Probabilistic relevance model
The probabilistic relevance model[1] was devised by Robertson and Jones as a framework for probabilistic models to come.
It makes an estimation of the probability of finding if a document dj is relevant to a query q. This model assumes that this probability of relevance depends on the query and document representations. Furthermore, it assumes that there is a portion of all documents that is preferred by the user as the answer set for query q. Such an ideal answer set is called R and should maximize the overall probability of relevance to that user. The prediction is that documents in this set R are relevant to the query, while documents not present in the set are non-relevant.
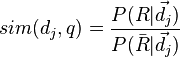
Related models
There are some limitations to this framework that need to be addressed by further development:
- There is no accurate estimate for the first run probabilities
- Index terms are not weighted
- Terms are assumed mutually independent
To address these and other concerns there are some developed models from the probabilistic relevance framework. The Binary Independence Model for one, as it is from the same author. The most known derivative of this framework is the Okapi(BM25) weighting scheme and its BM25F brother.
References
- ↑ S. E. Robertson; K. S. Jones (May–June 1976), Relevance weighting of search terms, Journal of the American Society for Information Science, pp. 129–146 Cite uses deprecated parameter
|coauthors=(help)