Pearson product-moment correlation coefficient
In statistics, the Pearson product-moment correlation coefficient (/ˈpɪərsᵻn/) (sometimes referred to as the PPMCC or PCC or Pearson's r) is a measure of the linear correlation between two variables X and Y, giving a value between +1 and −1 inclusive, where 1 is total positive correlation, 0 is no correlation, and −1 is total negative correlation. It is widely used in the sciences as a measure of the degree of linear dependence between two variables. It was developed by Karl Pearson from a related idea introduced by Francis Galton in the 1880s.[1][2][3] Early work on the distribution of the sample correlation coefficient was carried out by Anil Kumar Gain[4] and R. A. Fisher[5][6] from the University of Cambridge.


Definition
Pearson's correlation coefficient is the covariance of the two variables divided by the product of their standard deviations. The form of the definition involves a "product moment", that is, the mean (the first moment about the origin) of the product of the mean-adjusted random variables; hence the modifier product-moment in the name.
For a population
Pearson's correlation coefficient when applied to a population is commonly represented by the Greek letter ρ (rho) and may be referred to as the population correlation coefficient or the population Pearson correlation coefficient. The formula for ρ[7] is:
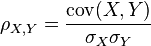
- where:
-
 is the covariance
is the covariance -
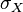 is the standard deviation of
is the standard deviation of 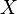
-
- where:
The formula for ρ can be expressed in terms of mean and expectation. Since
![\operatorname{cov}(X,Y) = \operatorname{E}[(X-\mu_X)(Y-\mu_Y)]](../I/m/85eb69fa2d810acdd879236a624c927d.png)
Then the formula for ρ can also be written as
![\rho_{X,Y}=\frac{\operatorname{E}[(X-\mu_X)(Y-\mu_Y)]}{\sigma_X\sigma_Y}](../I/m/e0150d5feea4091277abdcbd9db35fc9.png)
- where:
- and are defined as above
-
 is the mean of
is the mean of -
 is the expectation.
is the expectation.
-
- where:
The formula for ρ can be expressed in terms of uncentered moments. Since
![\mu_X=\operatorname{E}[X]](../I/m/213ddf84ba1cc6977c32c55298633f79.png)
![\mu_Y=\operatorname{E}[Y]](../I/m/507f97ca0759fff54ce4de46a70b4301.png)
![\sigma_X^2=\operatorname{E}[(X-\operatorname{E}[X])^2]=\operatorname{E}[X^2]-\operatorname{E}[X]^2](../I/m/9146607a529c5827a45c1ec27005f85e.png)
![\sigma_Y^2=\operatorname{E}[(Y-\operatorname{E}[Y])^2]=\operatorname{E}[Y^2]-\operatorname{E}[Y]^2](../I/m/57db9bf0e1ab9915656ae72f890e8017.png)
![\operatorname{E}[(X-\mu_X)(Y-\mu_Y)]=\operatorname{E}[(X-\operatorname{E}[X])(Y-\operatorname{E}[Y])]=\operatorname{E}[XY]-\operatorname{E}[X]\operatorname{E}[Y],\,](../I/m/433542b21e76326cc35511b216b2b6e7.png)
the formula for ρ can also be written as
![\rho_{X,Y}=\frac{\operatorname{E}[XY]-\operatorname{E}[X]\operatorname{E}[Y]}{\sqrt{\operatorname{E}[X^2]-\operatorname{E}[X]^2}~\sqrt{\operatorname{E}[Y^2]- \operatorname{E}[Y]^2}}.](../I/m/3a8fd48ed9d34d02cb87f2604dc50c50.png)
For a sample
Pearson's correlation coefficient when applied to a sample is commonly represented by the letter r and may be referred to as the sample correlation coefficient or the sample Pearson correlation coefficient. We can obtain a formula for r by substituting estimates of the covariances and variances based on a sample into the formula above. So if we have one dataset {x1,...,xn} containing n values and another dataset {y1,...,yn} containing n values then that formula for r is:
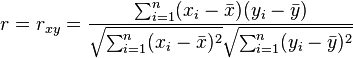
- where:
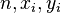 are defined as above
are defined as above (the sample mean); and analogously for
(the sample mean); and analogously for 
Rearranging gives us this formula for r:
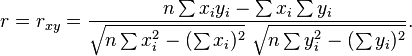
- where:
- are defined as above
- This formula suggests a convenient single-pass algorithm for calculating sample correlations, but, depending on the numbers involved, it can sometimes be numerically unstable.
