Power iteration
In mathematics, the power iteration is an eigenvalue algorithm: given a matrix A, the algorithm will produce a number λ (the eigenvalue) and a nonzero vector v (the eigenvector), such that Av = λv. The algorithm is also known as the Von Mises iteration.[1]
The power iteration is a very simple algorithm. It does not compute a matrix decomposition, and hence it can be used when A is a very large sparse matrix. However, it will find only one eigenvalue (the one with the greatest absolute value) and it may converge only slowly.
The method
The power iteration algorithm starts with a vector b0, which may be an approximation to the dominant eigenvector or a random vector. The method is described by the recurrence relation
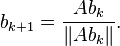
So, at every iteration, the vector bk is multiplied by the matrix A and normalized.
If we assume A has an eigenvalue that is strictly greater in magnitude than its other eigenvalues and the starting vector  has a nonzero component in the direction of an eigenvector associated with the dominant eigenvalue, then a subsequence
has a nonzero component in the direction of an eigenvector associated with the dominant eigenvalue, then a subsequence 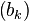 converges to an eigenvector associated with the dominant eigenvalue.
converges to an eigenvector associated with the dominant eigenvalue.
Without the two assumptions above, the sequence does not necessarily converge. In this sequence,
-
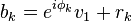 ,
,
where  is an eigenvector associated with the dominant eigenvalue, and
is an eigenvector associated with the dominant eigenvalue, and  . The presence of the term
. The presence of the term 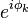 implies that does not converge unless
implies that does not converge unless 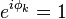 . Under the two assumptions listed above, the sequence
. Under the two assumptions listed above, the sequence 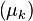 defined by
defined by
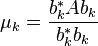
converges to the dominant eigenvalue.
This can be run as a simulation program with the following simple algorithm:
for each(''simulation'') {
// calculate the matrix-by-vector product Ab
for(i=0; i<n; i++) {
tmp[i] = 0;
for (j=0; j<n; j++)
tmp[i] += A[i][j] * b[j];
// dot product of i-th row in A with the column vector b
}
// calculate the length of the resultant vector
norm_sq=0;
for (k=0; k<n; k++)
norm_sq += tmp[k]*tmp[k];
norm = sqrt(norm_sq);
// normalize b to unit vector for next iteration
b = tmp/norm;
}
The value of norm converges to the absolute value of the dominant eigenvalue, and the vector b to an associated eigenvector.
Note: The above code assumes real A,b. To handle complex; A[i][j] becomes conj(A[i][j]), and tmp[k]*tmp[k] becomes conj(tmp[k])*tmp[k]
This algorithm is the one used to calculate such things as the Google PageRank.
The method can also be used to calculate the spectral radius (the largest eigenvalue) of a matrix by computing the Rayleigh quotient

Analysis
Let 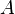 be decomposed into its Jordan canonical form:
be decomposed into its Jordan canonical form: 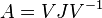 ,
where the first column of
,
where the first column of 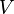 is an eigenvector of corresponding to the dominant eigenvalue
is an eigenvector of corresponding to the dominant eigenvalue  .
Since the dominant eigenvalue of is unique,
the first Jordan block of
.
Since the dominant eigenvalue of is unique,
the first Jordan block of 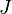 is the
is the  matrix
matrix
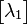 , where
is the largest eigenvalue of A in magnitude.
The starting vector
, where
is the largest eigenvalue of A in magnitude.
The starting vector 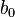 can be written as a linear combination of the columns of V:
can be written as a linear combination of the columns of V:
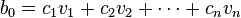 .
By assumption, has a nonzero component in the direction of the dominant eigenvalue, so
.
By assumption, has a nonzero component in the direction of the dominant eigenvalue, so
 .
.
The computationally useful recurrence relation for 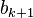 can be rewritten as:
can be rewritten as:
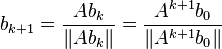 ,
where the expression:
,
where the expression: 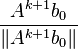 is more amenable to the following analysis.
is more amenable to the following analysis.
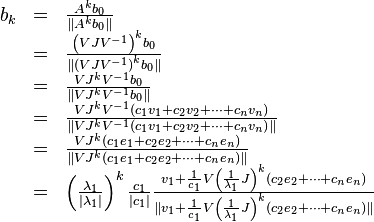
The expression above simplifies as 
![\left( \frac{1}{\lambda_{1}} J \right)^{k} =
\begin{bmatrix}
[1] & & & & \\
& \left( \frac{1}{\lambda_{1}} J_{2} \right)^{k}& & & \\
& & \ddots & \\
& & & \left( \frac{1}{\lambda_{1}} J_{m} \right)^{k} \\
\end{bmatrix}
\rightarrow
\begin{bmatrix}
1 & & & & \\
& 0 & & & \\
& & \ddots & \\
& & & 0 \\
\end{bmatrix}](../I/m/7ff0d89f21187cb5c70de9847f25f6db.png) as
.
as
.
