Polytomous Rasch model
The polytomous Rasch model is generalization of the dichotomous Rasch model. It is a measurement model that has potential application in any context in which the objective is to measure a trait or ability through a process in which responses to items are scored with successive integers. For example, the model is applicable to the use of Likert scales, rating scales, and to educational assessment items for which successively higher integer scores are intended to indicate increasing levels of competence or attainment.
Background and overview
The polytomous Rasch model was derived by Andrich (1978), subsequent to derivations by Rasch (1961) and Andersen (1977), through resolution of relevant terms of a general form of Rasch’s model into threshold and discrimination parameters. When the model was derived, Andrich focused on the use of Likert scales in psychometrics, both for illustrative purposes and to aid in the interpretation of the model.
The model is sometimes referred to as the Rating Scale Model when (i) items have the same number of thresholds and (ii) in turn, the difference between any given threshold location and the mean of the threshold locations is equal or uniform across items. This is, however, a potentially misleading name for the model because it is far more general in its application than to so-called rating scales. The model is also sometimes referred to as the Partial Credit Model, particularly when applied in educational contexts. The Partial Credit Model (Masters, 1982) has an identical mathematical structure but was derived from a different starting point at a later time, and is expressed in a somewhat different form. The Partial Credit Model also allows different thresholds for different items. Although this name for the model is often used, Andrich (2005) provides a detailed analysis of problems associated with elements of Masters' approach, which relate specifically to the type of response process that is compatible with the model, and to empirical situations in which estimates of threshold locations are disordered. These issues are discussed in the elaboration of the model that follows.
The model is a general probabilistic measurement model which provides a theoretical foundation for the use of sequential integer scores, in a manner that preserves the distinctive property that defines Rasch models: specifically, total raw scores are sufficient statistics for the parameters of the models. See the main article for the Rasch model for elaboration of this property. In addition to preserving this property, the model permits a stringent empirical test of the hypothesis that response categories represent increasing levels of a latent attribute or trait, hence are ordered. The reason the model provides a basis for testing this hypothesis is that it is empirically possible that thresholds will fail to display their intended ordering.
In this more general form of the Rasch model for dichotomous data, the score on a particular item is defined as the count of the number of threshold locations on the latent trait surpassed by the individual. It should be noted, however, that this does not mean that a measurement process entails making such counts in a literal sense; rather, threshold locations on a latent continuum are usually inferred from a matrix of response data through an estimation process such as Conditional Maximum likelihood estimation. In general, the central feature of the measurement process is that individuals are classified into one of a set of contiguous, or adjoining, ordered categories. A response format employed in a given experimental context may achieve this in a number of ways. For example, respondents may choose a category they perceive best captures their level of endorsement of a statement (such as 'strongly agree'), judges may classify persons into categories based on well-defined criteria, or a person may categorise a physical stimulus based on perceived similarity to a set of reference stimuli.
The polytomous Rasch model specialises to the model for dichotomous data when responses are classifiable into only two categories. In this special case, the item difficulty and (single) threshold are identical. The concept of a threshold is elaborated on in the following section.
The Partial Credit Model
First, let
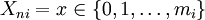
be an integer random variable where 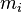 is the maximum score for item i. That is, the variable
is the maximum score for item i. That is, the variable 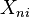 is a random variable that can take on integer values between 0 and a maximum of .
is a random variable that can take on integer values between 0 and a maximum of .
In the polytomous Rasch "Partial Credit" model (Masters, 1982), the probability of the outcome 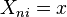 is
is
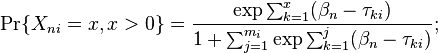
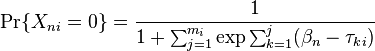
where 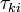 is the kth threshold location of item i on a latent continuum,
is the kth threshold location of item i on a latent continuum,  is the location of person n on the same continuum, and is the maximum score for item i. These equations are the same as
is the location of person n on the same continuum, and is the maximum score for item i. These equations are the same as
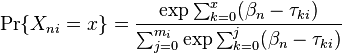
where the value of 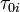 is chosen for computational convenience that is:
is chosen for computational convenience that is: 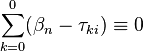 .