Rearranging again gives us this[7] formula for r:
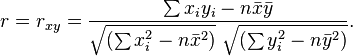
- where:
 are defined as above
are defined as above
An equivalent expression gives the formula for r as the mean of the products of the standard scores as follows:
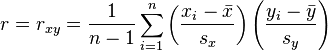
- where
- are defined as above, and
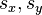 are defined below
are defined below 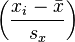 is the standard score (and analogously for the standard score of y)
is the standard score (and analogously for the standard score of y)
Alternative formulae for r are also available. One can use the following formula for r:
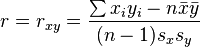
- where:
- are defined as above and:
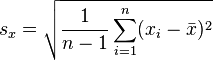 (the sample standard deviation); and analogously for sy
(the sample standard deviation); and analogously for sy
Mathematical properties
The absolute values of both the sample and population Pearson correlation coefficients are less than or equal to 1. Correlations equal to 1 or −1 correspond to data points lying exactly on a line (in the case of the sample correlation), or to a bivariate distribution entirely supported on a line (in the case of the population correlation). The Pearson correlation coefficient is symmetric: corr(X,Y) = corr(Y,X).
A key mathematical property of the Pearson correlation coefficient is that it is invariant to separate changes in location and scale in the two variables. That is, we may transform X to a + bX and transform Y to c + dY, where a, b, c, and d are constants with b, d ≠ 0, without changing the correlation coefficient. (This fact holds for both the population and sample Pearson correlation coefficients.) Note that more general linear transformations do change the correlation: see a later section for an application of this.
Interpretation
The correlation coefficient ranges from −1 to 1. A value of 1 implies that a linear equation describes the relationship between X and Y perfectly, with all data points lying on a line for which Y increases as X increases. A value of −1 implies that all data points lie on a line for which Y decreases as X increases. A value of 0 implies that there is no linear correlation between the variables.
More generally, note that (Xi − X)(Yi − Y) is positive if and only if Xi and Yi lie on the same side of their respective means. Thus the correlation coefficient is positive if Xi and Yi tend to be simultaneously greater than, or simultaneously less than, their respective means. The correlation coefficient is negative if Xi and Yi tend to lie on opposite sides of their respective means. Moreover, the stronger is either tendency, the larger is the absolute value of the correlation coefficient.
Geometric interpretation

For uncentered data, it is possible to obtain a relation between correlation coefficient and the angle  between both possible regression lines y=gx(x) and x=gy(y). One can show[8] that r = sec
between both possible regression lines y=gx(x) and x=gy(y). One can show[8] that r = sec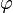 – tan.
– tan.
For centered data (i.e., data which have been shifted by the sample means of their respective variables so as to have an average of zero for each variable), the correlation coefficient can also be viewed as the cosine of the angle  between the two vectors of samples in N-dimensional space (for N samples of each variable)[9]:ch. 5 (as illustrated for a special case in the next paragraph).
between the two vectors of samples in N-dimensional space (for N samples of each variable)[9]:ch. 5 (as illustrated for a special case in the next paragraph).
Both the uncentered (non-Pearson-compliant) and centered correlation coefficients can be determined for a dataset. As an example, suppose five countries are found to have gross national products of 1, 2, 3, 5, and 8 billion dollars, respectively. Suppose these same five countries (in the same order) are found to have 11%, 12%, 13%, 15%, and 18% poverty. Then let x and y be ordered 5-element vectors containing the above data: x = (1, 2, 3, 5, 8) and y = (0.11, 0.12, 0.13, 0.15, 0.18).
By the usual procedure for finding the angle between two vectors (see dot product), the uncentered correlation coefficient is:
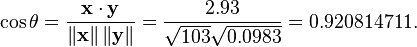
Note that the above data were deliberately chosen to be perfectly correlated: y = 0.10 + 0.01 x. The Pearson correlation coefficient must therefore be exactly one. Centering the data (shifting x by E(x) = 3.8 and y by E(y) = 0.138) yields x = (−2.8, −1.8, −0.8, 1.2, 4.2) and y = (−0.028, −0.018, −0.008, 0.012, 0.042), from which
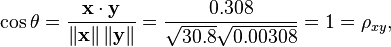
as expected.