The limit follows from the fact that the eigenvalue of
 is less than 1 in magnitude, so
is less than 1 in magnitude, so
 as
as
It follows that:
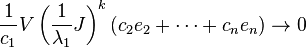 as
as
Using this fact,
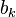 can be written in a form that emphasizes its relationship with
can be written in a form that emphasizes its relationship with 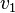 when k is large:
when k is large:
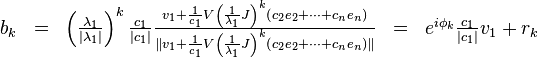 where
where 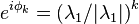 and
as
and
as
The sequence
is bounded, so it contains a convergent subsequence. Note that the eigenvector corresponding to the dominant eigenvalue is only unique up to a scalar, so although the sequence may not converge,
is nearly an eigenvector of A for large k.
Alternatively, if A is diagonalizable, then the following proof yields the same result
Let λ1, λ2, …, λm be the m eigenvalues (counted with multiplicity) of A and let v1, v2, …, vm be the corresponding eigenvectors. Suppose that  is the dominant eigenvalue, so that
is the dominant eigenvalue, so that 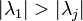 for
for 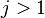 .
.
The initial vector can be written:
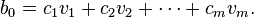
If is chosen randomly (with uniform probability), then c1 ≠ 0 with probability 1. Now,
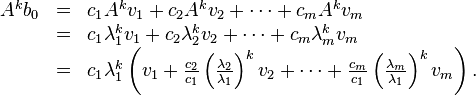
The expression within parentheses converges to because  for . On the other hand, we have
for . On the other hand, we have
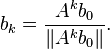
Therefore, 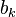 converges to (a multiple of) the eigenvector . The convergence is geometric, with ratio
converges to (a multiple of) the eigenvector . The convergence is geometric, with ratio
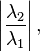
where  denotes the second dominant eigenvalue. Thus, the method converges slowly if there is an eigenvalue close in magnitude to the dominant eigenvalue.
denotes the second dominant eigenvalue. Thus, the method converges slowly if there is an eigenvalue close in magnitude to the dominant eigenvalue.
Applications
Although the power iteration method approximates only one eigenvalue of a matrix, it remains useful for certain computational problems. For instance, Google uses it to calculate the PageRank of documents in their search engine,[2] and Twitter uses it to show users recommendations of who to follow.[3] For matrices that are well-conditioned and as sparse as the Web matrix, the power iteration method can be more efficient than other methods of finding the dominant eigenvector.
Some of the more advanced eigenvalue algorithms can be understood as variations of the power iteration. For instance, the inverse iteration method applies power iteration to the matrix  . Other algorithms look at the whole subspace generated by the vectors . This subspace is known as the Krylov subspace. It can be computed by Arnoldi iteration or Lanczos iteration.
Another variation of the power method that simultaneously gives n eigenvalues and eigenfunctions,
as well as accelerated convergence as
. Other algorithms look at the whole subspace generated by the vectors . This subspace is known as the Krylov subspace. It can be computed by Arnoldi iteration or Lanczos iteration.
Another variation of the power method that simultaneously gives n eigenvalues and eigenfunctions,
as well as accelerated convergence as 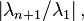 is
"Multiple extremal eigenpairs by the power method"
in the Journal of Computational Physics
Volume 227 Issue 19, October, 2008,
Pages 8508-8522 (Also see pdf below for Los Alamos National Laboratory report LA-UR-07-4046)
is
"Multiple extremal eigenpairs by the power method"
in the Journal of Computational Physics
Volume 227 Issue 19, October, 2008,
Pages 8508-8522 (Also see pdf below for Los Alamos National Laboratory report LA-UR-07-4046)
See also
References
- ↑ Richard von Mises and H. Pollaczek-Geiringer, Praktische Verfahren der Gleichungsauflösung, ZAMM - Zeitschrift für Angewandte Mathematik und Mechanik 9, 152-164 (1929).
- ↑ Ipsen, Ilse, and Rebecca M. Wills (5–8 May 2005). "7th IMACS International Symposium on Iterative Methods in Scientific Computing" (PDF). Fields Institute, Toronto, Canada.
- ↑ Pankaj Gupta, Ashish Goel, Jimmy Lin, Aneesh Sharma, Dong Wang, and Reza Bosagh Zadeh WTF: The who-to-follow system at Twitter, Proceedings of the 22nd international conference on World Wide Web
External links
- Power method, part of lecture notes on numerical linear algebra by E. Bruce Pitman, State University of New York.
- Module for the Power Method
- Los Alamos report LA-UR-07-4046 ""Multiple extremal eigenpairs by the power method"
| ||||||||||||||||||