.
The Rating Scale Model
Similarly, the Rasch "Rating Scale" model (Andrich, 1978) is
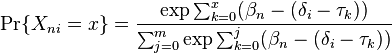
where 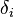 is the difficulty of item i and
is the difficulty of item i and 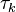 is the kth threshold location of the rating scale which is in common to all the items. m is the maximum score and is identical for all the items.
is the kth threshold location of the rating scale which is in common to all the items. m is the maximum score and is identical for all the items. 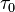 is chosen for computational convenience.
is chosen for computational convenience.
Application
Applied in a given empirical context, the model can be considered a mathematical hypothesis that the probability of a given outcome is a probabilistic function of these person and item parameters. The graph showing the relation between the probability of a given category as a function of person location is referred to as a Category Probability Curve (CPC). An example of the CPCs for an item with five categories, scored from 0 to 4, is shown in Figure 1.
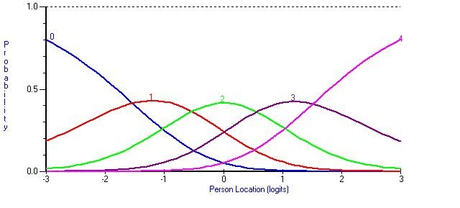
A given threshold partitions the continuum into regions above and below its location. The threshold corresponds with the location on a latent continuum at which it is equally likely a person will be classified into adjacent categories, and therefore to obtain one of two successive scores. The first threshold of item i, 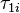 , is the location on the continuum at which a person is equally likely to obtain a score of 0 or 1, the second threshold is the location at which a person is equally likely to obtain a score of 1 and 2, and so on. In the example shown in Figure 1, the threshold locations are −1.5, −0.5, 0.5, and 1.5 respectively.
, is the location on the continuum at which a person is equally likely to obtain a score of 0 or 1, the second threshold is the location at which a person is equally likely to obtain a score of 1 and 2, and so on. In the example shown in Figure 1, the threshold locations are −1.5, −0.5, 0.5, and 1.5 respectively.
Respondents may obtain scores in many different ways. For example, where Likert response formats are employed, Strongly Disagree may be assigned 0, Disagree a 1, Agree a 2, and Strongly Agree a 3. In the context of assessment in educational psychology, successively higher integer scores may be awarded according to explicit criteria or descriptions which characterise increasing levels of attainment in a specific domain, such as reading comprehension. The common and central feature is that some process must result in classification of each individual into one of a set of ordered categories that collectively comprise an assessment item.
Elaboration of the model
In elaborating on features of the model, Andrich (2005) clarifies that its structure entails a simultaneous classification process, which results in a single manifest response, and involves a series of dichotomous latent responses. In addition, the latent dichotomous responses operate within a Guttman structure and associated response space, as is characterised to follow.
Let
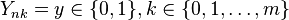
be a set of independent dichotomous random variables. Andrich (1978, 2005) shows that the polytomous Rasch model requires that these dichotomous responses conform with a latent Guttman response subspace:
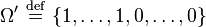
in which x ones are followed by m-x zeros. For example, in the case of two thresholds, the permissible patterns in this response subspace are:
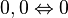
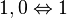
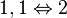
where the integer score x implied by each pattern (and vice versa) is as shown. The reason this subspace is implied by the model is as follows. Let
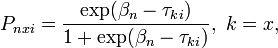
be the probability that 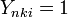 and let
and let 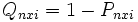 . This function has the structure of the Rasch model for dichotomous data. Next, consider the following conditional probability in the case two thresholds:
. This function has the structure of the Rasch model for dichotomous data. Next, consider the following conditional probability in the case two thresholds:
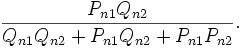
It can be shown that this conditional probability is equal to
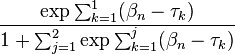
which, in turn, is the probability 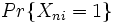 given by the polytomous Rasch model. From the denominator of these equations, it can be seen that the probability in this example is conditional on response patterns of
given by the polytomous Rasch model. From the denominator of these equations, it can be seen that the probability in this example is conditional on response patterns of 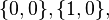 or
or 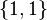 . It is therefore evident that in general, the response subspace
. It is therefore evident that in general, the response subspace 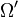 , as defined earlier, is intrinsic to the structure of the polytomous Rasch model. This restriction on the subspace is necessary to the justification for integer scoring of responses: i.e. such that the score is simply the count of ordered thresholds surpassed. Andrich (1978) showed that equal discrimination at each of the thresholds is also necessary to this justification.