Interpretation of the size of a correlation

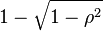 (plotted here as a function of ρ) is the factor by which a given prediction interval for Y may be reduced given the corresponding value of X. For example, if ρ = .5, then the 95% prediction interval of Y|X will be about 13% smaller than the 95% prediction interval of Y.
(plotted here as a function of ρ) is the factor by which a given prediction interval for Y may be reduced given the corresponding value of X. For example, if ρ = .5, then the 95% prediction interval of Y|X will be about 13% smaller than the 95% prediction interval of Y.Several authors[10][11] have offered guidelines for the interpretation of a correlation coefficient. However, all such criteria are in some ways arbitrary and should not be observed too strictly.[11] The interpretation of a correlation coefficient depends on the context and purposes. A correlation of 0.8 may be very low if one is verifying a physical law using high-quality instruments, but may be regarded as very high in the social sciences where there may be a greater contribution from complicating factors.
Inference

Statistical inference based on Pearson's correlation coefficient often focuses on one of the following two aims:
- One aim is to test the null hypothesis that the true correlation coefficient ρ is equal to 0, based on the value of the sample correlation coefficient r.
- The other aim is to derive a confidence interval that, on repeated sampling, has a given probability of containing ρ.
We discuss methods of achieving one or both of these aims below.
Using a permutation test
Permutation tests provide a direct approach to performing hypothesis tests and constructing confidence intervals. A permutation test for Pearson's correlation coefficient involves the following two steps:
- Using the original paired data (xi, yi), randomly redefine the pairs to create a new data set (xi, yi′), where the i′ are a permutation of the set {1,...,n}. The permutation i′ is selected randomly, with equal probabilities placed on all n! possible permutations. This is equivalent to drawing the i′ randomly "without replacement" from the set {1, ..., n}. A closely related and equally justified (bootstrapping) approach is to separately draw the i and the i′ "with replacement" from {1, ..., n};
- Construct a correlation coefficient r from the randomized data.
To perform the permutation test, repeat steps (1) and (2) a large number of times. The p-value for the permutation test is the proportion of the r values generated in step (2) that are larger than the Pearson correlation coefficient that was calculated from the original data. Here "larger" can mean either that the value is larger in magnitude, or larger in signed value, depending on whether a two-sided or one-sided test is desired.
Using a bootstrap
The bootstrap can be used to construct confidence intervals for Pearson's correlation coefficient. In the "non-parametric" bootstrap, n pairs (xi, yi) are resampled "with replacement" from the observed set of n pairs, and the correlation coefficient r is calculated based on the resampled data. This process is repeated a large number of times, and the empirical distribution of the resampled r values are used to approximate the sampling distribution of the statistic. A 95% confidence interval for ρ can be defined as the interval spanning from the 2.5th to the 97.5th percentile of the resampled r values.
Testing using Student's t-distribution
For pairs from an uncorrelated bivariate normal distribution, the sampling distribution of a certain function of Pearson's correlation coefficient follows Student's t-distribution with degrees of freedom n − 2. Specifically, if the underlying variables have a bivariate normal distribution, the variable
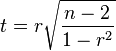
has a Student's t-distribution in the null case (zero correlation).[12] This also holds approximately even if the observed values are non-normal, provided sample sizes are not very small.[13] For determining the critical values for r the inverse of this transformation is also needed:
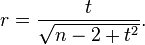
Alternatively, large sample approaches can be used.
Early work on the distribution of the sample correlation coefficient was carried out by Anil Kumar Gain[14] and R. A. Fisher[5][6]
Another early paper[15] provides graphs and tables for general values of ρ, for small sample sizes, and discusses computational approaches.
Using the exact distribution
For data that follows a bivariate normal distribution, the exact density function f(r) for the sample correlation coefficient r of a normal bivariate is[16][17]
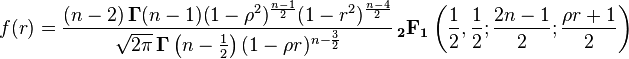
- where:
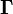 is the gamma function,
is the gamma function, 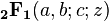 is the Gaussian hypergeometric function.
is the Gaussian hypergeometric function.
