Post hoc analysis
In the design and analysis of experiments, post hoc analysis (from Latin post hoc, "after this") consists of looking at the data—after the experiment has concluded—for patterns that were not specified a priori. It is sometimes called by critics data dredging to evoke the sense that the more one looks the more likely something will be found. More subtly, each time a pattern in the data is considered, a statistical test is effectively performed. This greatly inflates the total number of statistical tests and necessitates the use of multiple testing procedures to compensate. However, this is difficult to do precisely and in fact most results of post hoc analyses are reported as they are with unadjusted p-values. These p-values must be interpreted in light of the fact that they are a small and selected subset of a potentially large group of p-values. Results of post hoc analyses should be explicitly labeled as such in reports and publications to avoid misleading readers.
In practice, post hoc analyses are usually concerned with finding patterns and/or relationships between subgroups of sampled populations that would otherwise remain undetected and undiscovered were a scientific community to rely strictly upon a priori statistical methods. Post hoc tests—also known as a posteriori tests—greatly expand the range and capability of methods that can be applied in exploratory research. Post hoc examination strengthens induction by limiting the probability that significant effects will seem to have been discovered between subgroups of a population when none actually exist. As it is, many scientific papers are published without adequate, preventative post hoc control of the type I error rate.[1]
Post hoc analysis is an important procedure without which multivariate hypothesis testing would greatly suffer, rendering the chances of discovering false positives unacceptably high. Ultimately, post hoc testing creates better informed scientists who can therefore formulate better, more efficient a priori hypotheses and research designs.
Relationship with the multiple comparisons problem
In its most literal and narrow sense, post hoc analysis simply refers to unplanned data analysis performed after the data is collected in order to reach further conclusions. In this sense, even a test that does not provide Type I Error Rate[1] protection, using multiple comparisons methods, is considered as post hoc analysis. A good example is performing initially unplanned multiple t-tests at level 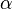 , following an level anova test. Such post hoc analysis does not include multiple testing procedures, which are sometimes difficult to perform precisely. Unfortunately, analyses such as the above are still commonly conducted and their results reported with unadjusted p-values. Results of post hoc analyses which do not address the multiple comparisons problem should be explicitly labeled as such to avoid misleading readers.
, following an level anova test. Such post hoc analysis does not include multiple testing procedures, which are sometimes difficult to perform precisely. Unfortunately, analyses such as the above are still commonly conducted and their results reported with unadjusted p-values. Results of post hoc analyses which do not address the multiple comparisons problem should be explicitly labeled as such to avoid misleading readers.
In the wider and more useful sense, post hoc analysis tests enable protection from the multiple comparisons problem, whether the inferences made are selective or simultaneous. The type of inference is related directly to the hypotheses family of interest. Simultaneous inference indicates that all inferences, in the family of all hypotheses, are jointly corrected up to a specified type I error rate. In practice, post hoc analyses are usually concerned with finding patterns and/or relationships between subgroups of sampled populations that would otherwise remain undetected and undiscovered were a scientific community to rely strictly upon a priori statistical methods . Therefore, simultaneous inference may be too conservative for certain large scale problems that are currently being addressed by science. For such problems, a selective inference approach might be more suitable, since it assumes that sub-groups of hypotheses from the large scale group can be viewed as a family. Selective post hoc examination strengthens induction by limiting the probability that significant differences will seem to have been discovered between sub-groups of a population when none actually exist. Accordingly, p-values of such sub-groups must be interpreted in light of the fact that they are a small and selected subset of a potentially large group of p-values.
List of post hoc tests
The following are referred to as "post hoc tests". However, on some occasions a researcher may have initially planned on using them, thus referring to them as "post-hoc tests" is not entirely accurate. For instance, The Newman–Keuls and Tukey's methods are often referred to as post hoc. However, it is not uncommon to plan on testing all pairwise comparisons before seeing the data. Therefore, in such cases, these tests are better categorized as a priori.
Fisher's least significant difference (LSD)[2]
This technique was developed by Ronald Fisher in 1935 and is used most commonly after a null hypothesis in an analysis of variance (ANOVA) test is rejected (assuming normality and homogeneity of variances). A significant ANOVA test only reveals that not all the means compared in the test are equal. Fisher's LSD is basically a set of individual t-tests, differentiated only in the calculation of the standard deviation. In each t-test, a pooled standard deviation is computed from only the two groups being compared, while the Fisher's LSD test computes the pooled standard deviation from all groups - thus increasing power. Fisher's LSD does not correct for multiple comparisons.
The Bonferroni procedure
- Denote by
 the p-value for testing
the p-value for testing 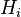
- reject if
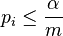
-
 being the number of hypotheses
being the number of hypotheses
Although mainly used with planned contrasts, it can be used as a post hoc test for comparisons between data groups of interest in the experiment after the fact. It is flexible and very simple to compute, but naive in its idea of retaining of familywise error rate by division by . This method results in a large reduction in the power of the test. That is, because the cut-off value is reduced, it becomes substantially more difficult for any result to be concluded as being statistically significant, irrespective of whether it is true or not.
