Amino Acid Composition: An Approach from Multi-scale Energy Representation and Position Specific Scoring Matrix". Protein & Peptide Letters. 19: 890–903. PMID 22316312.
- ↑ Esmaeili M, Mohabatkar H, Mohsenzadeh S (March 2010). "Using the concept of Chou's pseudo amino acid composition for risk type prediction of human papillomaviruses". J. Theor. Biol. 263 (2): 203–9. doi:10.1016/j.jtbi.2009.11.016. PMID 19961864.
- ↑ Hayat, M. & Khan, A. (April 2012). "Discriminating Outer Membrane Proteins with Fuzzy K-Nearest Neighbor Algorithms Based on the General Form of Chou's PseAAC". Protein & Peptide Letters 19: 411–421. doi:10.2174/092986612799789387. PMID 22185508.
- ↑ Chen, Y. K. & Li, K. B. (2012). "Predicting membrane protein types by incorporating protein topology, domains, signal peptides, and physicochemical properties into the general form of Chou's pseudo amino acid composition". Journal of Theoretical Biology 318: 1–12. doi:10.1016/j.jtbi.2012.10.033. PMID 23137835.
- ↑ Chen C, Chen L, Zou X, Cai P (2009). "Prediction of protein secondary structure content by using the concept of Chou's pseudo amino acid composition and support vector machine". Protein Pept. Lett. 16 (1): 27–31. doi:10.2174/092986609787049420. PMID 19149669.
- ↑ Mohammad Beigi, M., Behjati, M. & Mohabatkar, H. (2011). "Prediction of metalloproteinase family based on the concept of Chou's pseudo amino acid composition using a machine learning approach". Journal of Structural and Functional Genomics 12: 191–197. doi:10.1007/s10969-011-9120-4. PMID 22143437.
- ↑ Lin H, Ding H, Guo FB, Zhang AY, Huang J (2008). "Predicting subcellular localization of mycobacterial proteins by using Chou's pseudo amino acid composition". Protein Pept. Lett. 15 (7): 739–44. doi:10.2174/092986608785133681. PMID 18782071.
- ↑ Khosravian, M., Faramarzi, F. K., Beigi, M. M., Behbahani, M. & Mohabatkar, H (2013). "Predicting Antibacterial Peptides by the Concept of Chou's Pseudo-amino Acid Composition and Machine Learning Methods". Protein Pept. Lett. 20: 180–186. doi:10.2174/0929866511320020009. PMID 22894156.
- ↑ Zhang GY, Li HC, Gao JQ, Fang BS (2008). "Predicting lipase types by improved Chou's pseudo-amino acid composition". Protein Pept. Lett. 15 (10): 1132–7. doi:10.2174/092986608786071184. PMID 19075826.
- ↑ Mohabatkar, H., Beigi, M. M., Abdolahi, K. & Mohsenzadeh, S. (2013). "Prediction of allergenic proteins by means of the concept of Chou's pseudo amino acid composition and a machine learning approach". Medicinal Chemistry 9: 133–137. doi:10.2174/157340613804488341. PMID 22931491.
- ↑ Fang Y, Guo Y, Feng Y, Li M (January 2008). "Predicting DNA-binding proteins: approached from Chou's pseudo amino acid composition and other specific sequence features". Amino Acids 34 (1): 103–9. doi:10.1007/s00726-007-0568-2. PMID 17624492.
- ↑ Sarangi, A. N., Lohani, M. & Aggarwal, R. (2013). "Prediction of Essential Proteins in Prokaryotes by Incorporating Various Physico-chemical Features into the General form of Chou's Pseudo Amino Acid Composition". Protein Pept. Lett. 20: 781–795. doi:10.2174/0929866511320070008. PMID 23276224.
- ↑ Ding H, Luo L, Lin H (2009). "Prediction of cell wall lytic enzymes using Chou's amphiphilic pseudo amino acid composition". Protein Pept. Lett. 16 (4): 351–5. doi:10.2174/092986609787848045. PMID 19356130.
- ↑ Zhang GY, Fang BS (July 2008). "Predicting the cofactors of oxidoreductases based on amino acid composition distribution and Chou's amphiphilic pseudo-amino acid composition". J. Theor. Biol. 253 (2): 310–5. doi:10.1016/j.jtbi.2008.03.015. PMID 18471832.
- ↑ González-Díaz H, González-Díaz Y, Santana L, Ubeira FM, Uriarte E (February 2008). "Proteomics, networks and connectivity indices". Proteomics 8 (4): 750–78. doi:10.1002/pmic.200700638. PMID 18297652.
- ↑ Chou KC, Shen HB (2008). "Cell-PLoc: a package of Web servers for predicting subcellular localization of proteins in various organisms". Nat Protoc 3 (2): 153–62. doi:10.1038/nprot.2007.494. PMID 18274516.
- ↑ Agüero-Chapin G, Varona-Santos J, de la Riva GA, Antunes A, González-Vlla T, Uriarte E, González-Díaz H (April 2009). "Alignment-free prediction of polygalacturonases with pseudofolding topological indices: experimental isolation from Coffea arabica and prediction of a new sequence". J. Proteome Res. 8 (4): 2122–8. doi:10.1021/pr800867y. PMID 19296677.
- ↑ Perez-Bello A, Munteanu CR, Ubeira FM, De Magalhães AL, Uriarte E, González-Díaz H (February 2009). "Alignment-free prediction of mycobacterial DNA promoters based on pseudo-folding lattice network or star-graph topological indices". J. Theor. Biol. 256 (3): 458–66. doi:10.1016/j.jtbi.2008.09.035. PMID 18992259.
- ↑ González-Díaz H, Dea-Ayuela MA, Pérez-Montoto LG, Prado-Prado FJ, Agüero-Chapín G, Bolas-Fernández F, Vazquez-Padrón RI, Ubeira FM (May 2010). "QSAR for RNases and theoretic-experimental study of molecular diversity on peptide mass fingerprints of a new Leishmania infantum protein". Mol. Divers. 14 (2): 349–69. doi:10.1007/s11030-009-9178-0. PMID 19578942.
- ↑ Du, P., Wang, X., Xu, C. & Gao, Y. (March 2012). "PseAAC-Builder: A cross-platform stand-alone program for generating various special Chou's pseudo-amino acid compositions". Analytical Biochemistry 425: 117–9. doi:10.1016/j.ab.2012.03.015. PMID 22459120.
- ↑ Cao, D. S., Xu, Q. S. & Liang, Y. Z. (April 2013). "propy: a tool to generate various modes of Chou's PseAAC". Bioinformatics 29: 960–962. doi:10.1093/bioinformatics/btt072. PMID 23426256.
External links
- ↑ Shen HB, Chou KC (February 2008). "PseAAC: a flexible web server for generating various kinds of protein pseudo amino acid composition". Anal. Biochem. 373 (2): 386–8. doi:10.1016/j.ab.2007.10.012. PMID 17976365.