In the special case when 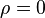 , the exact density function f(r) can be written as:
, the exact density function f(r) can be written as:
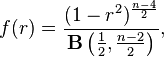
- where:
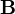 is the beta function, which is one way of writing the density of a Student's t-distribution, as above.
is the beta function, which is one way of writing the density of a Student's t-distribution, as above.
Using the Fisher transformation
In practice, confidence intervals and hypothesis tests relating to ρ are usually carried out using the Fisher transformation:
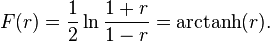
If F(r) is the Fisher transformation of r, and n is the sample size, then F(r) approximately follows a normal distribution with
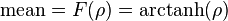 and standard error
and standard error 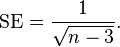
Thus, a z-score is
![z = \frac{x - \text{mean}}{\text{SE}} = [F(r) - F(\rho_0)]\sqrt{n - 3}](../I/m/5086b102091b9494a26d81abd990f935.png)
under the null hypothesis of that 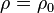 , given the assumption that the sample pairs are independent and identically distributed and follow a bivariate normal distribution. Thus an approximate p-value can be obtained from a normal probability table. For example, if z = 2.2 is observed and a two-sided p-value is desired to test the null hypothesis that
, given the assumption that the sample pairs are independent and identically distributed and follow a bivariate normal distribution. Thus an approximate p-value can be obtained from a normal probability table. For example, if z = 2.2 is observed and a two-sided p-value is desired to test the null hypothesis that  , the p-value is 2·Φ(−2.2) = 0.028, where Φ is the standard normal cumulative distribution function.
, the p-value is 2·Φ(−2.2) = 0.028, where Φ is the standard normal cumulative distribution function.
To obtain a confidence interval for ρ, we first compute a confidence interval for F( ):
):
![100(1 - \alpha)\%\text{CI}: \operatorname{arctanh}(\rho) \in [\operatorname{arctanh}(r) \pm z_{\alpha/2}SE]](../I/m/ec15bc526a318efeb598dca5cf8da339.png)
The inverse Fisher transformation bring the interval back to the correlation scale.
![100(1 - \alpha)\%\text{CI}: \rho \in [\operatorname{tanh}(\operatorname{arctanh}(r) - z_{\alpha/2}SE), \operatorname{tanh}(\operatorname{arctanh}(r) + z_{\alpha/2}SE)]](../I/m/aa96f0c74456720c6c51385d0bf184bb.png)
For example, suppose we observe r = 0.3 with a sample size of n=50, and we wish to obtain a 95% confidence interval for ρ. The transformed value is arctanh(r) = 0.30952, so the confidence interval on the transformed scale is 0.30952 ± 1.96/√47, or (0.023624, 0.595415). Converting back to the correlation scale yields (0.024, 0.534).
Pearson's correlation and least squares regression analysis
The square of the sample correlation coefficient is typically denoted r2 and is a special case of the coefficient of determination. In this case, it estimates the fraction of the variance in Y that is explained by X in a simple linear regression. So if we have the observed dataset {y1,...yn} and the fitted dataset {f1,...fn}, and we denote the fitted dataset {f1,...fn} with {ŷ1,...ŷn}, then as a starting point the total variation in the Yi around their average value can be decomposed as follows
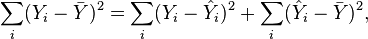
where the 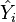 are the fitted values from the regression analysis. This can be rearranged to give
are the fitted values from the regression analysis. This can be rearranged to give
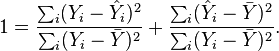
The two summands above are the fraction of variance in Y that is explained by X (right) and that is unexplained by X (left).