, as defined earlier, is intrinsic to the structure of the polytomous Rasch model. This restriction on the subspace is necessary to the justification for integer scoring of responses: i.e. such that the score is simply the count of ordered thresholds surpassed. Andrich (1978) showed that equal discrimination at each of the thresholds is also necessary to this justification.
In the polytomous Rasch model, a score of x on a given item implies that an individual has simultaneously surpassed x thresholds below a certain region on the continuum, and failed to surpass the remaining m − x thresholds above that region. In order for this to be possible, the thresholds must be in their natural order, as shown in the example of Figure 1. Disordered threshold estimates indicate a failure to construct an assessment context in which classifications represented by successive scores reflect increasing levels of the latent trait. For example, consider a situation in which there are two thresholds, and in which the estimate of the second threshold is lower on the continuum than the estimate of the first threshold. If the locations are taken literally, classification of a person into category 1 implies that the person's location simultaneously surpasses the second threshold but fails to surpass the first threshold. In turn, this implies a response pattern {0,1}, a pattern which does not belong to the subspace of patterns that is intrinsic to the structure of the model, as described above.
When threshold estimates are disordered, the estimates cannot therefore be taken literally; rather the disordering, in itself, inherently indicates that the classifications do not satisfy criteria that must logically be satisfied in order to justify the use of successive integer scores as a basis for measurement. To emphasise this point, Andrich (2005) uses an example in which grades of fail, pass, credit, and distinction are awarded. These grades, or classifications, are usually intended to represent increasing levels of attainment. Consider a person A, whose location on the latent continuum is at the threshold between regions on the continuum at which a pass and credit are most likely to be awarded. Consider also another person B, whose location is at the threshold between the regions at which a credit and distinction are most likely to be awarded. In the example considered by Andrich (2005, p. 25), disordered thresholds would, if taken literally, imply that the location of person A (at the pass/credit threshold) is higher than that of person B (at the credit/distinction threshold). That is, taken literally, the disordered threshold locations would imply that a person would need to demonstrate a higher level of attainment to be at the pass/credit threshold than would be needed to be at the credit/distinction threshold. Clearly, this disagrees with the intent of such a grading system. The disordering of the thresholds would, therefore, indicate that the manner in which grades are being awarded is not in agreement with the intention of the grading system. That is, the disordering would indicate that the hypothesis implicit in the grading system - that grades represent ordered classifications of increasing performance - is not substantiated by the structure of the empirical data.
References
- Andersen, E.B. (1977). Sufficient statistics and latent trait models, Psychometrika, 42, 69-81.
- Andrich, D. (1978). A rating formulation for ordered response categories. Psychometrika, 43, 561-73.
- Andrich, D. (2005). The Rasch model explained. In Sivakumar Alagumalai, David D Durtis, and Njora Hungi (Eds.) Applied Rasch Measurement: A book of exemplars. Springer-Kluwer. Chapter 3, 308-328.
- Masters, G.N. (1982). A Rasch model for partial credit scoring. Psychometrika, 47, 149-174.
- Rasch, G. (1960/1980). Probabilistic models for some intelligence and attainment tests. (Copenhagen, Danish Institute for Educational Research), expanded edition (1980) with foreword and afterword by B.D. Wright. Chicago: The University of Chicago Press.
- Wright, B.D. & Masters, G.N. (1982). Rating Scale Analysis. Chicago: MESA Press. (Available from the Institute for Objective Measurement.)
External links
- Disordered thresholds and item information
- Category Disordering and Threshold Disordering
- Andrich on disordered thresholds and 'steps'
- Directory of Rasch Software - freeware and paid
- Institute for Objective Measurement
- Rasch analysis
- Rasch Model in Stata