Holm–Bonferroni method
- Start by ordering the p-values
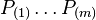 and let the associated hypotheses be
and let the associated hypotheses be 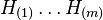
- Let
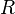 be the smallest
be the smallest  such that
such that 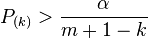
- Reject the null hypotheses
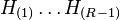 . If
. If 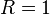 then none of the hypotheses are rejected.
then none of the hypotheses are rejected.
- This procedure is uniformly better than Bonferroni's.
- It is worth noticing here that the reason why this procedure controls the family-wise error rate for all the m hypotheses at level α in the strong sense is because it is essentially a closed testing procedure. As such, each intersection is tested using the simple Bonferroni test.
The Bonferroni-Holm method introduces a correction to Bonferroni's method that allows more rejections, and is therefore less conservative and more powerful than the Bonferroni method.
Newman–Keuls method
A stepwise multiple comparisons procedure used to identify sample means that are significantly different from each other. It is used often as a post hoc test whenever a significant difference between three or more sample means has been revealed by an analysis of variance (ANOVA)
Duncan's new multiple range test (MRT)
Duncan developed this test as a modification of the Newman–Keuls method that would have greater power. Duncan's MRT is especially protective against false negative (Type II) error at the expense of having a greater risk of making false positive (Type I) errors.
Rodger's method
Rodger's method is a procedure for examining research data post hoc following an 'omnibus' analysis, that is after carrying out an analysis of variance (ANOVA). Rodger's method utilizes a decision-based error rate, arguing that it is not the probability ( ) of rejecting
) of rejecting 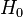 in error that should be controlled, rather it is the average rate of rejecting true null contrasts that should be controlled. Meaning we should control the expected rate (
in error that should be controlled, rather it is the average rate of rejecting true null contrasts that should be controlled. Meaning we should control the expected rate (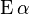 ) of true null contrast rejection.
) of true null contrast rejection.
Scheffé's method
Scheffé's method applies to the set of estimates of all possible contrasts among the factor level means, not just the pairwise differences. Having an advantage of flexibility, it can be used to test any number of post hoc simple and/or complex comparisons that appear interesting. However, the drawback of this flexibility is a low type I error rate, and a low power.
Tukey's procedure
- Tukey's procedure is only applicable for pairwise comparisons.
- It assumes independence of the observations being tested, as well as equal variation across observations (homoscedasticity).
- The procedure calculates for each pair the studentized range statistic:
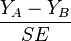 where
where 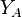 is the larger of the two means being compared,
is the larger of the two means being compared, 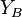 is the smaller, and
is the smaller, and 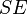 is the standard error of the data in question.
is the standard error of the data in question. - Tukey's test is essentially a Student's t-test, except that it corrects for family-wise error-rate.
A correction with a similar framework is Fisher’s LSD (least significant difference).
Dunnett's correction
Charles Dunnett (1955, 1966; not to be confused with Dunn) described an alternative alpha error adjustment when k groups are compared to the same control group. Now known as Dunnett's test, this method is less conservative than the Bonferroni adjustment.
Sidák's inequality
Benjamini–Hochberg (BH) procedure
BH-procedure is a step-up procedure iterating over 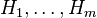 null hypotheses tested and
null hypotheses tested and
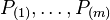 , their ordered p-values in an increasing order. The method then proceeds to identify the rejected null hypotheses from the above set, whilst controlling the false discovery rate (at level ) under the premise that the total hypotheses are independent or positively correlated.
, their ordered p-values in an increasing order. The method then proceeds to identify the rejected null hypotheses from the above set, whilst controlling the false discovery rate (at level ) under the premise that the total hypotheses are independent or positively correlated.
See also
- ANOVA
- Multiple comparisons
- The significance level α (alpha) in statistical hypothesis testing
- Subgroup analysis
- Testing hypotheses suggested by the data
References
- 1 2 Jaccard, J.; Becker, M. A.; Wood, G. (1984). "Pairwise multiple comparison procedures: A review". Psychological Bulletin 96 (3): 589. doi:10.1037/0033-2909.96.3.589.
- ↑ Hayter, A. J. (1986). "The Maximum Familywise Error Rate of Fisher's Least Significant Difference Test". Journal of the American Statistical Association 81 (396): 1000–1004. doi:10.2307/2289074.
Bibliography
- James E. Carlson and Others (1975). "The Distribution of the Test Statistic Used in the Newman–Keuls Multiple Comparison Technique", Annual Meeting of the American Educational Research Association (Washington, D. C., March 30–April 3, 1975)
- Klockars, A. J.; Hancock, G. R. (2000). "Scheffé's More Powerful F-Protected Post Hoc Procedure". Journal of Educational and Behavioral Statistics 25 (1): 13–19. doi:10.2307/1165310.