Next, we apply a property of least square regression models, that the sample covariance between and  is zero. Thus, the sample correlation coefficient between the observed and fitted response values in the regression can be written
is zero. Thus, the sample correlation coefficient between the observed and fitted response values in the regression can be written
![\begin{align}
r(Y,\hat{Y}) &= \frac{\sum_i(Y_i-\bar{Y})(\hat{Y}_i-\bar{Y})}{\sqrt{\sum_i(Y_i-\bar{Y})^2\cdot \sum_i(\hat{Y}_i-\bar{Y})^2}}\\
&= \frac{\sum_i(Y_i-\hat{Y}_i+\hat{Y}_i-\bar{Y})(\hat{Y}_i-\bar{Y})}{\sqrt{\sum_i(Y_i-\bar{Y})^2\cdot \sum_i(\hat{Y}_i-\bar{Y})^2}}\\
&= \frac{ \sum_i [(Y_i-\hat{Y}_i)(\hat{Y}_i-\bar{Y}) +(\hat{Y}_i-\bar{Y})^2 ]}{\sqrt{\sum_i(Y_i-\bar{Y})^2\cdot \sum_i(\hat{Y}_i-\bar{Y})^2}}\\
&= \frac{ \sum_i (\hat{Y}_i-\bar{Y})^2 }{\sqrt{\sum_i(Y_i-\bar{Y})^2\cdot \sum_i(\hat{Y}_i-\bar{Y})^2}}\\
&= \sqrt{\frac{\sum_i(\hat{Y}_i-\bar{Y})^2}{\sum_i(Y_i-\bar{Y})^2}}.
\end{align}](../I/m/1e4caa31bf0f23d8efec4fb9cafbf980.png)
Thus
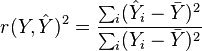
- where
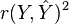 is the proportion of variance in Y explained by a linear function of X.
is the proportion of variance in Y explained by a linear function of X.
- where
That equation can be written as:
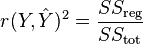
- where
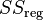 is the regression sum of squares, also called the explained sum of squares
is the regression sum of squares, also called the explained sum of squares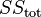 is the total sum of squares (proportional to the variance of the data)
is the total sum of squares (proportional to the variance of the data)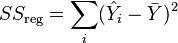
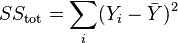
- where
Sensitivity to the data distribution
Existence
The population Pearson correlation coefficient is defined in terms of moments, and therefore exists for any bivariate probability distribution for which the population covariance is defined and the marginal population variances are defined and are non-zero. Some probability distributions such as the Cauchy distribution have undefined variance and hence ρ is not defined if X or Y follows such a distribution. In some practical applications, such as those involving data suspected to follow a heavy-tailed distribution, this is an important consideration. However, the existence of the correlation coefficient is usually not a concern; for instance, if the range of the distribution is bounded, ρ is always defined.
Sample size
- If the sample size is moderate or large and the population is normal then in the case of the bivariate normal distribution, the sample correlation coefficient is the maximum likelihood estimate of the population correlation coefficient, and is asymptotically unbiased and efficient, which roughly means that it is impossible to construct a more accurate estimate than the sample correlation coefficient.
- If the sample size is large and the population is not normal, then the sample correlation coefficient remains approximately unbiased, but may not be efficient.
- If the sample size is large then sample correlation coefficient is a consistent estimator of the population correlation coefficient as long as the sample means, variances, and covariance are consistent (which is guaranteed when the law of large numbers can be applied).
- If the sample size is small then the sample correlation coefficient r is not an unbiased estimate of ρ.[7] The adjusted correlation coefficient must be used instead: see elsewhere in this article for the definition.
Robustness
Like many commonly used statistics, the sample statistic r is not robust,[18] so its value can be misleading if outliers are present.[19][20] Specifically, the PMCC is neither distributionally robust, nor outlier resistant[18] (see Robust statistics#Definition). Inspection of the scatterplot between X and Y will typically reveal a situation where lack of robustness might be an issue, and in such cases it may be advisable to use a robust measure of association. Note however that while most robust estimators of association measure statistical dependence in some way, they are generally not interpretable on the same scale as the Pearson correlation coefficient.
Statistical inference for Pearson's correlation coefficient is sensitive to the data distribution. Exact tests, and asymptotic tests based on the Fisher transformation can be applied if the data are approximately normally distributed, but may be misleading otherwise. In some situations, the bootstrap can be applied to construct confidence intervals, and permutation tests can be applied to carry out hypothesis tests. These non-parametric approaches may give more meaningful results in some situations where bivariate normality does not hold. However the standard versions of these approaches rely on exchangeability of the data, meaning that there is no ordering or grouping of the data pairs being analyzed that might affect the behavior of the correlation estimate.
A stratified analysis is one way to either accommodate a lack of bivariate normality, or to isolate the correlation resulting from one factor while controlling for another. If W represents cluster membership or another factor that it is desirable to control, we can stratify the data based on the value of W, then calculate a correlation coefficient within each stratum. The stratum-level estimates can then be combined to estimate the overall correlation while controlling for W.[21]
Variants
Variations of the correlation coefficient can be calculated for different purposes. Here are some examples.
Adjusted correlation coefficient
The sample correlation coefficient r is not an unbiased estimate of ρ. For data that follows a bivariate normal distribution, the expectation E(r) for the sample correlation coefficient r of a normal bivariate is[22]
![\operatorname{E}\left[r\right] = \rho - \frac{\rho \left(1 - \rho^2\right)}{2n} + \cdots, \quad](../I/m/ed52d183c3a553f429189ad715d624fc.png) therefore r is a biased estimator of
therefore r is a biased estimator of 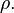
The unique minimum variance unbiased estimator radj is given by[23]
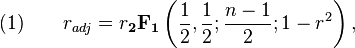 .
.
- where:
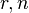 are defined as above,
are defined as above,- is the Gaussian hypergeometric function.
An approximately unbiased estimator radj can be obtained by truncating E[r] and solving this truncated equation:
![(2) \qquad r = \operatorname{E}\left[r\right] = r_{adj} - \frac{r_{adj} \left(1 - r_{adj}^2\right)}{2n}.](../I/m/1923459b69d93c7da8e454c9bc0b3f86.png)
The solution to equation (2) is:
![(3) \qquad r_{adj} = r \left[1 + \frac{1 - r^2}{2n}\right],](../I/m/1944b4110dd33039ab2322988fb282d8.png)
- where in (3):
- are defined as above,
- radj is a suboptimal estimator,
- radj can also be obtained by maximizing log(f(r)),
- radj has minimum variance for large values of n,
- radj has a bias of order 1/(n-1).
Another proposed[7] adjusted correlation coefficient is:
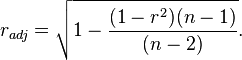
Note that radj ≈ r for large values of n.
Weighted correlation coefficient
Suppose observations to be correlated have differing degrees of importance that can be expressed with a weight vector w. To calculate the correlation between vectors x and y with the weight vector w (all of length n),[24][25]
- Weighted mean:
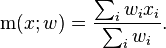
- Weighted covariance
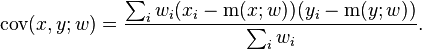
- Weighted correlation
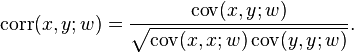
Reflective correlation coefficient
The reflective correlation is a variant of Pearson's correlation in which the data are not centered around their mean values. The population reflective correlation is
![\text{Corr}_r(X,Y) = \frac{E[XY]}{\sqrt{EX^2\cdot EY^2}}.](../I/m/25bb0f867f31f5bfb809beed4a01484a.png)
The reflective correlation is symmetric, but it is not invariant under translation:
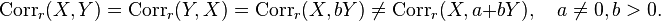
The sample reflective correlation is
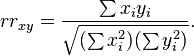
The weighted version of the sample reflective correlation is
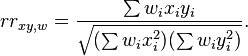
Scaled correlation coefficient
Scaled correlation is a variant of Pearson's correlation in which the range of the data is restricted intentionally and in a controlled manner to reveal correlations between fast components in time series.[26] Scaled correlation is defined as average correlation across short segments of data.
Let 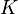 be the number of segments that can fit into the total length of the signal
be the number of segments that can fit into the total length of the signal  for a given scale
for a given scale  :
:
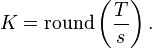
The scaled correlation across the entire signals 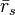 is then computed as
is then computed as
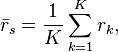
where 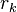 is Pearson's coefficient of correlation for segment
is Pearson's coefficient of correlation for segment  .
.
By choosing the parameter , the range of values is reduced and the correlations on long time scale are filtered out, only the correlations on short time scales being revealed. Thus, the contributions of slow components are removed and those of fast components are retained.
Pearson’s distance
A distance metric for two variables X and Y known as Pearson's distance can be defined from their correlation coefficient as[27]
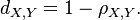
Considering that the Pearson correlation coefficient falls between [−1, 1], the Pearson distance lies in [0, 2].
Heavy noise conditions
Under heavy noise conditions, extracting the correlation coefficient between two sets of stochastic variables is nontrivial, in particular where Canonical Correlation Analysis reports on degraded correlation values due to the heavy noise contributions. A generalization of the approach is given elsewhere.[28]
Missing data
In case of missing data, Garren derived the maximum likelihood estimator.[29]
Removing correlation
It is always possible to remove the correlation between random variables with a linear transformation, even if the relationship between the variables is nonlinear. A presentation of this result for population distributions is given by Cox & Hinkley.[30]
A corresponding result exists for sample correlations, in which the sample correlation is reduced to zero. Suppose a vector of n random variables is sampled m times. Let X be a matrix where 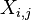 is the jth variable of sample i. Let
is the jth variable of sample i. Let 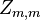 be an m by m square matrix with every element 1. Then D is the data transformed so every random variable has zero mean, and T is the data transformed so all variables have zero mean and zero correlation with all other variables – the sample covariance matrix of T will be the identity matrix. This has to be further divided by the standard deviation to get unit variance. The transformed variables will be uncorrelated, even though they may not be independent.
be an m by m square matrix with every element 1. Then D is the data transformed so every random variable has zero mean, and T is the data transformed so all variables have zero mean and zero correlation with all other variables – the sample covariance matrix of T will be the identity matrix. This has to be further divided by the standard deviation to get unit variance. The transformed variables will be uncorrelated, even though they may not be independent.
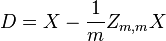
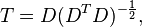
where an exponent of −1/2 represents the matrix square root of the inverse of a matrix. The covariance matrix of T will be the identity matrix. If a new data sample x is a row vector of n elements, then the same transform can be applied to x to get the transformed vectors d and t:
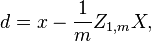
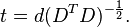
This decorrelation is related to principal components analysis for multivariate data.
See also
- Association (statistics)
- Correlation and dependence
- Disattenuation
- Distance correlation
- Maximal information coefficient
- Multiple correlation
- Normally distributed and uncorrelated does not imply independent
- Partial correlation
- Quadrant count ratio
- RV coefficient
- Spearman's rank correlation coefficient
References
- ↑ See:
- As early as 1877, Galton was using the term "reversion" and the symbol "r" for what would become "regression". F. Galton (5, 12, 19 April 1877) "Typical laws of heredity," Nature, 15 (388, 389, 390) : 492–495 ; 512–514 ; 532–533. In the "Appendix" on page 532, Galton uses the term "reversion" and the symbol r.
- (F. Galton) (24 September 1885), "The British Association: Section II, Anthropology: Opening address by Francis Galton, F.R.S., etc., President of the Anthropological Institute, President of the Section," Nature, 32 (830) : 507–510.
- Galton, F. (1886) "Regression towards mediocrity in hereditary stature," Journal of the Anthropological Institute of Great Britain and Ireland, 15 : 246–263.
- ↑ Karl Pearson (20 June 1895) "Notes on regression and inheritance in the case of two parents," Proceedings of the Royal Society of London, 58 : 240–242.
- ↑ Stigler, Stephen M. (1989). "Francis Galton's Account of the Invention of Correlation". Statistical Science 4 (2): 73–79. doi:10.1214/ss/1177012580. JSTOR 2245329.
- ↑ Gayen, A.K. (1951). "The frequency distribution of the product moment correlation coefficient in random samples of any size draw from non-normal universes". Biometrika 38: 219–247. doi:10.1093/biomet/38.1-2.219.
- 1 2 Fisher, R.A. (1915). "Frequency distribution of the values of the correlation coefficient in samples from an indefinitely large population". Biometrika 10 (4): 507–521. doi:10.1093/biomet/10.4.507.
- 1 2 Fisher, R.A. (1921). "On the probable error of a coefficient of correlation deduced from a small sample" (PDF). Metron 1 (4): 3–32. Retrieved 2009-03-25.
- 1 2 3 4 5 Real Statistics Using Excel: Correlation: Basic Concepts, retrieved 2015-02-22
- ↑ Schmid Jr., John (December 1947). "The Relationship between the Coefficient of Correlation and the Angle Included between Regression Lines". The Journal of Educational Research 41 (4). JSTOR 27528906.
- ↑ Rummel, R. J. (1976). "Understanding Correlation".
- ↑ Buda, Andrzej; Jarynowski, Andrzej (December 2010). Life time of correlations and its applications. Wydawnictwo Niezależne. pp. 5–21. ISBN 9788391527290.
- 1 2 Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.)
- ↑ Rahman, N.A. (1968) A Course in Theoretical Statistics, Charles Griffin and Company, 1968
- ↑ Kendall, M.G., Stuart, A. (1973) The Advanced Theory of Statistics, Volume 2: Inference and Relationship, Griffin. ISBN 0-85264-215-6 (Section 31.19)
- ↑ Gain, A.K. (1951). "The frequency distribution of the product moment correlation coefficient in random samples of any size draw from non-normal universes". Biometrika 38: 219–247. doi:10.1093/biomet/38.1-2.219.
- ↑ Soper, H.E.; Young, A.W.; Cave, B.M.; Lee, A.; Pearson, K. (1917). "On the distribution of the correlation coefficient in small samples. Appendix II to the papers of "Student" and R. A. Fisher. A co-operative study". Biometrika 11: 328–413. doi:10.1093/biomet/11.4.328.
- ↑ Kenney, J. F. and Keeping, E. S., Mathematics of Statistics, Pt. 2, 2nd ed. Princeton, NJ: Van Nostrand, 1951.
- ↑ Correlation Coefficient – Bivariate Normal Distribution
- 1 2 Wilcox, Rand R. (2005). Introduction to robust estimation and hypothesis testing. Academic Press.
- ↑ Devlin, Susan J; Gnanadesikan, R; Kettenring J.R. (1975). "Robust Estimation and Outlier Detection with Correlation Coefficients". Biometrika 62 (3): 531–545. doi:10.1093/biomet/62.3.531. JSTOR 2335508.
- ↑ Huber, Peter. J. (2004). Robust Statistics. Wiley.
- ↑ Katz., Mitchell H. (2006) Multivariable Analysis – A Practical Guide for Clinicians. 2nd Edition. Cambridge University Press. ISBN 978-0-521-54985-1. ISBN 0-521-54985-X doi:10.2277/052154985X
- ↑ Hotelling, H. (1953). "New Light on the Correlation Coefficient and its Transforms". Journal of the Royal Statistical Society. Series B (Methodological) 15 (2): 193–232. JSTOR 2983768.
- ↑ Olkin, Ingram; Pratt,John W. (March 1958). "Unbiased Estimation of Certain Correlation Coefficients". The Annals of Mathematical Statistics 29 (1): 201–211. doi:10.1214/aoms/1177706717. JSTOR 2237306..
- ↑ http://sci.tech-archive.net/Archive/sci.stat.math/2006-02/msg00171.html
- ↑ A MATLAB Toolbox for computing Weighted Correlation Coefficients
- ↑ Nikolić, D; Muresan, RC; Feng, W; Singer, W (2012). "Scaled correlation analysis: a better way to compute a cross-correlogram" (PDF). European Journal of Neuroscience: 1–21. doi:10.1111/j.1460-9568.2011.07987.x.
- ↑ Fulekar (Ed.), M.H. (2009) Bioinformatics: Applications in Life and Environmental Sciences, Springer (pp. 110) ISBN 1-4020-8879-5
- ↑ Moriya, N. (2008). Fengshan Yang, ed. "Noise-Related Multivariate Optimal Joint-Analysis in Longitudinal Stochastic Processes". Nova Science Publishers, Inc.: 223–260. ISBN 978-1-60021-976-4.
- ↑ Garren, Steven T (15 June 1998). "Maximum likelihood estimation of the correlation coefficient in a bivariate normal model with missing data". Statistics & Probability Letters (Elsevier) 38 (3): 281–288. doi:10.1016/S0167-7152(98)00035-2. Retrieved 5 December 2015.
- ↑ Cox, D.R., Hinkley, D.V. (1974) Theoretical Statistics, Chapman & Hall (Appendix 3) ISBN 0-412-12420-3
External links
| Wikiversity has learning materials about Linear correlation |
- cocor - A free web interface and R package for the statistical comparison of two dependent or independent correlations with overlapping or non-overlapping variables
- Interactive Flash simulation on the correlation of two normally distributed variables.
- Correlation coefficient calculator – linear regression
- Critical values for Pearson's correlation coefficient (large table) PDF
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||